function list - need help with regular expression
-
Hi,
I wanted to have a function list for wiki-files. The wiki-files have the extension “wik” and may look like this:
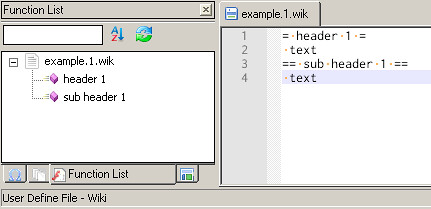
= header 1 = text == sub header 1 == textTherefore I added these rows to functionList.xml
.. <association ext=".wik" userDefinedLangName="wiki" id="wiki"/> .. </associationMap> <parsers> <parser id="wiki" displayName="wiki"> <function mainExpr="^=+.*=+$" displayMode="$functionName"> <functionName> <nameExpr expr="^=+.*=+$"/> </functionName> </function> </parser> ..After adding these rows the function list in notepad++ from looks this way:
= header 1 = text == sub header 1 == textIt looks to me that the “$” is not used for the first end-of-line but for the last end-of-line.
How can I modify my functionList.xml so that I can get a function list which only show the headlines:
= header 1 = == sub header 1 ==Thanks,
Christian -
Yes, per default the function list has set the flag DOTALL, which means
the dot matches any character at all, including the newline.
To reverse this you might think about using the modifier syntax"(?-s)^=+.*=+$"To be honest, I didn’t try it but I hope it works.
Cheers
Claudia -
Hello,
thanks a lot for your reply. I changed functionList.xml to
<functionName> <nameExpr expr="(?-s)^=+.*=+$"/> </functionName>and now the Function LIst looks different:
= header 1 =The first headline looks good, but the next is missing. This is only a short example - in my real file all headers are missing except the first one.
Do you have any ideas ?
Thanks,
Christian -
@Christian11235 try this parser:
<parser displayName="[TBD] Wiki" id ="wiki_syntax" > <function mainExpr="^=+\h+\K(?:\w+\h+)*\w+(?=\h+=+)" /> </parser> -
Hi,
sorry - with that mainExpr the function list stays empty.
One funny thing I realized: when I use my initial expression
^=+.*=+$in the search dialog then it works - it finds every single row. Can it be that the parser for the functionList.xml behaves differently than the parser in the search dialog ?
Thanks,
Christian -
Function List searches with
dot matches newlineenabled.Furthermore,
- the
displayName="[TBD] Wiki"should bedisplayName="Wiki"; - make sure you have defined a “User Defined Language” named
Wikii.e. same value (incl. case) as that ofdisplayName.
- the
-
Hello,
to 1: Yes - I assumed this.
to 2: Yes - this was the case from the beginning.To clarify: the problem ist not that the parsing is not working at all - the problem ist that not all headlines are found. Till now I only have regular expressions which either find
- the first headline
expr=“(?-s)^=+.*=+$” - all headlines but take them for one headline
expr=“^=+.*=+$”
Thanks,
Christian - the first headline
-
What about
(?m)^=+.*=+$or(?-s)=+.*?=+? -
Hi,
both expressions only show the first header. All headlines after the first header are ignored.
My testfile has the name tst.wik and looks like this
= header 1 = text == sub header 1 == textCU
Christian -
Sorry - I need to correct me - both expressions show the last header
-
Are you applying the changes to the correct
functionList.xml?
There might be more then onefunctionList.xmlfile on your system. -
Hello Christian 11235, Claudia, MAPJe71 and All,
Christian, I suppose that you’re speaking about the Wikimarkup, used in Wikipedia, aren’t you ?
https://en.wikipedia.org/wiki/Help:Wiki_markup
For a rapid test of your parser, you may, simply, use a usual text file. You don’t need to create any UDL language !
So, in a new tab, add the test lines, below :
= Header 1 = Line 1 Line 2 Line 3 == sub header 002 == Line 4 Line 5 Line 6 === sub header_3 === Line 7 Line 8 Line 9 ==== sub header 4 ==== Line 10 line 11 line 12 ===== TEST ===== Line 13 Line 14 Line 15 ====== sub header 6 ====== Line 16 Line 17 Line 18 = Last test ab___c d == Line 19 Line 20 Line 21 ======= Should NOT be displayed ======= Line 22 Line 23 Line 24- Save it as a .txt file
Then, in your functionList.xml file :
-
In the associationMap node, add the line :
<association langID= “0” id=“wiki_syntax” />
-
And, at the beginning of the parser node, add the parser, below :
<parser id="wiki_syntax" displayName="wiki"> <function mainExpr="^(={1,6})\h+\K(\w| )+(?=\h+\1)"> </function> </parser>You should see, in the Function List panel, each header of the different sections of my example:
Header 1 sub header 002 sub header_3 sub header 4 TEST sub header 6 Last test ab___c dNOTES :
-
In the value of mainExpr, there is a space between the alternative sign
|and the ending round bracket) -
I supposed that a header, of a section, is a non-empty string, which contains, ONLY :
-
Usual word characters ( Upper and lower letters, digits and the underscore _ )
-
Space characters
-
-
I didn’t consider the tabulation character. Indeed, if a header is, for instance, the string A[Tab][Tab][Tab][Tab][Tab]B, it is, simply, displayed as the string AB, in the FunctionList panel, anyway !
=> The middle part of the regex =
(\w| )+-
From beginning of line, each section header :
-
Begins with one to six equal sign(s), followed by, at least, one space character ( => the first part of the regex =
^(={1,6})\h+\K) -
Ends with the same number of equal signs, than, at beginning of line, preceded by, at least, one space character ( => the final part of the regex =
(?=\h+\1))
-
-
As this regex does NOT use the dot character, at all, the ``dot matches new line` way of search, of the functionList feature, doesn’t matter :-))
Best Regards,
guy038
-
Hi,
@all: thanks a lot for you effort.
@MAPJe71: As the changes show different results I think I edited the right xml file. There are also three languages in my functionsList.xml which I use in daily work - without problems.
@uy038: I copied all your steps - and maybe I have done something wrong - because I don’t see anything.
I took two screenshots:
This one show the functionsList.xml and the test-file and the resulting function List:
https://www.dropbox.com/s/z1cms3khiqmbe02/npp_screenshot01.jpg?dl=0
This screenshot shows the same but the focus is now on the functionList.xml - and there you can see a working functions list (just to proof its working at all).
https://www.dropbox.com/s/1uxii4mqhgw4vwz/npp_screenshot02.jpg?dl=0
In my functionList.xml are three other languages - for these three languages the function list works.
As said - thanks a lot for your effort. Maybe I am doing something wrong - but in the moment I cannot see it.
Christian -
Hi, Christian 11235,
Thanks for your two screenshots. I just noticed that your .txt file is an Unix file ( with
\nEnd of Line character )
with an ANSI encoding. So I changed my Windows file, with UTF8 encoding to test but, of course, this makes NO difference. I mean : I did get the expected list of sections in the Function List panel !So, at first sight, I, really, do NOT understand what happens ???. An idiotic question, to be sure ! Of course, you may modify and save the functionList.xml file from within Notepad++. But you need to close and re-start N++ to get it working !
Now, could you do an other simple test :
-
Use the SAME example text, of my previous post
-
In your functionList.xml file, in the “Wiki” parser, just change the line :
mainExpr="^(={1,6})\h+\K(\w| )+(?=\h+\1)">
by the line, below, which contains a very simple regex :
mainExpr="^Line \d+">-
Close and re-start N++
-
In the Function List panel, after selecting the test file, you should see the obvious list, below !
Line 1
Line 2
Line 3
Line 4
Line 5
Line 6
Line 7
Line 8
Line 9
Line 10
line 11
line 12
Line 13
Line 14
Line 15
Line 16
Line 17
Line 18
Line 19
Line 20
Line 21
Line 22
Line 23
Line 24
Tested with N++ v7.2 and N++ v7.3.2 => Both OK
Cheers,
guy038
-
-
@guy038 is there a specific reason you use
(\w| )+instead of[\w ]+? -
Hi, MAPJe71,
Good question : Absolutely no reason, indeed ! The syntaxes
(\w| )+and([\w ]+)are equivalent !I did a rapid test, comparing the two S/R, below
SEARCH
(\w| )REPLACE
\1\1and
SEARCH
([\w ])REPLACE
\1\1After 722,970 replacements, in both cases, your method seems a bit quicker than mime : 71s instead of 73s for my solution !
Cheers,
guy038
-
Hello,
-
Unix / Ansi is the default at the place I work at. I should have mentioned that.
Now that I think about it - at work I have to use Windows 7 32 bit (please don’t make me explain this *1) and also n++ 32bit. -
Yes I always closed and restarted n++.
-
mainExpr=“^Line \d+”> shows nothing in the Function List (edited functionList.xml, saved, closed n++, started n++, n++ 7.3.2 (32 bit, Build Feb 12 2017) )
Then i did some expermenting: Added my initial setup in functionList.xml, changed the test-file to UTF-8 BOM, Windows CR-LF. Result: only the first header is shown (no improvement).
Maybe it has something to do with n++ 32bit ? Later I will try this at home (windows 10, 64 bit).Thanks,
Christian*1 The company I work at believes in putting money in managers and outsourcing. Not in hired software engineers.
-
-
Hi,
I am sorry - I just made a mistake and used the wrong functionList.xml. Now that I am doing it correct
<function mainExpr=“^(={1,6})\h+\K(\w| )+(?=\h+\1)”/>
is working and shows the correct functions.
I can only apologize and thank you for all the help,
Christian
{kind=link}
{kind=link}
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login