Need help with functionlist regex
-
Hi,
for a userdefinde language I try to use the functionlist. For the subs/functions this is already working. But I want to see in the function list also some special markings/infos.
This is an example:
'--------- ' TestFile '--------- '****************** '# blabla '* << Infoline 1 >> '****************** '------------------------------------------------------------------------------- 'TestSub1 '------------------------------------------------------------------------------- Sub TestSub1() End Sub 'TestSub1 '------------------------------------------------------------------------------- 'TestSub2 '------------------------------------------------------------------------------- Sub TestSub2() End Sub 'TestSub2 '* Info Line 2! balbla '------------------------------------------------------------------------------- 'TestFunction '------------------------------------------------------------------------------- Function TestFunction() As Integer TestFunction = End Function 'TestFunctionWith this parser:
<function mainExpr="^\s*(sub|function)\s+\K\w+" > </function>I get this list at the moment:
- TestSub1
- TestSub2
- TestFunction
What I want is
- << Infoline 1 >>
- TestSub1
- TestSub2
- Info Line 2! balbla
- TestFunction
I tried this one
<function mainExpr="^\s*((sub|function)\s+\K\w+|('*)\s+\K.*)" > </function>but without success. Then nothing show up anymore in the list. Can someone help me with this? Thank you.
-
Try:
<function mainExpr="^\s*((sub|function)\s+\K\w+|'\*\s+\K.*)" > </function>The
*is a special character in RegEx’s, you need to escape it to match it literally. -
Thank you for the information. But even with the * it is not working. Nothing is show up in the list. Even not the sub|function anymore. I tried it on https://regex101.com/ and there it highlight what I’m looking for, but not in the functionlist. Do you have another hint?
-
<function mainExpr="(?m-s)^\h*(?:(?i:sub|function)\s+\K\w+|\x27\*\h+\K.*)" /> -
Thank you again. With this regex the sub/function is working again. But the '* still not. Is the reqex style of the functionlist somehow special?
-
Is the reqex style of the functionlist somehow special?
AFAIK it isn’t.
-
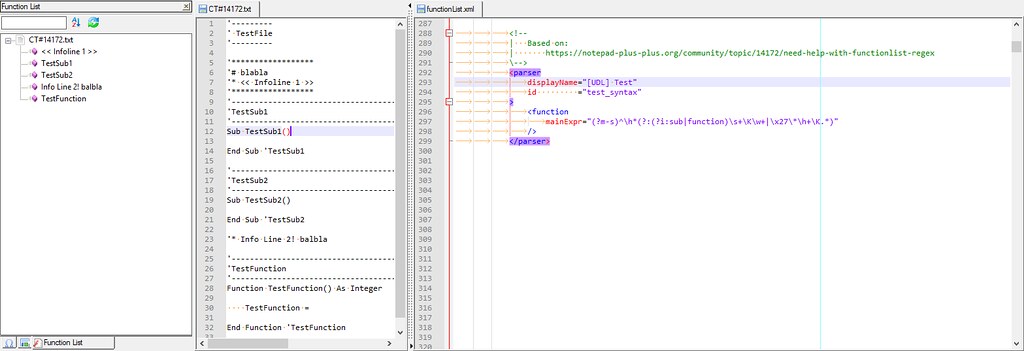
-
I found a solution :-)) To test it :
-
Open, in N++, your active functionList.xml file
-
Add the line, below, inside the <associationMap> node :
<association id= "Test" langID="0" />- Add the lines of the Test parser, below, inside the <parsers> node :
<parser id ="Test" displayName="Ma_Dill_Test" commentExpr="'(?!\* )(?-s:.+)" > <function mainExpr="^\s*(sub|function)\s+\K\w+|^'\*\s+\K(?-s:.+)" > </function> </parser>-
Save the changes of functionList.xml
-
Close and re-start Notepad++
-
Open a new tab
-
Copy your example text of your first post, in this new tab
-
Open the Function List panel ( View > Function List )
=> You should see your five functions, as you expect to !!
Notes :
-
I preferred to add the commentExpr part, which defines the line-comment zones to avoid, for further search of functions !
-
As I supposed that lines, beginning with
'*followed by some space characters, define special marking/infos
it becomes obvious that comment lines are lines which :-
Begin by a single quote character (
'), NOT followed by an asterisk + a “space” character'(?!\* ), which is a negative look-ahead -
And followed by all standard characters of the current line =>
(?-s:.+). The-smodifier is needed, because, by default, the Function List Regex engine considers all the text as a single line. ( So the regex.+would match any non-empty text, even on several lines. That is to say, all file contents ! )
-
-
In the mainExpr regex, I just add the alternative
^'\*\s+\K(?-s).+, which looks, after beginning of line, for :-
A single quote, followed with an *asterisk (
'\*) and, at least, one character, of type = “space” (\s+) -
Then, the syntax
\Kresets the regex search -
Finally, the part
(?-s:.+), again, looks for the remainder of the current line, only, due to the-smodifier, and is simply displayed, in the functionList panel !
-
BTW, Mapje71, the differences between your two posts, are the part
(?m-s), at beginning of the regex, in your last post ;-))Best Regards,
guy038
-
-
-
Hi, @madill, @mapje71, and All,
Updated on 07-22-17 (
\vsyntax added )MaDill, I, slightly, changed the mainExpr regex, as below :
(?i)^\h*(?:(?-i:Sub|Function)\s+\K\w+|'\*\s+\K(?-s:.+))Notes :
-
At beginning, the part
(?i)^\h*means that the search is, globally, case insensitive and that the key-words (Sub,Functionand'*may be preceded by optional tabulation and/or space characters -
Then, the general structure, which follows, is a non-capturing group, made of two alternatives (
(?:.....|......))
, As I thought that the key-words
SubandFunctionmust have that strict case, I decided to create the sensitive non-capturing group(?-i:Sub|Function)-
Any key-words must be followed by, at least, one, horizontal or vertical, White Space character (
\s+) -
Finally, after the reset behaviour, due to the
\Ksyntax, we display, in the Function List panel, either :-
The name of current subroutine or function (
\w+, in case of key-words Sub/Function -
All the rest of current line, only,
(?-s:.+), in case of key-word'\*
-
Do hope, you’ll like this interpretation ;-))
In all this discussion, we’re using, in regexes, either, the
\sand/or the\hsyntaxes. We could also add the\vsyntax ! What they, all, refer to ?Well, from the Wiki article :
https://en.wikipedia.org/wiki/Whitespace_character
we hear of the
White Spacedefinition, which is any character or series of characters, that represent horizontal or vertical space in typography. They, all, have the Unicode property “WSpace=Y”.
So, strictly :
- The Shorthand Character Class
\s, used in the N++ Boost regex engine, matches any Vertical or HorizontalWhite Spacecharacter, of the list below :
U+0009 CHARACTER TABULATION U+000A LINE FEED U+000B VERTICAL TABULATION U+000C FORM FEED U+000D CARRIAGE RETURN U+0020 SPACE U+0085 NEXT LINE U+00A0 NO-BREAK SPACE U+1680 OGHAM SPACE MARK U+2000 EN QUAD U+2001 EM QUAD U+2002 EN SPACE U+2003 EM SPACE U+2004 THREE-PER-EM SPACE U+2005 FOUR-PER-EM SPACE U+2006 SIX-PER-EM SPACE U+2007 FIGURE SPACE U+2008 PUNCTUATION SPACE U+2009 THIN SPACE U+200A HAIR SPACE U+2028 LINE SEPARATOR U+2029 PARAGRAPH SEPARATOR U+202F NARROW NO-BREAK SPACE U+205F MEDIUM MATHEMATICAL SPACE U+3000 IDEOGRAPHIC SPACEMoreover, it, also, matches the NON-WhiteSpace character, below :
U+200B ZERO WIDTH SPACE- The Shorthand Character Class
\h, used in the N++ Boost regex engine, matches any HorizontalWhite Spacecharacter, of the list below :
U+0009 CHARACTER TABULATION U+0020 SPACE U+00A0 NO-BREAK SPACE U+1680 OGHAM SPACE MARK U+2000 EN QUAD U+2001 EM QUAD U+2002 EN SPACE U+2003 EM SPACE U+2004 THREE-PER-EM SPACE U+2005 FOUR-PER-EM SPACE U+2006 SIX-PER-EM SPACE U+2007 FIGURE SPACE U+2008 PUNCTUATION SPACE U+2009 THIN SPACE U+200A HAIR SPACE U+202F NARROW NO-BREAK SPACE U+205F MEDIUM MATHEMATICAL SPACE U+3000 IDEOGRAPHIC SPACEAs before, it, also, matches the NON-WhiteSpace character, below :
U+200B ZERO WIDTH SPACE- The Shorthand Character Class
\v, used in the N++ Boost regex engine, matches any VerticalWhite Spacecharacter, of the list below :
U+000A LINE FEED U+000B VERTICAL TABULATION U+000C FORM FEED U+000D CARRIAGE RETURN U+0085 NEXT LINE U+2028 LINE SEPARATOR U+2029 PARAGRAPH SEPARATORAnd, logically, the
\sclass character is identical to the union of the two classes\hand\v!!
Luckily, most of these characters are never found, in Western scripts. Then, practically, we, just, have to remember that :
-
The
\ssyntax is, generally, identical to the simple class[\t\n\r\x20] -
The
\hsyntax is, generally, identical to the simple class[\t\x20] -
The
\vsyntax is, generally, identical to the simple class[\n\r]
Cheers,
guy038
BTW, MaDill, the MAPJe71’s last regex does work, properly, on my “old” Win WP configuration !
-
-
Thank you for the explanation.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login