Separate Question and Answer about 1000 topics
-
Please help me to convert the text to CSV as a structure
1.1.1 This is question number 1?
This is answer 1 with opinion 1
This is answer 1 with opinion 2
…
…
1…1.2 This is question number 2?
This is answer 2 with opinion 1
This is answer 2 with opinion 2
…
…And I want to separate into 02 columns with answers and question
I know the question ends with a question mark, and below the question is the answer. But I don’t know how to separate that. Please help me
Thank you very much -
@PXuan-Tang said in Separate Question and Answer about 1000 topics:
And I want to separate into 02 columns with answers and question
Showing us the “after” data would be helpful, because I cannot understand your desired output.
When you put int the data, use the
</>button on the forum toolbar while editing your post, and enter your two-column data in between the```lines:``` put your example output here please ```This way, we can be certain how you mean it to look.
-—
Useful References
-
There’s no good way to convert data from that format to a CSV in Notepad++ without using plugins. This is because the text of a question or an option might contain a literal
,character or a literal"character, and the presence of those characters in a question or option would require some processing to ensure that the result was a valid CSV file. I don’t believe that regular expressions (which would be the only non-plugin way to do something like this) are a good tool for correctly handling this kind of problem.I have written a script using PythonScript that would address this issue, but before I post it I’d like to know if you’re willing to install a plugin to try to fix this problem, and I’d also like to see if anyone else can come up with a reasonable solution that doesn’t require plugins.
-
@PeterJones Hi PeterJones,
Thank you for your reply,This is input
1.1.1 This is question number 1?
This is answer 1 with opinion 1
This is answer 1 with opinion 2
…
…
1…1.2 This is question number 2?
This is answer 2 with opinion 1
This is answer 2 with opinion 2
…
…I want to output as picture
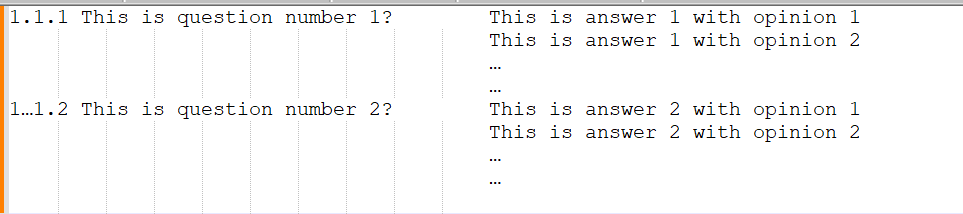
Thanks you.
…
-
@Mark-Olson Thank you for your reply,
Please help me to use your script as my case.
Thank, -
@PXuan-Tang said in Separate Question and Answer about 1000 topics:
This is input
1.1.1 This is question number 1?
This is answer 1 with opinion 1
This is answer 1 with opinion 2
…
…
1…1.2 This is question number 2?
This is answer 2 with opinion 1
This is answer 2 with opinion 2
…
…I want to output as picture
I would do this in multiple steps. First, put a tab character at the beginning of every line that does not end with a question mark:
Find what:
(?-s)^(?!.*\?$)
Replace with:\tNext, remove the line breaks following the question marks:
Find what:
\?\R
Replace with:?Now you have the structure you want; the only problem is that the tabs probably don’t line up.
The simplest way to fix that is to open Settings | Preferences…, select Language in the box at the left, and then change Indent size (which, despite its name, controls the tabulation grid, not just indentation) to a number large enough to move the second column to the right of the longest entry in the first column. You can see it move as you change the number, so it shouldn’t be too hard to find a number that works.
From there, you can use Edit | Blank Operations | TAB to Space if you want spaces instead of tabs.
If you really want CSV (as stated in your original post) instead of the example you gave, you should probably use a plugin to do the conversion. I can describe how to do it with Columns++; others will be more familiar with different plugins.
-
@Coises said in Separate Question and Answer about 1000 topics:
(?-s)^(?!.*?$)
Thank you for your reply, @Coises
I will try as per your instructions.
Thank you very much -
Here’s my PythonScript script, which can output a CSV or TSV file while ensuring that each row has the right number of columns and any instances of the column separator inside a column are handled correctly.
''' ====== SOURCE ====== Requires PythonScript (https://github.com/bruderstein/PythonScript/releases) Based on this question: https://community.notepad-plus-plus.org/topic/25962/separate-question-and-answer-about-1000-topics ====== DESCRIPTION ====== Converts a list of questions in the following format into a RFC-4180 compliant CSV file (in other words, a CSV file that is designed to be easy for lots of applications to read) ====== EXAMPLE ====== Assume that you have the text below (between the ------------ lines): ------------ 1.1.1 This is question number 1? "This is answer" 1 with option 1 This, is answer 1, with option 2 1.1.2 This is question number 2? This is answer 2, with "option 1" This is answer 2 with option 2 This is answer 2 with option 3 1.1.3 This is question "number 3"? This is answer 3 with option 1 1.1.4 This is question, number 4? This is answer 4 with option 1 This is answer 4, with option 2 This is answer 4 with "option" 3 This is answer 4 with option 4 ------------ This script will output the following CSV file (between the ------------ lines) ------------ question,option 1,option 2,option 3,option 4 1.1.1 This is question number 1?,"""This is answer"" 1 with option 1","This, is answer 1, with option 2",, 1.1.2 This is question number 2?,"This is answer 2, with ""option 1""",This is answer 2 with option 2,This is answer 2 with option 3, "1.1.3 This is question ""number 3""?",This is answer 3 with option 1,,, "1.1.4 This is question, number 4?",This is answer 4 with option 1,"This is answer 4, with option 2","This is answer 4 with ""option"" 3",This is answer 4 with option 4 ------------ ''' from Npp import editor, notepad import json def convert_q_list_to_csv_main(): # this is set to ',' to make a CSV file. # you could instead use '\t' if you wanted a TSV (tab-separated variables) file SEP = ',' question_lines = [] def to_RFC_4180(s: str, sep: str) -> str: if '"' in s or sep in s or '\r' in s or '\n' in s: return '"' + s.replace('"', '""') + '"' return s editor.research(r"((?'question'^\d+\.\d+\.\d+ +(.*\?)$))(?:\R(?!(?&question)).*)+", lambda m: question_lines.append(m.group(0).splitlines())) print(json.dumps(question_lines, indent=4)) max_n_options = max(len(x) for x in question_lines) header_text = 'question' + SEP + SEP.join('option %d' % ii for ii in range(1, max_n_options)) out_line_texts = [header_text] for question in question_lines: RFC_4180_texts = [] for ii in range(max_n_options): if ii >= len(question): RFC_4180_texts.append('') else: RFC_4180_texts.append(to_RFC_4180(question[ii], SEP)) out_line_texts.append(SEP.join(RFC_4180_texts)) notepad.new() editor.setText('\r\n'.join(out_line_texts)) if __name__ == '__main__': convert_q_list_to_csv_main() del convert_q_list_to_csv_mainBefore you ask, I made the odd programmatic choice to define helper functions and global constants inside the main function to avoid polluting the global PythonScript namespace.
-
 M Mark Olson referenced this topic on
M Mark Olson referenced this topic on
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login