Exporting pages from Hits?
-
This post is deleted! -
@guy038 said in Exporting pages from Hits?:
Hi, @rjm5959, @alan-kilborn, @peterjones, @coises and All,
I must apologize to @coises ! My reasoning about the necessity or not to use an atomic group was completely erroneous :-(( Indeed, I would have been right if the regex would have been :
\x0C[^\x0C]+(?=\x0C)But, the @coises regex is slightly different :
\x0C[^~\x0C]+(?=\x0C)And because the
~character belongs to the negative class character[^.......]too, the fact of using an atomic group or not, for the pages containing the~character, is quite significant ! Indeed :-
The normal regex
\x0C[^~\x0C]+(?=\x0C)would force the regex engine, as soon as a~is found, to backtrack, one char at a time, up to the first character of a page, after\x0C, in all the lines which contain the~character. Then, as the next character is obviously not\x0C, the regex would skip and search for a next\x0Cchar, further on, followed with some standard characters -
Due to the atomic structure, the enhanced regex
\x0C[^~\x0C]++(?=\x0C)would fail right after getting the~character and would force immediately the regex engine to give up the current search and, search, further on, for an other\x0Ccharacter, followed with some standard chars !
Do note that, if the
~character is near the beginning of each page\x0C, you cannot notice any difference !I did verify that using an atomic group reduce the execution time, for huge files ! With a
30 Mofile, containing159,000lines, whose1,325contains the~char, located4,780chars about after the beginning of each page, the difference, in execution, was already about1.5s!!As a conclusion, @rjm5959, the initial @coises’s regex
\x0C[^~\x0C]++(?=\x0C)is the regex to use with files of important size ;-))BR
guy038
Thanks Guy038. I will give this a try. The file I have is 7.7 million lines and the page hits will be 89,984 for nationstar. Each page is 57 lines so that’s about 5.1 million lines. Will this work with that much data?
-
-
This post is deleted! -
@guy038 said in Exporting pages from Hits?:
Hi, @rjm5959, @alan-kilborn, @peterjones, @coises and All,
I must apologize to @coises ! My reasoning about the necessity or not to use an atomic group was completely erroneous :-(( Indeed, I would have been right if the regex would have been :
\x0C[^\x0C]+(?=\x0C)But, the @coises regex is slightly different :
\x0C[^~\x0C]+(?=\x0C)And because the
~character belongs to the negative class character[^.......]too, the fact of using an atomic group or not, for the pages containing the~character, is quite significant ! Indeed :-
The normal regex
\x0C[^~\x0C]+(?=\x0C)would force the regex engine, as soon as a~is found, to backtrack, one char at a time, up to the first character of a page, after\x0C, in all the lines which contain the~character. Then, as the next character is obviously not\x0C, the regex would skip and search for a next\x0Cchar, further on, followed with some standard characters -
Due to the atomic structure, the enhanced regex
\x0C[^~\x0C]++(?=\x0C)would fail right after getting the~character and would force immediately the regex engine to give up the current search and, search, further on, for an other\x0Ccharacter, followed with some standard chars !
Do note that, if the
~character is near the beginning of each page\x0C, you cannot notice any difference !I did verify that using an atomic group reduce the execution time, for huge files ! With a
30 Mofile, containing159,000lines, whose1,325contains the~char, located4,780chars about after the beginning of each page, the difference, in execution, was already about1.5s!!As a conclusion, @rjm5959, the initial @coises’s regex
\x0C[^~\x0C]++(?=\x0C)is the regex to use with files of important size ;-))BR
guy038
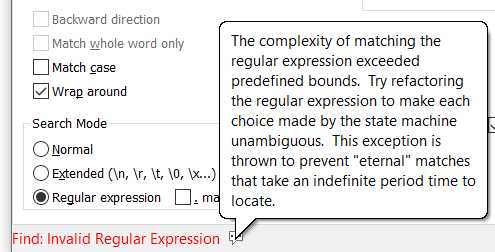
Couldn’t get this to work, but it’s far too complicated anyway for non tech people to run. We are now receiving the data without the FF. Now the header page has 1 like below followed by S3001-54D. I have the below that I’m using to search for the header and all the details within that page and works when I start at the first hit and click on ‘Find Next’, but as I’ve said, there’s over 80,000 hits. When I search the whole file for all hits to Find or Mark, I get the “Find: Invalid Regular Expression” message. Is there any way to get this to loop and get all the hits and export? Maybe creating a Macro? I need something simple that non tech people can run every month end.
(?s)^1((?!^1).)?nationstar.?^1
1S3001-54D CENTRAL LOAN ADMINISTRATION 04/01/24
LETTER LOG HISTORY FILE FOR NATIONSTAR MORTGAGE LLC1 PAGE 754940e70341-916a-47b8-8bdf-e00f2a5ccf01-image.png
-
-
This post is deleted! -
-
@rjm5959 The average car can be driven at 100 MPH (160 km/h). Is that a good idea? Likewise, there are things you may be able to do in a regular expression under ideal circumstances that are a bad idea when the road gets twisty with obstacles.
Your project seems much more suited for something coded in a scripting or compiled language. This makes it easy to break the project down into small easy to understand and debug pieces. When there is a change in the requirements, or your understanding of the problem, it’s usually quite easy to make tweaks to a scripted/compiled solution.
It’s possible this Synergy thing you mentioned also supports scripting.
-
@mkupper This is easily done in Synergy and the hits and pages are found quickly. The issue is when exporting. When exporting these 89,000 hits it’s about 5.5 million lines and takes many many hours to export. During regular business hours it’s excruciating. It can run all day and night to pull this much data. The issue is compounded because we moved our Synergy servers and data to the cloud from on prem. When everything was on prem, the extract ran faster, but it was still slow. Not nearly as bad as now.
-
@rjm5959 said in Exporting pages from Hits?:
@mkupper This is easily done in Synergy and the hits and pages are found quickly. The issue is when exporting. When exporting these 89,000 hits it’s about 5.5 million lines and takes many many hours to export. During regular business hours it’s excruciating. It can run all day and night to pull this much data. The issue is compounded because we moved our Synergy servers and data to the cloud from on prem. When everything was on prem, the extract ran faster, but it was still slow. Not nearly as bad as now.
See if Synergy offers server side scripting. If so, you can filter or reformat the data prior to exporting or downloading it. If there is still a desire or need to have many thousand or millions of lines in the export then look into parsing, filtering, and/or reformatting the data using PythonScript. That will allow you to mix-n-match the benefits of a procedural language and regular expressions.
-
@rjm5959 said in Exporting pages from Hits?:
1S####-##C CENTRAL LOAN ADMINISTRATION YY/MM/DD
LETTER LOG HISTORY FILE FOR NATIONSTAR MORTGAGE LLC1 PAGE ####I know nothing about the context in which you’re using this data, but are you sure that you’re not leaking confidential data to the internet by posting this here? Because if you are, consider anonymizing it.