How to remove duplicate words in a line using Notepad++?
-
Hello guy!
- No, neither before nor after the tabulation is there any space. In my previous post, I have put the spaces before and after it merely for the visual reason.
- Yes, the syntax you have shown is correct: “,SPACEword,”
The closest solution that I found yesterday was one with “SED” - but I have no idea, what SED is, where and how I would excute the SED-command. I would hence be grateful to you if you build the needed regex I could use with Notepad. Together with your previous one that you have recently built for me, this would completely cover my regex needs related to updating and maintaining my glossaries with Notepad.
Again, thank you in advance for your help!
-
I believe I’ve found a bug here. As I’m trying to solve the problem, the text is:
<a><c><a><c><c>and Find what:([[:w:]]+).*\K<\1>, and Replace with empty string.
As I press the Replace button, the text is not changed at all. It’s just selecting the last<a>and the last<c>back and forth.
However, strangely enough, if I press Replace All, it’s working.
Pressing Replace All twice transforms the text<a><c><a><c><c>into<a><c>.I have no idea why this is happening! Is it just me having this bug??
-
glossar,
Well, I succeeded to build a regex that does the job ! You’ll just need to run this S/R, TWICE, consecutively, :-))
To begin with, this regex, which deletes any additional duplicate expression, after a tabulation character, adopts the four following rules :
-
<expression>refers to any range of characters, surrounded by the two characterscomma+space -
ANY
<expression>, located BEFORE the tabulation character (\t), is NOT deleted -
If an
<expression>is present, ONE time, AFTER the tabulation character, this string is KEPT -
If an
<expression>is present, SEVERAL times, AFTER the tabulation character, ALL duplicates, AFTER the tabulation character, are DELETED, except for the LAST occurrence of this<expression>, which is KEPT
Therefore :
-
Move back to the very beginning of your file ( CTRL + Origin )
-
Open the Replace dialog
-
Uncheck, preferably, the Wrap around option
-
Select the Regular expression search mode
SEARCH
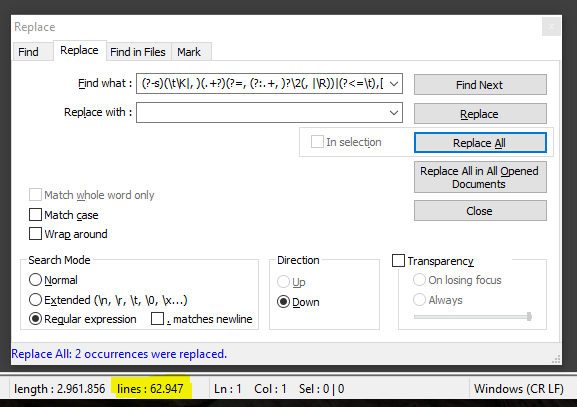
(?-s)(\t\K|, )(.+?)(?=, (?:.+, )?\2(, |\R))|(?<=\t),[ ]REPLACE Let
EMPTY- Click, TWICE, on the Replace All button
For instance, from the original text, below, with the tabulation character after the first occurrence of the number 99099 :
12345 word 99099 spring, off-spring, of, off spring, offspring, offsprings, offspring, off, off spring, 12345, offsprings, offspring’s, spring, off, of, ring, off-spring, ring, offspring’s, off-spring, offsprings, of, off spring, spring, offspring, spring, off, off spring, offsprings, offspring’s, off, offspring, ring, of, ring, off-spring, offspring’s, 11011, spring, off-spring, of, of, offsprings, off, ring, offspring, off-spring, 67890, off spring, offsprings, offspring’s, spring, off, off spring, offspring, ring, offspring’s, 99099, off-spring, of, off spring, offspring, ring, spring, off spring, offsprings, offspring, off, offsprings, 67890, offspring’s, offspring’s, spring, of, ring, off-spring, off, 99099We’ll get, after the TWO consecutive S/R, the final result :
12345 word 99099 12345, 11011, off spring, offspring, offsprings, 67890, offspring’s, spring, of, ring, off-spring, off, 99099Best Regards,
guy038
P.S. :
I have not time to give you, presently, some notes on this regex. May be this evening but rather, tomorrow evening !
-
-
@guy038,
It’s genius to select and remove the first occurrence. I tried your solution, and it works perfectly.
According to what I’ve tried out, actually, only ONE click on the Replace All button is needed. And, if you Check the Wrap around option, you don’t even need to move the cursor to the very beginning of the file. The regex you gave is very convenient. -
Guy - You are genius!
A warm thank you and a hot chocolate (well, virtually) for your time, effort and help!
I am much grateful to you!
Thank you!
-
Hi, glossar, 古旮 and All,
Many thanks, glossar, for the ( virtual ) chocolate ! Actually, we have coffee, after a nice lunch, at my sister and brother-in-law’s home, this week-end :-) Never mind ! I hope you spent a nice week-end, too !
Let’ go back to “work” :-)) Just a couple of precisions about my regex :
-
glossar and 古旮, you may have thought that the first S/R did the job completely However, if you’re curious, you’ll remark that after this first S/R, there remains a comma and a space, located… right after the tabulation character ! So, to be exact, I’ve added, at the end of the main regex
(?-s)(\t\K|, )(.+?)(?=, (?:.+, )?\2(, |\R))an alternative (|) and a second simple regex(?<=\t),[ ], which is only performed, when you click the Replace All button, the second time ! -
古旮, it’s very well-known that the present N++ regex engine does NOT handle the look-behind features, especially, in case of overlapping strings, which belongs, for one part, to the look-behind and, for the other part, to the main regex to search for ! As a consequence :
-
Some matches may be found, by error, or, the opposite, not found, at all, by the regex engine, when using look-behinds
-
One CANNOT use the Replace button, but, EXCLUSIVELY, the Replace All button, when your regex contains, at least, one of these three following syntaxes :
-
A positive look-behind
(?<=.......) -
A negative look-behind
(?<!.......) -
The
\Kform, which resets the location of the searched regex. So, the part before the\Ksyntax, have to be matched, but, due to the reset action, the final regex to search for, is ONLY the part, located AFTER\K.
In addition, the\Kfeature allows to “simulate” a non-fixed length look-behind ( as, for instance, the look-behind(?<=.+a)testor(?<=a|bc|def)test, which are invalid regular expressions ! ) With the\Ksyntax, you would just have to change these two regexes, respectively, into.+a\Ktestand(a|bc|def)\Ktest!!
-
-
-
BTW, 古旮, I, personally, prefer to perform a neat S/R, by moving back to the very beginning of the current file AND unchecking the wrap around option Indeed, just imagine that your regex deals with beginning of line (
^) and that you let the caret in a middle of a line ! Luckily, most of a time, it doesn’t matter and you just can do as you like to. As for me, I prefer to avoid any unpredictable result :-))
-
This regex begins with the syntax
(?-s)which forces the regex engine to see the dot meta-character as any single standard character, only -
Then the part
(\t\K|, ) is the **group 1** whichlooks for, either :-
The tabulation character and resets the position of the regex engine
-
A comma, followed by a space character
-
-
The following part
(.+?)represents<expression>, discussed in previous post, so any range of characters, between the two characterscomma + space, stored in group 2 -
The part
(?=, (?:.+, )?\2(, |\R))is a condition, called a positive look-ahead, which had to be true, in order to valid the overall regex -
Inside this look-ahead, we find four parts :
-
A comma, followed by space character
-
(?:.+, )?which stands for the longest possible range of standard characters, followed by a comma and a space character, located before group 2, embedded in a non-capturing group -
\2represents the duplicate<expression> -
(, |\R)is the character(s), expected, after<expression>, That is to say, the couple comma + space OR any kind of EOL character
-
-
Finally, the part
(?<=\t),[ ], after the alternative symbol (|) is taken in account, in the second S/R, and searches for the two characters comma + space, ONLY IF preceded by a tabulation character -
As the replacement field is EMPTY, any
<expression>, that is duplicated, further on, in the same line, ( 1st S/R ) orcomma + space( 2nd S/R ) are deleted
Cheers,
guy038
-
-
Hi guy038,
Thank you for your explanation.-
You’re right, we shall press Replace All button twice. I didn’t notice that the
\thad been replaced with 4 spacebars (by the website I guess) in the sample original text in your last reply.
My bad. -
I AM aware of the look behind thing of NP++ (that it has to be length-fixed), and I’m not using
(?<=.......)or(?<=.......)in my regex. The<and>in my regex are just literal characters.
So, do you mean the BUG is caused by the presence of\Ksyntax (in that you said, “when any of these three syntaxes is contained”)? Then why does your regex behave correctly? There is also a\Kthere.
PS: I just tried your regex again, pressing Replace button once a time, and it was totally correct.
How the hell, does the
\Kfrom, have anything to do with the Replace and Replace All button? I’m so confused:- It seems that, in NP++, Replace All doesn’t mean repeated Replace. Is that intended(maybe implemented with separate functions), or shall we regard it as a BUG?
- If we only look at the Replace button, why is it, that, the program CAN do the right selection, but CANNOT simply replace the selected string with an empty string? If that IS a BUG, I believe it will be an easy-to-fix one.
Best!
-
-
Hello, 古旮,
To begin with, as this post is quite long, just have a drink ! , …and let’s go :
Ah yes, I just realized that, if we use my long example line :
12345 word 99099 spring, off-spring, of,....................................., spring, of, ring, off-spring, off, 99099Then, after hitting many times on the Replace button, I almost got the expected result : only the word spring, right after the tabulation character, should have been deleted. So, after moving the caret, some lines before, and performing this S/R again, it was OK !
By the way, as before the
\Ksyntax, there’s, only one tabulation character ( case of fixed length string ! ), my previous regex may, also, be written :SEARCH
(?-s)((?<=\t)|, )(.+?)(?=, (?:.+, )?\2(, |\R))|(?<=\t),[ ]REPLACE Let
EMPTY
Like you, I think that it’s a bit weird that it can select the right match but cannot delete that selection !?? Unfortunately, sometimes when hitting the Replace button, it’s even worse as it may forget some matches or select wrong matches !
It’s quite difficult to tell you, in what exact cases, this behaviour occurs. But I noticed it when the last character, of the look-behind and the first character, of the main regex, refer to the same set of characters !
So, to my mind, we do need to improve the present regular S/R regex engine, by using the François-R Boyer version. Of course, when the Boost regex library, similar to PCRE (Perl Compatible Regular Expressions ), was implemented in N++, on March 2012, some improvements, between the N++ version 6.0 and version 6.4.2, were done and some bugs were fixed by, both, Dave BrotherStone and François-R Boyer ( as the Zero length match call-tip message,… )
However, although the non-official François’s version, simply, relies on the BOOST library, he was able to fix major issues, relative to look-behinds and backward assertions, and succeeded to manage all UNICODE characters, as well as NUL characters, in replacement !
Here are, below, a non exhaustive list of issues with the current regex engine,_ which do not occur, with François-R Boyer’s version_ :
-
Overlapping lookbehinds and matched strings are NOT correctly handled. For instance, giving the 20 characters subject string aaaabaaababbbaabbabb and SEARCH =
(?<!a)ba*, we get 6 matches, but, unfortunately, 2 results are wrong. On the opposite, if SEARCH =(?<=a)ba*, we obtain 4 matches, but, it misses the string ba, at positions 10 and 11 :-(( With the improved version of François-R Boyer, it’s all OK ! -
We can’t use the NUL character in replacement. For example, the simple S/R : SEARCH =
ABCand REPLACE =DEF\x00GHI, the result is the string DEF only :-(. The François’s version does insert the NUL character between the strings DEF and GHI ! -
BACKWARD assertions are NOT correctly supported. E.g. : SEARCH =
\A.matches, successively, all the characters of the FIRST line. With the François’s version it only matches the FIRST character of the current file -
It doesn’t search and replace characters, which are outside the Basic Multilingual Plane (BMP ). For instance, in an full UTF-8 file ( with a BOM ), if SEARCH =
\x{104A5}\x{20AC}and REPLACE =\x{A3}\x{10482}, The present regex engine answers Invalid regular expression ! as for the François’s version does the replacement correctly !
Remark :
Of course, for that specific S/R, you need a font, that can display the Osmanya characters, and which is affected as the default style font, in the Style Configurator… dialogue ! To that purpose, download the Andagii font at :
http://www.i18nguy.com/unicode/unicode-font.html
and have a look to Osmanya characters at :
http://www.unicode.org/charts/PDF/U10480.pdf
-
Now, let’s suppose, for instance, the French subject string “Un événement”, on a new line, and the simple SEARCH regex
\w. After a click on the Find Next button, close the Replace dialog, and keep on searching some word characters, by hitting the F3 key. When you’re, about, at the end of the string, just go searching backwards, by hitting the SHIFT + F3 key. You’ll notice _that it CAN’T go backwards, past the é character !!!. The François’s version does works well, in both directions ! -
A last example : if you try to mark the matches of the simple SEARCH regex
(?<=.)., the present regex engine marks any character, EVERY OTHER time. With the François’s version, it correctly find all characters, except for the very first of each line ! -
François-R Boyer also created a new option SCFIND_REGEXP_LOCALEORDER, to get ranges of characters, in a locale order, NOT in Unicode order. For instance, the regex range
[A-B], with the Match case option SET, would match all the following characters AÀÁÂÃÄÅĀĂĄǍǺẠẢẤẦẨẪẬẮẰẲẴẶǼB, in a true UTF-8 file, with a suitable font ! -
To end with, the François-R Boyer’s version could display the EXACT error messages, instead of the generic message Invalid regular expression. For instance, the regex
(\d+abwould report the Unmatched marking parenthesis error message !
So, if you install the improved François-R Boyer version, of the BOOST regex engine, you’ll get some strong new features :
-
Search is performed in true 32 bits code-points, so it can handle characters, over the BMP ( Basic Multilingual Plane ). An interesting feature for most Asiatic people !
-
It can manage NUL characters, both, in search and in replacement, too.
-
Look-behinds are correctly handled, even in case of OVERLAPPING, with the end of the previous match.
-
It can handle ALL the Universal Character Names ( UCN) of the UCS Transformation Format , from
\x{0}to\x{7FFFFFFF}, particularly, all those of code-points over\x{FFFF}, which are outside the BMP. -
The backward regex search isn’t stopped, on matching a character, with Unicode code-point over
\x{007F}
Of course, the LOCALE order and ERROR messages new features will NOT be accessible, still, in current Notepad++ user interface !
VERY IMPORTANT :
-
The Beta N++ regex code, of François-R Boyer DO NOT work, will all versions of N++, AFTER the 6.9.0 version !
- So, download, first, the .zip or .7z archive of Notepad++ v6.9.0, from the link, below :
https://notepad-plus-plus.org/download/v6.9.html
-
Extract all the contents in any folder, in order to get a local N++ installation :-))
- Inside this new folder, rename The SciLexer.dll file as, for instance,
SciLexer.xxx
- Inside this new folder, rename The SciLexer.dll file as, for instance,
-
Then, to get this Beta N++ regex code ( that has NEVER been part of ANY official N++ release ) :
- Download, from the link below, the modified SciLexer.dll file. of François-R Boyer
http://sourceforge.net/projects/npppythonplugsq/files/Beta N%2B%2B regex code/
- Copy this file, in the installation folder, along with the Notepad++.exe and the
SciLexer.xxxfiles
- Download, too, the **readme.txt** fileEnjoy it !
REMARK :
Remember that this modified SciLexer.dll, build on May 2013, is based on Scintilla v2.2.7 !
Of course, I long for, ( since more than 3 years ! ), that this version would be fully integrated with, both, the latest version of N++ and Scintilla. Unfortunately, up to now, NO ONE feels interesting to implement the new regex François-R Boyer’s code and, as my C++ skills are, unfortunately, rather, near 0, you and me, just, have to content ourselves with using the present bugged N++ regex code :-((
In the meanwhile, I keep, in addition to the last N++ version, a local installation of N++ v6.9 , with the François-R Boyer modified version of SciLexer.dll, on my laptop, in order to gsee the correct search behaviour of some regexes or to perform, from time to time, special replacements ;-)
Best Regards,
guy038
P.S. :
You may verify, that using the François-R Boyer’s version, with the second formulation, of my regex, below ( without the \K syntax ) :
SEARCH
(?-s)((?<=\t)|, )(.+?)(?=, (?:.+, )?\2(, |\R))|(?<=\t),[ ]REPLACE Let
EMPTYThe replacement-suppression of all the duplicate words, after the tabulation character, as well as any string comma + space, located after the tabulation, are quite effective :-))
Unfortunately, if your regex contains the
\Ksyntax, it will NOT be good, even with the François-R Boyer’s version :-(( -
-
@guy038
Thank you very much for the reply! You are such an expert on Regex!! And N++!Your post definitely deserves documented somewhere more official, to help more people! I mean, is it possible to improve the current wiki page(either the N++ official one, or the wikipedia)?
I saw quite a few obvious errors on the N++ official wiki page, but couldn’t find an entrance to register in order to edit the regex tutorial.For example, I think it’s quite benificial for a user to know the limits of Regex.
As for me, after reading your post in this thread, I’ll avoid using\Kmyself if possible.You could actually make an excellent tutorial I believe!
Best regards.
Great thanks again! -
Hello guy,
I’m back to this topic again as I want to bring to your attention some problem I have encountered. Maybe you could help me with fixing it.
I was going to ask this long ago. You have written in your above explanation:
“Some matches may be found, by error, or, the opposite, not found, at all, by the regex engine, when using look-behinds”
Just to be sure, does this apply to the regex you have built or to the regex engine in Notepad?
How technically reliable is this regex? I can imagine what precisely works for a prototype or a small set, may not work for bulk amounts, at least not at the same precision level. And I guess regexes are no exception to this. Since great power (of a regex) comes with great responsibility/danger (of losing data) and I cannot one by one go through the changes this regex makes, I want to have an overall idea about much risk in terms losing data I take using this regex.
I have noticed that by the third click, this regex deletes all the lines (which is fine and hence your highlighting “run TWICE”). But how does this regex sense/know whether a click is a first or second or third click? Or to put differently: How and when is a file state reset for this regex? Closing and re-opening a file? Making a change (e.g. adding or deleting lines) in the file or editing some line and saving and reopening it? Several days ago when I first applied this regex, along with the other one ((?-s)^((.+\t).+)\R\2(.+)) and sorting/deleting duplicate lines, to one of my two glossaries in order to keep them clean and neat, I couldn’t somehow manage to apply all these operations and I don’t know in which state or at which step I have left the file. Today I added some entries to it and wanted to apply all these again: sorting/deleting duplicate lines via FX plugin, merging lines with “(?-s)^((.+\t).+)\R\2(.+)” and finally removing the duplicate words with this regex. But with the first click, this regex reduces the number of lines tremendously. Please have a look at the screenshots:
This is before the first click:
https://snag.gy/okswaC.jpgThis is after the first click:
https://snag.gy/6yzpBW.jpgThis is after the second click. It deletes all the lines, which makes me suspect the file is already in the first click state, since with the third click it deletes all the lines.
https://snag.gy/3jtkNc.jpgThis is another try, after copying and pasting the whole text into a new file. After first click:
https://snag.gy/P0GX2z.jpgThank you in advance for your help!
-
One more thing:
When this regex finds no duplicates to delete, does it delete all lines, hence is this same as with the third consecutive click? As already said, the fact that it deletes all the lines with the third click is fine, but it would be very nice and helpful if it would give the usual (and expected) info, just like others, like “0 occurrence was replaced”, instead of deleting all the lines when it founds no duplicate to delete.
And one strange thing:
Sometimes, after the first and second click on “replace all”, it states “1 occurrence was replaced” , but the colour of the “save icon” on the tab of the file doesn’t change to red, indicating that the files is modified.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login