How to see hex value of character next to cursor?
-
@Blafulous-Crassley said:
How do I find the hex value of a character to the right of my cursor?
Some time ago, in response to another question, @Scott-Sumner used the PythonScript plugin (*) to create a callback which will constantly show the current character’s character-code in hex and decimal.
Using the same script, but skipping the editor callback, would allow you to do it on-demand rather than “live”.
At one time, I had tried to start getting it to work with UTF-8 unicode characters, but I had moved on from there without remembering that I’d never finished it. Who knows, as I find time in the near future, I may go back to playing with that
(*: If you need help installing PythonScript, see @Meta-Chuh’s Guide)
-
@PeterJones said:
Using the same script, but skipping the editor callback, would allow you to do it on-demand rather than “live”.
Technically, you would have to replace the line
editor.callback(callback_sci_UPDATEUI, [SCINTILLANOTIFICATION.UPDATEUI])with
callback_sci_UPDATEUI(None) -
Okay, I’m addicted. I got it somewhat debugged. This will work up to U+FFFF as a one-shot. (Or comment out the “on-demand” line and uncomment the “editor.callback” line to get it “live”)
# encoding=utf-8 def callback_sci_UPDATEUI(args): c = editor.getCharAt(editor.getCurrentPos()) if c < 1 or c > 255: p = editor.getCurrentPos() q = editor.positionAfter(p) s = editor.getTextRange(p,q).decode('utf-8') try: c = ord(s) except: txt = "'{}' = {} char: ".format(s.encode('utf-8'), len(s)) for ch in s: c = ord(ch) txt = txt + " HEX:0x{0:04X} DEC:{0} '{1}'".format(c, unichr(c).encode('utf-8') if c not in [13, 10, 0] else 'LINE-ENDING' if c != 0 else 'END-OF-FILE') notepad.setStatusBar(STATUSBARSECTION.DOCTYPE, txt) return try: info = "HEX:0x{0:04X} DEC:{0} '{1}'".format(c, unichr(c).encode('utf-8') if c not in [13, 10, 0] else 'LINE-ENDING' if c != 0 else 'END-OF-FILE') except ValueError: info = "HEX:?? DEC:?" notepad.setStatusBar(STATUSBARSECTION.DOCTYPE, info) callback_sci_UPDATEUI(None) # per https://notepad-plus-plus.org/community/topic/17799/, want on-demand # editor.callback(callback_sci_UPDATEUI, [SCINTILLANOTIFICATION.UPDATEUI]) # per https://notepad-plus-plus.org/community/topic/14767/, want live -
Okay, I found the way to make it compatible with U+10000 and above:
# encoding=utf-8 def get_wide_ordinal(char): '''https://stackoverflow.com/a/7291240/5508606''' if len(char) != 2: return ord(char) return 0x10000 + (ord(char[0]) - 0xD800) * 0x400 + (ord(char[1]) - 0xDC00) def callback_sci_UPDATEUI(args): c = editor.getCharAt(editor.getCurrentPos()) if c < 1 or c > 255: p = editor.getCurrentPos() q = editor.positionAfter(p) s = editor.getTextRange(p,q).decode('utf-8') c = get_wide_ordinal(s) else: s = unichr(c) try: info = "'{1}' = HEX:0x{0:04X} = DEC:{0} ".format(c, s.encode('utf-8') if c not in [13, 10, 0] else 'LINE-ENDING' if c != 0 else 'END-OF-FILE') except ValueError: info = "HEX:?? DEC:?" notepad.setStatusBar(STATUSBARSECTION.DOCTYPE, info) callback_sci_UPDATEUI(None) # per https://notepad-plus-plus.org/community/topic/17799/, want on-demand # editor.callback(callback_sci_UPDATEUI, [SCINTILLANOTIFICATION.UPDATEUI]) # per https://notepad-plus-plus.org/community/topic/14767/, want live -
Addicted. Definitely addicted. :)
-
Hello, @PeterJones, and All,
I’ve tried your script, on a text, containing Unicode characters over the BMP => Just perfect !
Just a question : In which case the END-OF-FILE string is displayed in the status bar ? I initially thought it could be when opening a new-1 empty file but not !
Cheers,
guy038
-
there is no end-of-file (EOF) string/char.
EOF is more like a status like in reading a file.
If the filehandle comes to the end of a file it sets it status EOF to true
to inform that the end is reached.Or did I misunderstand your question?
-
@guy038 said:
In which case the END-OF-FILE string is displayed in the status bar ?
In @Scott-Sumner’s original, END-OF-FILE would show if you were at the last character of the file, or if the file were empty. However, my changes to try to trap the unicode characters caused the EOF-result to give errors.
To fix that bug, change
if c < 1 or c > 255:to
if c < 0 or c > 255: -
@Ekopalypse said:
there is no end-of-file (EOF) string/char.
@guy038 was talking about the
else 'END-OF-FILE'that should go to the status bar – ie, output of the program, not input from the file.The
editor.getCharAt()apparently returns 0 if thegetCurrentPos()is at the end of the file. But because I introduced the bug ofc<1instead ofc<0after that line, the0condition in theinfo = ...was never hit, so my code didn’t recognized the end of the file. (It was actually printing the untrapped error to the PythonScript console, but I hadn’t seen it, because I never tried testing the end-of-file condition while making my unicode-capable version of the script.) -
-
Hello, @PeterJones, @ekopalypse, and All,
So, finally, using your modification :
if c < 0 or c > 255:and your line, slightly modified :
info = " {1} 0x{0:04X} - {0} ".format(c, s.encode('utf-8') if c not in [13, 10, 0] else 'LINE-END' if c != 0 else 'FILE-END')Everything is OK ! And I’ve never met the error exception :-))
except ValueError: info = "HEX:?? DEC:?"For instance :
-
Open a new file
-
Running the script shows
| FILE-END 0x0000 - 0', in the status bar -
Add a
€Euro character -
With cursor right before the currency symbol, I get
| € 0x20AC - 8364' -
With cursor right after the currency symbol, I get, again,
| FILE-END 0x0000 - 0' -
Now, hit the
Enterkey -
Move the caret right after the
€=> This time, it answers| LINE-END 0x000D - 13' -
Hit the
Down arrowkey. Again, we get| FILE-END 0x0000 - 0'
An other example :
- In a new file, I added two characters, which give the same resulting glyph
é!
é // LATIN SMALL LETTER E WITH ACUTE é // LATIN SMALL LETTER E + DIACRITICAL COMBINING ACUTE ACCENT-
With cursor right before the first single
écharacter, it displays| é 0x00E9 - 233' -
With cursor right before the
égroup of two characters, it displays| e 0x0065 - 101' -
Moving the cursor rightwards
1position, “inside” theégroup of two characters, it displays| ́ 0x0301 - 769', as expected !
Refer to the complete list of the Combining Diacritical marks, below, for information :
http://www.unicode.org/charts/PDF/U0300.pdf
BR
guy038
-
-
@Alan-Kilborn said:
Addicted. Definitely addicted. :)
I am admittedly addicted. But did you see that it helped me use Notepad++ to find a hidden character in someone else’s code? That right there justifies the time I put into it, in my opinion.
-
I recently found it handy to modify Peter’s script above (the version that runs “on demand”).
Often when dealing with a “weird” character, I want to get rid of it and replace it with something else, sometimes a different character, and sometimes a string.
The following modified version of the script shows the character codes (as before) but then asks you if you want to replace all occurrences of the character, and if you do, prompts you for the replacement.I called it
CharacterCodeShowWithOptionalReplace.py:# -*- coding: utf-8 -*- from Npp import editor, notepad class CCSWOR(object): def get_wide_ordinal(self, char): # see https://stackoverflow.com/a/7291240/5508606 if len(char) != 2: return ord(char) return 0x10000 + (ord(char[0]) - 0xD800) * 0x400 + (ord(char[1]) - 0xDC00) def __init__(self): c = editor.getCharAt(editor.getCurrentPos()) if c < 1 or c > 255: p = editor.getCurrentPos() q = editor.positionAfter(p) s = editor.getTextRange(p,q).decode('utf-8') c = self.get_wide_ordinal(s) else: s = unichr(c) try: info = "'{1}' = HEX:0x{0:04X} = DEC:{0} ".format(c, s.encode('utf-8') if c not in [13, 10, 0] else 'LINE-ENDING' if c != 0 else 'END-OF-FILE') except ValueError: info = "HEX:?? DEC:?" notepad.messageBox(info, 'Character at caret was...') matches = [] editor.search(s, lambda m: matches.append(m.span(0))) user_input = notepad.prompt('Replace the character with something else (all {} occurrences)?\r\n' '(Leave box empty to DELETE the character)'.format(len(matches)), 'Replace it?', '') if user_input == None: return # Cancel editor.replace(s, user_input) if __name__ == '__main__': CCSWOR()Maybe it will be useful to someone else.
Perfect usage: Replace “curly double-quotes” with straight ones. :-) -
@Alan-Kilborn said in How to see hex value of character next to cursor?:
Perfect usage: Replace “curly double-quotes” with straight ones. :-)
I wouldn’t call that “perfect”, since
[“”]=>"does it perfectly well without scripting. :-) Assuming you noticed they were curly in the first place.Despite that, I do think it’s a nice extension to my script. :-)
-
I guess the “curly” thing was a bit contrived… :-)
I’ll tell you my real use case of recent origin:
Getting rid of some invisible LTR marks in a bunch of Skype conversation logs–ugh. -
I posted an updated script for this topic, HERE.
-
Can someone clarify how to actually run this script? I’ve followed the installing PythonScript [Guide](link https://community.notepad-plus-plus.org/topic/17256/guide-how-to-install-the-pythonscript-plugin-on-notepad-7-6-3-7-6-4-and-above), but as I search around there are also references to installing the Python Script plug-in, but that’s not available in my version of npp (maybe because it is 64 bit?).
Anyway, if I followed that PythonScript Guide, and have the plugins\PythonScript folder set up, how do I then run the script? I’ve also installed the NppExec plug-in, but don’t immediately see how that could be used.
I seem to be missing something. Can anyone give me a hint?
moderator: fixed link to match modern forum linking
-
@Jeff-Heath
Once you have installed the PythonScript plugin, you should
see an additional entry in the plugin menu.
In that menu, there is a menu item called Show Console.
Click on it, and if the console opens without reporting a problem, the installation of PS was successful.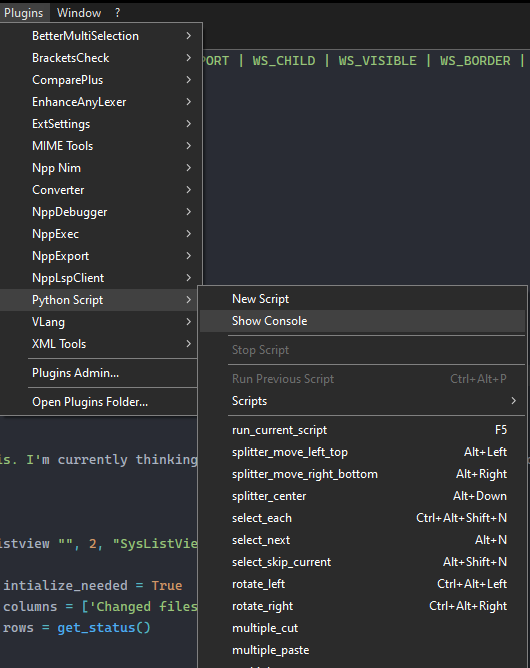
To create a new script, use the menu again and select New Script,
Butmake sure the directory it points to is your...plugins\Config\PythonScript\scripts\directory.
Give it a meaningful name and copy the code into it.
Save it.
Now it should appear in the list of the Scripts menu item.
If you want it to be accessible in the PS main menu,
you have to use the PS menu option Configuration…
and add it to the main menu section. That’s it.
Now you can run it by clicking on it or assigning a shortcut, etc. -
I finally noticed in the Plugins Admin that the Python Script plugin (version 1.3) that I installed manually (with the link above) was listed under the “Incompatible” tab. But I was able to install it on the “Updates” tab to version 2. Now I have an element “Python Script” on the Plugins menu which allows me to create a new script, etc. So I think I can now try to progress and try a few more things.
But why was “Python Script” not available in the Plugins Admin in the first place? All it has is “Python Indent”. I certainly don’t want to have to manually install 1.3 then do the update the next time.
-
That sounds strange, because normally you have it available.
I’ve never had a problem installing it, and I do it this way with every new npp version. I think I’ve been doing this since 7.9.5, which is how my automated tests run.
The only reason I can think of why it doesn’t show up in the Available tab is if npp thinks it has already found something.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login