Replace multiple, alternate lines in a comparison of two files
-
Hello! So, I’m translating a really big file for a Pokémon RPG Maker game, and I’m using two files: one in Spanish and another one in English.
The thing is, lots of the lines just need to be copypasted from one file to the other one, and double-clicking got old pretty fast. I’m trying to find a way of doing this as quick as possible to prevent burning myself out, but I haven’t found a good method of doing so.
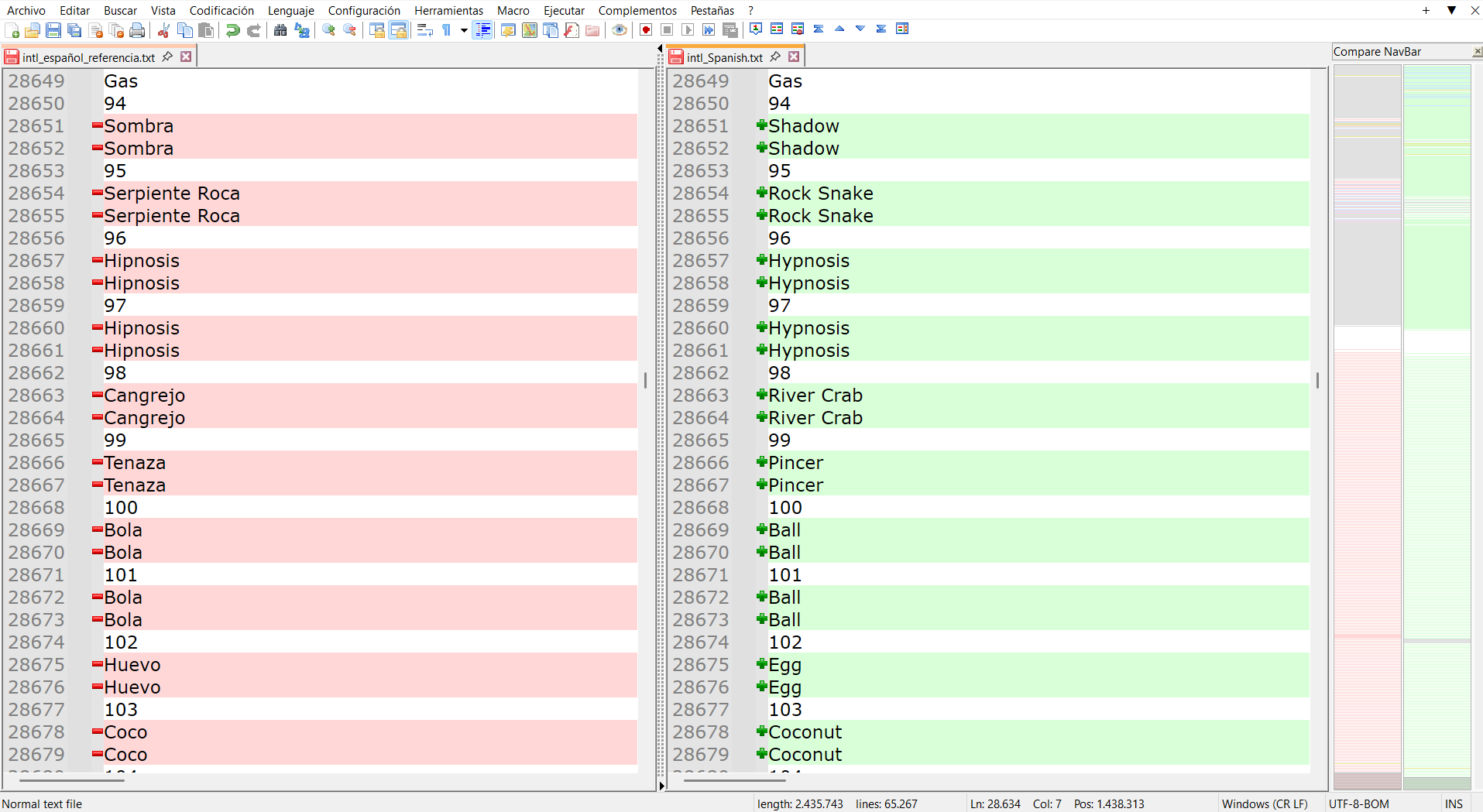
As you can see, the Spanish file is on the left and the English one on the right. I need to copy/translate the second lines of the English file and leave the first ones untouched, and I figured that I could double-click those lines on the Spanish file, pressing ctrl to select multiple ones, and doing the same thing on the right but pasting them.
…But, as I wrote before, it’s just a pain.
I found a program called “Meld”, and while it kind of does what I want, it’s a bit slow and it doesn’t replace just the second line, but both of them.
The question is: is there a plugin that could help me do what I’m looking for? It’s my first time using Notepad++, so I’m a bit lost here.
Thanks!
-
It would help if you had shown an example of exactly what you want the final result to look like, because I found your explanation confusing.
To clarify, based on the example above, the final result would look like the below, correct?
Gas 94 Sombra Sombra,Shadow 95 Serpiente Roca Serpiente Roca,Rock SnakeIf you continue to ask for help without showing examples of what you want, I suspect that other forum regulars will lose interest in helping you.
-
@Mark-Olson I’m so sorry! I was so focused on the problem that I forgot to show exactly what I’m looking for.
It would be something like this:
94 Shadow Sombra 95 Rock Snake Serpiente Roca 96 Hypnosis HipnosisThank you!
-
Thanks for sharing an example of what you wanted. The following script should meet your needs. It’s self-documenting.
''' NOTE: This script is UNTESTED. I wrote it on a computer with no access to Notepad++, going purely off of my memory. It may need to be tweaked before it is executable. Requires PythonScript plugin (see https://community.notepad-plus-plus.org/topic/23039/faq-how-to-install-and-run-a-script-in-pythonscript) REFERENCE: https://community.notepad-plus-plus.org/topic/26913/replace-multiple-alternate-lines-in-a-comparison-of-two-files DESCRIPTION OF SCRIPT: Suppose you have two parallel files, one in Spanish and one in English. The English file looks like this: ------- 94 Foo_english Foo_english 96 Bar_english Bar_english ------- The Spanish file looks like this: ------- 94 Foo_spanish Foo_spanish 96 Bar_spanish Bar_spanish ------- The goal of this script is to create a file FINAL_FILE that is identical to ENGLISH_FILE, except that if the i^th line of the ENGLISH_FILE is identical to the (i-1)^th line of ENGLISH_FILE, the i^th line of FINAL_FILE is the same as the i^th line of SPANISH_FILE. Given the two above example files, the result would look like this: ------- 94 Foo_english Foo_spanish 96 Bar_english Bar_spanish ------- To use this script, do the following: 1. Copy the text of ENGLISH_FILE and paste it into a new tab (hereafter referred to as NEW_TAB) 2. Hit Enter to add a new line at the end of NEW_TAB, then type in ========== (10 instances of the "=" character), then Enter to create an empty line at the end. 3. Paste the text of SPANISH_FILE at the end of NEW_TAB. 4. Using the status bar at the bottom of NEW_TAB, convert the Line Ending to "Windows (CR LF)". 5. Execute this script. The text of NEW_TAB will now be the desired output. ''' from Npp import editor complete_text = editor.getText() text_english, text_spanish = complete_text.split('\r\n==========\r\n') lines_english = text_english.splitlines() lines_spanish = text_spanish.splitlines() final_lines = lines_english[:] for ii, (line_eng, line_spa) in enumerate(zip(lines_english, lines_spanish)): if ii >= 1 and line_eng == lines_english[ii - 1] and line_spa == lines_spanish[ii - 1]: final_lines[ii] = line_spa final_text = '\r\n'.join(final_lines) editor.setText(final_text)EDIT (4 mins after original posting): Added a step before the last step instructions to convert the line ending of NEW_TAB to
Windows (CR LF)so that the script works correctly as written.EDIT2 (27 mins after original posting): I would endorse using Coises’ method rather than this one if at all possible. Generally I think it’s best to not use plugins unless you absolutely need to.
-
 M Mark Olson referenced this topic on
M Mark Olson referenced this topic on
-
I can think of a way, though it’s a bit complicated.
First, copy just the lines that contain your numbered lists into two new tabs, one for each language.
In the Spanish tab, Replace All using this regular expression and replacement:
Find what:^(\d++)\R(.++)\R.++
Replace with:$1S $2In the English tab, Replace All using:
Find what:^(\d++)\R(.++)\R.++
Replace with:$1E $2
(Same except for the letter E instead of S in the replacement.)Now, copy the contents of one tab into the other. It doesn’t matter which tab, or which comes first, but be sure there is a line ending between the last line of the first block and the first line of the second, so the two lines don’t merge into one.
Now, sort that. You’ll wind up with a file that looks like:
94E Shadow 94S Sombra 95E Rock Snake 95S Serpiente Roca 96E Hypnosis 96S HipnosisNow Replace All using:
Find what:^(\d++)E (.++)\R\1S (.++)
Replace with:$1\r\n$2\r\n$3Copy the whole result into the new file you are making.
I went through the steps, but didn’t spell out details. If you need more clarity about how to do certain steps, ask.
-
(cross post that is similar to @Coises’s method but has details…)
@Drakyem I noticed several things about the data.
- You are already up to line 28679 in the files but only at element or phrase 102. That implies there is a lot of stuff in the files that does not match the pattern that is visible in your screen shots. For now I will assume that the data does match the pattern, knowing that it probably does not.
- You showed two and three digit phrase numbers. I’ll assume that your phrases are numbered from 1 up to 999 and are never four digits or more.
- The phrases are always one line line and are always repeated.
The first thing I’ll do is to normalize the lines so that they are one line per phrase with the phrase number, tab, language code, tab, and phrase.
I use three separate search/replaces to add leading spaces to the one and two digit phrase numbers. That will make sorting easier.
Search:
(?-i)^([0-9])\R(.+)\R\2$(?=\R[0-9]+)$
Replace:\x20\x20\1\ten\t\2
Search:(?-i)^([1-9][0-9])\R(.+)\R\2$(?=\R[0-9]+)$
Replace:\x20\1\ten\t\2
Search:(?-i)^([1-9][0-9][0-9])\R(.+)\R\2$(?=\R[0-9]+)$
Replace:\1\ten\t\2Do search/replace all on the English file. For the Spanish side use the same search but on the replacement it’s
Replace:\x20\x20\1\tsp\t\2
Replace:\x20\1\tsp\t\2
Replace:\1\tsp\t\2Search:
(?-i)^([0-9])\R(.+)\R\2$(?=\R[0-9]+)$
Replace:\x20\x20\1\ten\t\2
Search:(?-i)^([1-9][0-9])\R(.+)\R\2$(?=\R[0-9]+)$
Replace:\x20\1\ten\t\2
Search:(?-i)^([1-9][0-9][0-9])\R(.+)\R\2$(?=\R[0-9]+)$
Replace:\1\ten\t\2Here is an example using some test data with 1, 2, and 3 digit phrase numbers.
Noticed that I added one line at the end of each line with 999. I’ll explain why I did that in a bit:# English phrases 1 apple apple 22 apple apple 333 apple apple 999 # Spanish phrases 1 manzana manzana 22 manzana manzana 333 manzana manzana 999Result after the three search/replaces:
# English phrases 1 en apple 22 en apple 333 en apple 999 # Spanish phrases 1 sp manzana 22 sp manzana 333 sp manzana 999Result after sorting this into one list:
1 en apple 1 sp manzana 22 en apple 22 sp manzana 333 en apple 333 sp manzanaConvert the sorted list into the layout that you want:
Search:(?-i)^ *([0-9]+)\ten\t(.+)\R *\1\tsp\t(.+)
Replace:\1\r\n\2\r\n\3
The results should look like:1 apple manzana 22 apple manzana 333 apple manzanaDeciphering those regular expressions as English.
Search:
(?-i)^([1-9][0-9])\R(.+)\R\2$(?=\R[0-9]+)$
Replace:\x20\1\ten\t\2On the search side:
(?-i)Make the search case sensitive^([1-9][0-9])\RMatch a two digit value (10 to 99) on a line by itself and save it in capture group\1(.+)\RSave all of line 2 into capture group\2\2$Make sure line 3 exactly matches line 2. That’s why I did the initial(?-i)asAppleshould not matchapplefor example.(?=\R[0-9]+)$Make sure there is a line 4 and that it’s a numeric value. This is a sanity check and is also why I needed to add one final line with 9999.
On the replace side:
\x20Output one leading space as this deals with two digit phrase numbers.\1Output the phrase number.\ten\tOutput a tab, the language codeen, and another tab.\2Output the phrase
The search/replace that converts the list into the layout that you desire is similar.
Search:
(?-i)^ *([0-9]+)\ten\t(.+)\R *\1\tsp\t(.+)
Replace:\1\r\n\2\r\n\3Decoded search:
(?-i)Make the search case sensitive (this is optional but I wanted to match the lower case language codes.^ *([0-9]+)Ignore leading spaces and save the phrase number as capture group\1.\ten\tMatch tab, language codeen, tab.(.+)\RSave the English phrase as capture group\2.*\1Ignore leading spaces and make sure the phrase number matches capture group\1.\tsp\tMatch tab, language codesp, tab.(.+)Save the Spanish phrase as capture group\3.
Decoded replace:
\1\r\nOutput the phrase number followed by a carriage return and line feed.\2\r\nOutput the English phrase followed by a carriage return and line feed.\3Output the Spanish phrase.
The search/replace that converts the list into the layout that you desire is similar.
Search:
(?-i)^ *([0-9]+)\ten\t(.+)\R *\1\tsp\t(.+)
Replace:\1\r\n\2\r\n\3Decoded search:
(?-i)Make the search case sensitive (this is optional but I wanted to match the lower case language codes.^ *([0-9]+)Ignore leading spaces and save the phrase number as capture group\1.\ten\tMatch tab, language codeen, tab.(.+)\RSave the English phrase as capture group\2.*\1Ignore leading spaces and make sure the phrase number matches capture group\1.\tsp\tMatch tab, language codesp, tab.(.+)Save the Spanish phrase as capture group\3.
Decoded replace:
\1\r\nOutput the phrase number followed by a carriage return and line feed.\2\r\nOutput the English phrase followed by a carriage return and line feed.\3Output the Spanish phrase.
-
This post is deleted! -
Well, first things first.
Thank you all for trying to help me. This is my first post in this community and my first time using Notepad++, I’m quite lost, and I appreciate the time you have taken to answer me.
With that being said, I apologize again for not having explained myself as I should have.Here are some more screenshots of the documents:
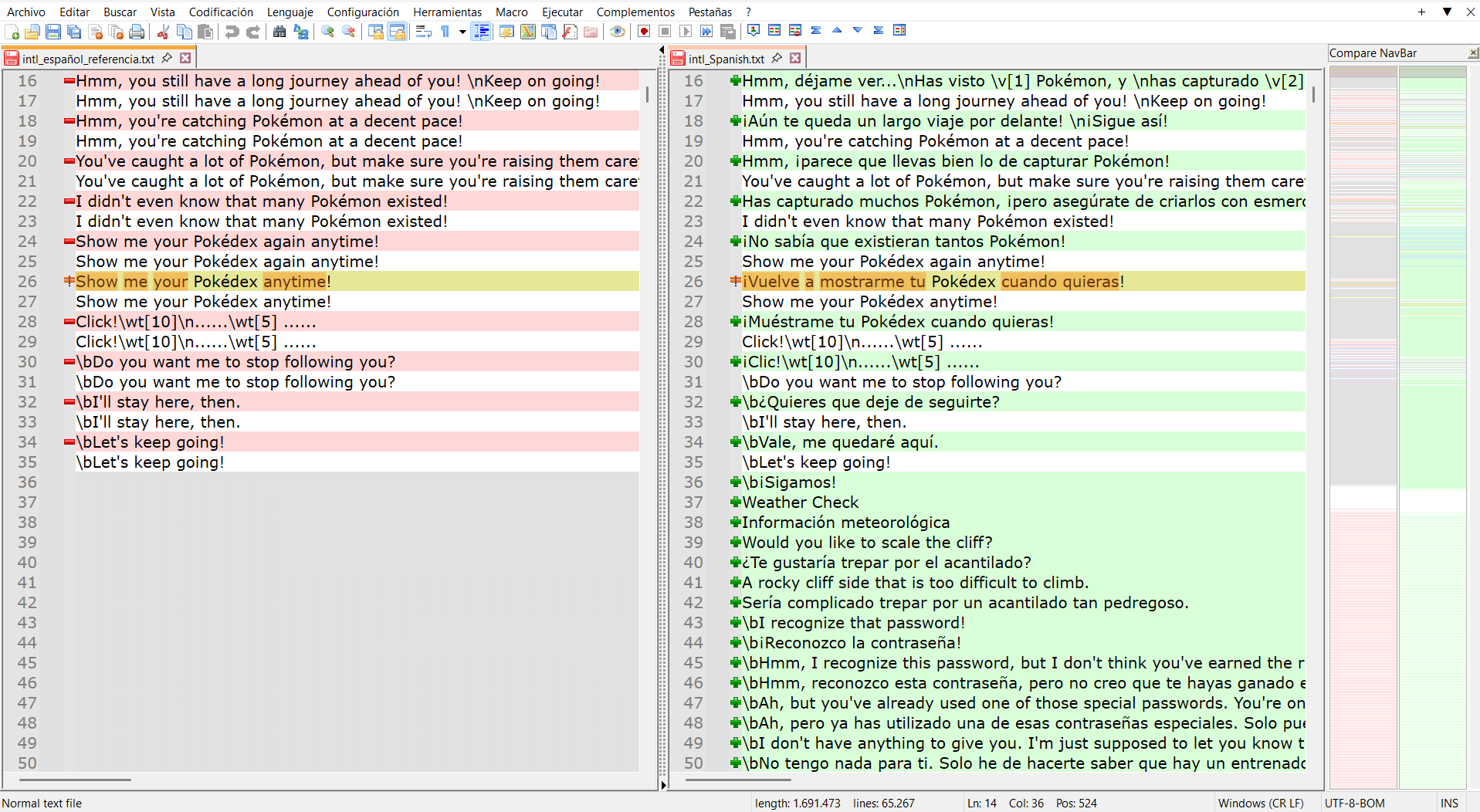
These are the first lines, which I have translated, as you can see. Those on the right that don’t have a pair on the left are new, because they weren’t in the “base game”, and were introduced in the game I’m translating. Those new lines, I’ll translate them myself, no copypaste.
Then, we have these kind of lines:
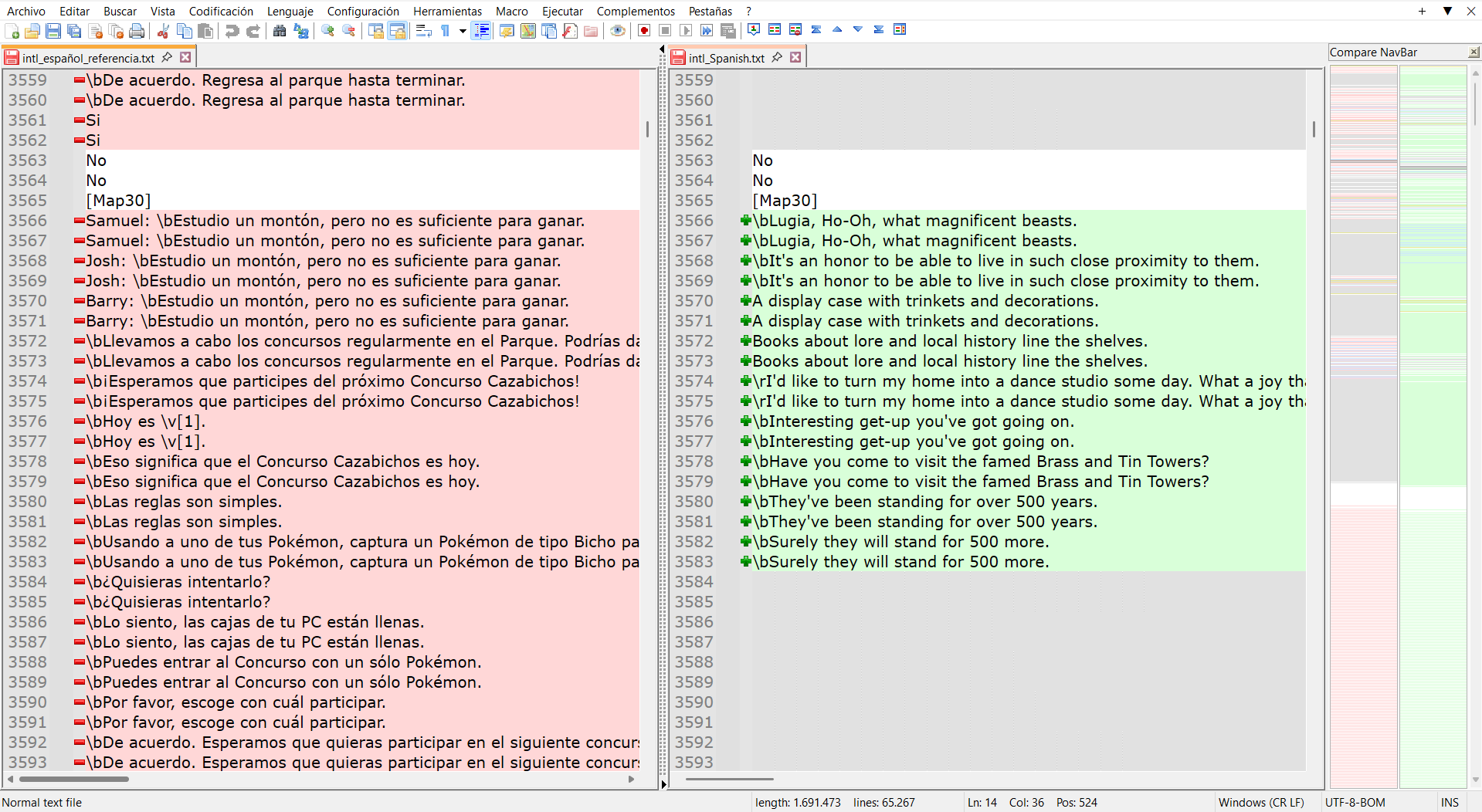
They DO HAVE a pair, but they don’t match, so I would have to translate them myself, too, ignoring the lines on the left (the “base game”).
There’s also lines such as these:
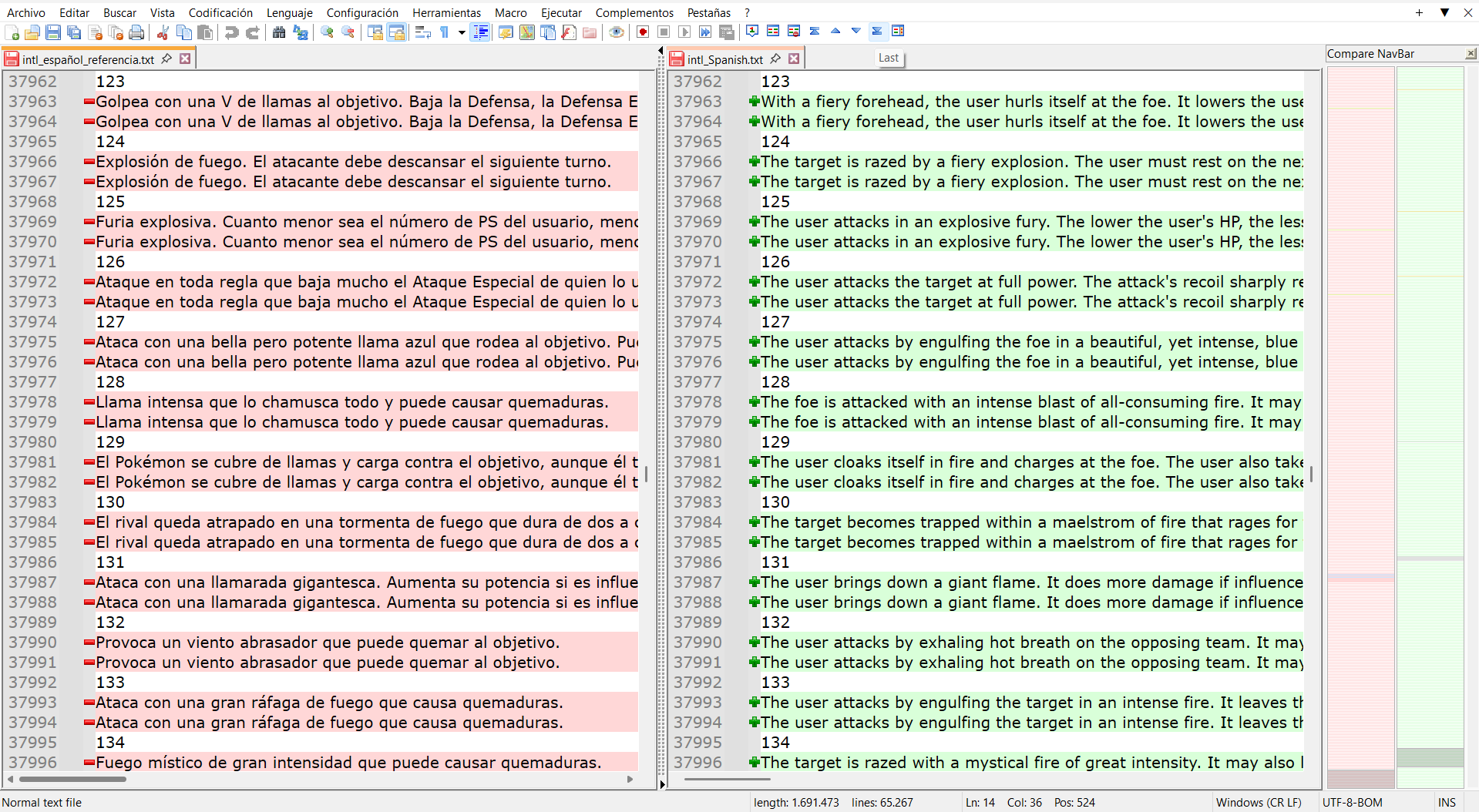
They have pairs, and I would have to double-click the ones on the left and replace ONLY the second lines on the right with the ones I copied from the left (because, when you’re translating a game made in RPG Maker, and you wish to add a translation, only the second lines after the original ones count for the translated version).
So, what I am looking for is some (quick) method to replace the lines with pairs (like the ones on the last screenshot).
I must say, I do appreciate your replies, but I didn’t really understand them… It looks to me like advanced Notepad++ methods.
Thank you very much!
-
@Drakyem said in Replace multiple, alternate lines in a comparison of two files:
So, what I am looking for is some (quick) method to replace the lines with pairs (like the ones on the last screenshot).
I don’t think there is a really quick method. If there are enough lines like this, it might be worth the trouble to use one of the methods suggested.
I’ll try to explain my previous suggestion a little better, and you can judge whether it sounds like it would be easier for you than just doing it by hand.
I guessed — and based on what you’ve written, I think this is correct — that there’s just one section of these files that you’re hoping to do automatically. That’s the section where each file has a line with a number on it, then two identical lines following the number. In one file both lines are in English and in another file both lines are in Spanish. You want to end up with a similar section that has the same format, but the first line in English and the second line in Spanish.
If that’s not right, stop reading now: I’ve misunderstood what you are trying to do.
The first step in my suggestion is to copy just the sections you are trying to merge into two new files. That way you don’t have to worry about messing up anything else, and you can replace the section as a whole later.
To do that, use Ctrl+N (or File | New) twice, to make two new, empty tabs. In the Spanish file, highlight the part that has the numbers and paired lines (the third section you described). To do that, click on the line number to the left of the first line in that section. Scroll down using the mouse wheel or the scroll bar — not the keyboard — until you find the end of that section. Hold down the Shift key and click on the number to the left of the last line in that section. You’ll see that all the lines in the section are selected. Use Ctrl+C (or Edit | Copy) to copy that to the clipboard.
Now you can paste that into one of the empty tabs. (Click on the tab, then Ctrl+V or Edit | Paste.) Do the same thing for the English file and the other tab.
At this point, I suggest saving those tabs with new file names (Ctrl+S or File | Save: be sure to pick new names and save where you can remember where they are!). Saving work as you go along — so long as you don’t save into the original files — can help make sure you don’t have to start all over if something goes wrong. You can just open those files and resume from there.
OK, that’s the first step. If that makes sense to you, we can proceed. I’ll just explain below in a general sense what you would do next. I’m going to wait for you to get back to me before I go into more detail.
The next steps use regular expressions to perform a search and replace with patterns. Regular expressions are powerful, but somewhat challenging to understand at first. (You won’t need to understand how they work to do this part.) The object of these steps is to get the parts that go together (the number and the text) into a single line.
The reason for that is that in the next step, you’ll put the two files together and sort the lines. That puts the bits from the English file and the Spanish file that go together right next to each other. Notepad++ only has a way of sorting individual lines, not groups of lines; so that’s why you have to condense the number and text into a single line first.
Having done that, the last step uses regular expressions again, this time to find adjacent pairs of lines with the same number and put them into the original format (number, English and Spanish all on separate lines).
-
@Coises Thank you for your reply.
I understood your directions, and you understood what I’m trying to do, too.
BUT, I may have made a mistake by showing different examples with the same format, because the sections that I want to replace do not only come with numbers in it, and I’m going to show you right now:
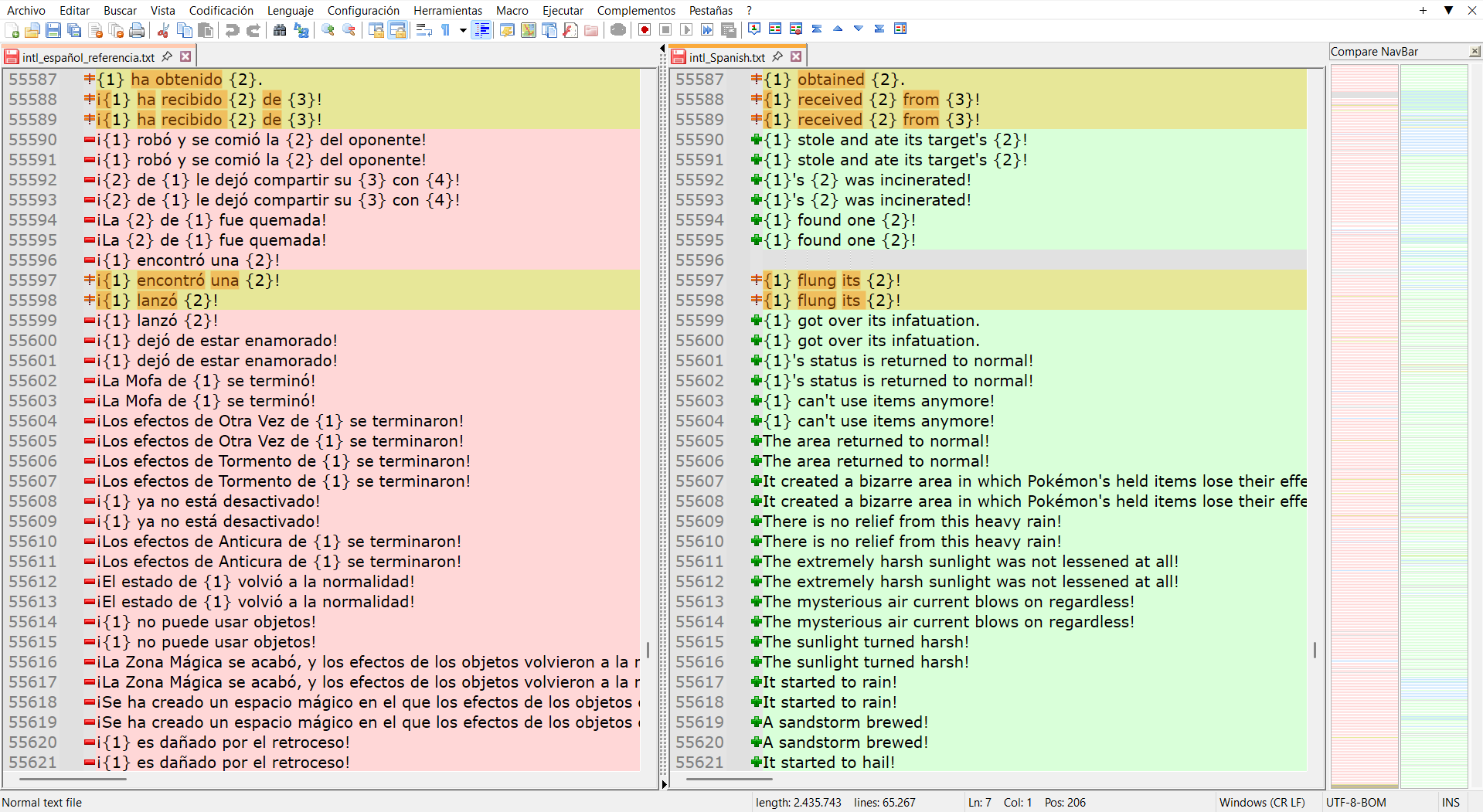
It’s the exact same case, but without numbers. Also, some lines from the left side are not on the right side (see lines 55592 and 55593 on the left, for example).
In this case, lines 555596 and 55597 on the left side correspond to lines 55594 and 55595 on the right side. -
@Drakyem said in Replace multiple, alternate lines in a comparison of two files:
In this case, lines 555596 and 55597 on the left side correspond to lines 55594 and 55595 on the right side.
I’ve been following some of this thread from the sidelines. And this latest snippet of information tells me that the goal of doing this with Notepad++ with any amount of tools or regexes is an exercise in
futility.Programs need a common reference in order to “combine” data. You now suggest that neither is guaranteed.
Terry
-
I’m afraid I come to the same conclusion as @Terry-R: given the lack of regularity in the data, there’s just no way to make this easier than the way you’re already doing it.
If there is a better way, I think you’d have to look for it in a forum about RPG Maker. Perhaps some purpose-built translation tool exists that “knows” how the files are constructed and how to make translation easier. Perhaps someone in r/RPGMaker would have an idea.
-
Oh, well, this is it, then. Thank you very much for your help. I guess I’ll have to be patient, then.
-
@Drakyem said in Replace multiple, alternate lines in a comparison of two files:
It looks to me like advanced Notepad++ methods.
That’s correct. My own current understanding of what you want to do is that the task is not trivial. It looks like it could be a fun project which is why several people have posted ideas.
-
- Install PythonScript 2.1 from Plugin Admin or download and install PythonScript 3.
- Goto menu Plugins -> Python Script -> New Script.
- Save with filename
PokemonIntlModifier.py. - Paste the PythonScript code into the saved file.
May need to restart Notepad++ to view the file entry in the menu.
Setup left pane as source and right pane to be modified.
These are minimal examples to test with.
Left pane:
# To localize this text for a particular language, please # translate every second line of this file. [Map0] ......\wt[5] ...... ......\wt[5] ...... Hello, \PN!\nI can see you calling me over there! Hello, \PN!\nI can see you calling me over there! <INSERTED> Come over and talk to me. Come over and talk to me. [map1] \c[2]Palmiro:</c> ¡Hemos terminado! \c[2]Palmiro:</c> ¡Hemos terminado! 0 ???????? ???????? 1 Bulbasaur Bulbasaur <INSERTED> 2 Ivysaur Ivysaur ¡Felicidades! Has completado {1}. ¡Felicidades! Has completado {1}. <INSERTED>Added
<INSERTED>to 3 lines to create differences like a language difference make it different.Right pane:
# To localize this text for a particular language, please # translate every second line of this file. [Map0] ......\wt[5] ...... ......\wt[5] ...... Hello, \PN!\nI can see you calling me over there! Hello, \PN!\nI can see you calling me over there! Come over and talk to me. Come over and talk to me. [map1] \c[2]Palmiro:</c> ¡Hemos terminado! \c[2]Palmiro:</c> ¡Hemos terminado! 0 ???????? ???????? 1 Bulbasaur Bulbasaur 2 Ivysaur Ivysaur ¡Felicidades! Has completado {1}. ¡Felicidades! Has completado {1}.PythonScript:
# about: Modify intl.txt extracted from the Pokemon Essentials Editor # help: https://community.notepad-plus-plus.org/topic/23039/faq-desk-how-to-install-and-run-a-script-in-pythonscript # name: PokemonIntlModifier # require: Notepad++ with PythonScript >= 2 plugin # src: https://community.notepad-plus-plus.org/topic/26913 # important: Left pane as source and right pane to be modified. from Npp import editor1, editor2, notepad def main(): # Set to True if 2nd line is different and should be made empty. blank_if_different = False # Do not modify these lines. line_count = editor.getLineCount() line_next = True replaced = 0 editor2.beginUndoAction() # Process the buffers. for line in range(line_count): # Get lines from both editor panes. text1 = editor1.getLine(line).rstrip('\r\n') text2 = editor2.getLine(line).rstrip('\r\n') # Skip comment and section lines. if text1.startswith(('#', '[')): continue # Skip integer lines. if text1.isdigit(): continue # Allow the 2nd line only. line_next = not line_next if not line_next: continue # Replace 2nd line if different. if text1 != text2: if blank_if_different: text1 = '' editor2.replaceLine(line, text1) replaced += 1 editor2.endUndoAction() notepad.messageBox('Done {} lines'.format(replaced)) main()Result after running the script:
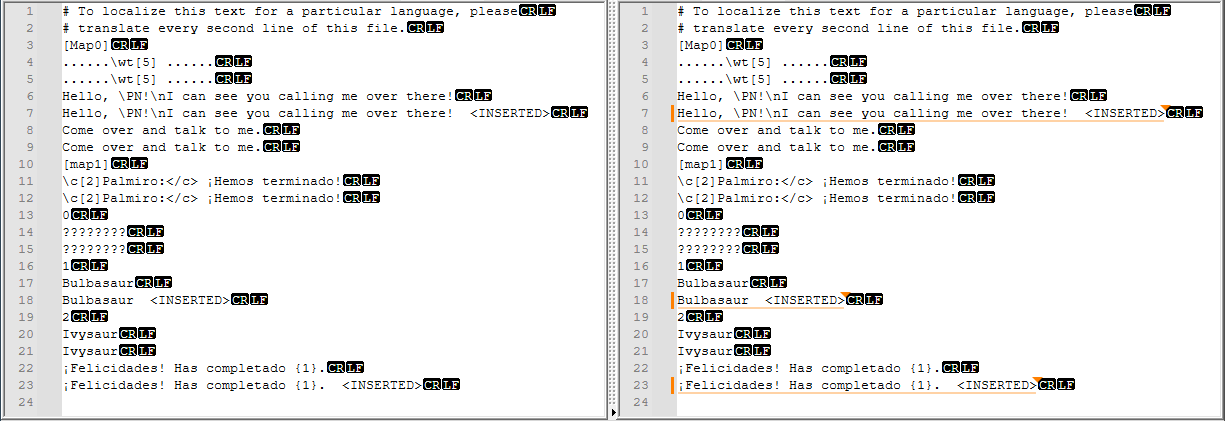
I enabled Change History to show in the lines and enabled End Of Lines to show to identify the affect of the modifications.
If inspected as not OK then it can be undone with pressing Ctrl+Z on the right pane.
-
M mpheath referenced this topic on
-
Hello. Thank you very much for this script, it works wonders! There are some misplaced lines (e.g. line 23 in one file corresponding to line 24 in the other one), but nothing that I can’t fix for the script to work within the entire file as it should.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login