How to Find "�" in multiple notepad++ files ?
-
hello. I don’t know what is this
�but I need to delete from all my files. I try to simple find it, but is not find it. I must deleted one by one from all files.any idea ?
-
So, if you were to read a UTF-8 file assuming some other 8-bit encoding (like ANSI), those three one-byte characters could appear when it’s reading an actually three-byte character.
Specifically, those are the bytes
EF BF BD, which are the three-byte encoding forU+FFFD, which is the Unicode “REPLACEMENT CHARACTER”: � is “used to replace an incoming character whose value is unknown or unrepresentable in Unicode”. So what I’m guessing really happened is that whatever generated your text file got confused about some character (it was told to output a character it didn’t know), so it output UTF-8 for the �; you then read it with an ANSI-type encoding, rather than reading it in UTF-8, so it showed up as three characters, rather than a single Unicode character �. Probably searching for the three characters�in all open files, or search-in-files option, is treating those as three valid unicode characters, so looking for more than those three bytes, and it never finds them.You might be able to search for
\x{fffd}and replace it with whatever replacement you want for the REPLACEMENT CHARACTER. But it probably depends on what encoding you have Notepad++ set to default to, and whether you try to autodetect encoding, whether that search-and-replace will work for you.As a hint: anytime you see two three random-seeming bytes that are in the 0x80-0xFF range in a row, think “this was probably UTF-8, but incorrectly read as ANSI”; those random 8bit bytes are just what happen when you misinterpret UTF-8.
-
Followup: one thing you can do to find out what a random group of those, like
�, represents:- Create a new empty file in Notepad++
- Set Encoding > ANSI (not Encoding > Convert to ANSI)
- Paste those characters in
- Set Encoding > UTF-8 (not Encoding > Convert to UTF-8)
- The UTF-8 text is now visible, and hopefully more readable
If you follow that sequence with
�, you will get�Now try it yourself. With the byte sequence
ŃÅťëƤÄđ┼┿, what obfuscated text would those bytes be if properly inerpreted as UTF-8? -
Hello , @Vasile-caraus, @peterjones and All,
@vasile-caraus, I first thought that you probably, wrongly, saw the Byte Order Mark (
BOM) of an Unicode encoded file. Normally, these three or two bytes, at the very beginning of an Unicode file, are not part of file and are invisible in any decent text editor. This character, of Unicode code-point\x{FEFF}, is used to signal the right bytes order, in Unicode files !Refer to the link, below, for further information :
https://en.wikipedia.org/wiki/Byte_order_mark#Byte_order_marks_by_encoding
However, I was totally wrong, because, in the first row of that table, the three bytes of the BOM (
EF BB BF) in anUTF-8encoded file ( column 2 ), correspond to the three charsin aWindows-1252encoded file ( column 4 ) which is the usualANSIencoding for Latin languages.Therefore, it seemed quite different from your three bytes
�that you’ve noticed ! And I was wondering about this difference, without finding any satisfying solution :-(( Luckily, @peterjones did find the correct explanation !
Regarding the Unicode Replacement character, refer to that link, below :
https://en.wikipedia.org/wiki/Specials_(Unicode_block)#Replacement_character
The fact that you see the three bytes
�, also means that you currently use theWindows-1252encoding, as defaultANSIencoding, for all your Non-Unicode programs. To verify this statement, could you verify that the contents of the table, below :https://en.wikipedia.org/wiki/Windows-1252
is identical to the table displayed when you click on the menu option
Edit > Character Panel, from within Notepad++ ?
May be, this link to this tiny in-line
UTF-8tool could be of some interest :http://www.cogsci.ed.ac.uk/~richard/utf-8.cgi?
-
First, read the few notes, at the end of the screen
-
Secondly, choose the representation of the searched Unicode character, selecting the appropriate radio button, from the list :
- Character
- Hex code-point
- Decimal code-point
- Hex UTF-8 bytes
- Octal UTF-8 bytes
- UTF-8 bytes as Latin-1 characters
- Hex surrogates
-
Thirdly, type in that representation
-
Click on the
Gobutton => All the representations, of the Unicode char searched, will be displayed
For instance :
-
Select the
Hex UTF-8 bytesradio button, first -
Type in
EF BF BD, with a space between each byte -
Click on the
Gobutton
=> You’ll get all the representations of the Unicode
ReplacementcharacterNow :
-
Select the
Hex UTF-8 bytesradio button, first -
Type in
EF BB BF, with a space between each byte -
Click on the
Gobutton
=> This time, you’ll get all data, regarding the Unicode
Byte Order Markcharacter. Note that, if this character is found at any location, different from the very beginning of current file, it is known as the UnicodeZERO WIDTH NO-BREAK SPACEcharacter !Best Regards,
guy038
-
-
The safest and easiest way to find Unicode Characters such as
�or�is to use Adobe Dreamweaver. Use the option Find in Folder… and select the folder that you want to look up. It always find unicode characters. Also, you can use the Replace section. Works wonderful !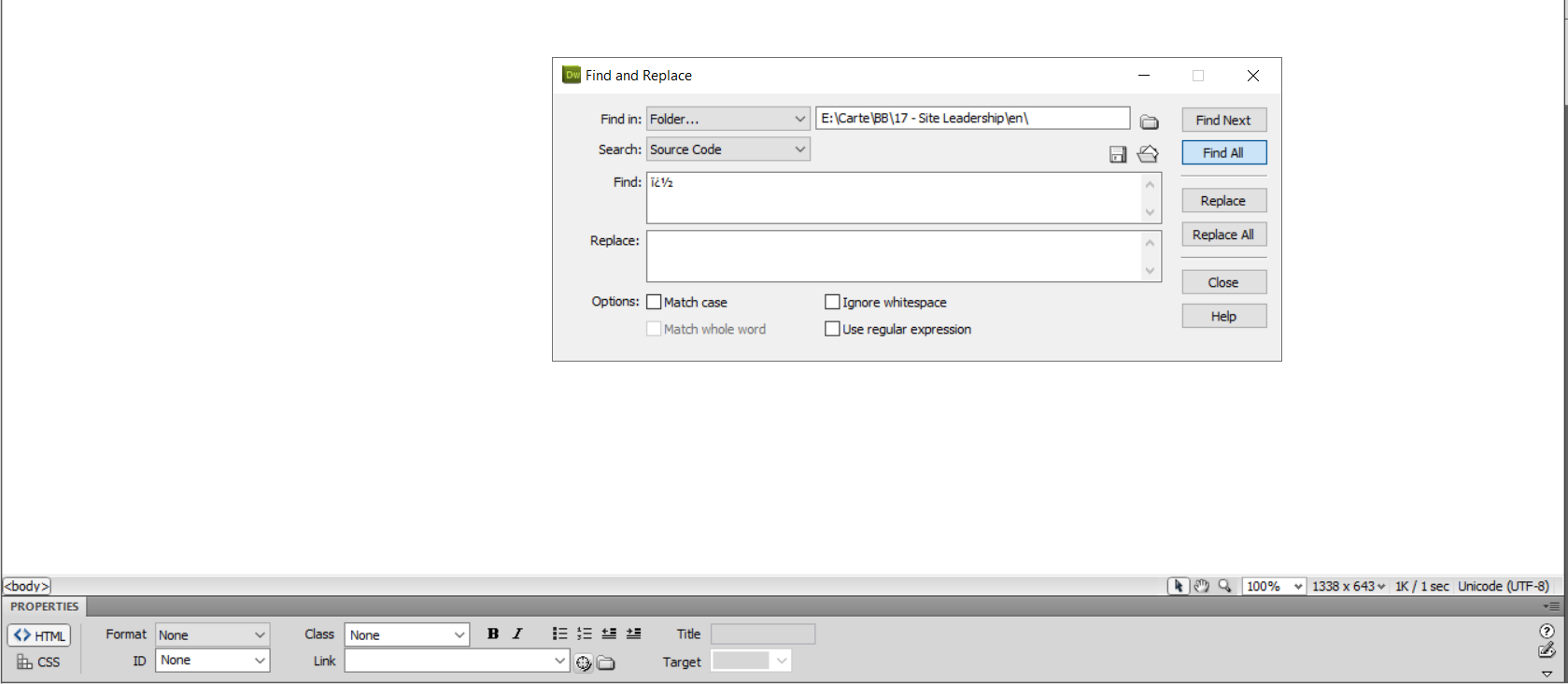
-
Another VERY GOOD method to find
�or�unicode characters is by using grepWin tool. You have to check the box “treat file as binary” so grepWin won’t try to detect the encoding.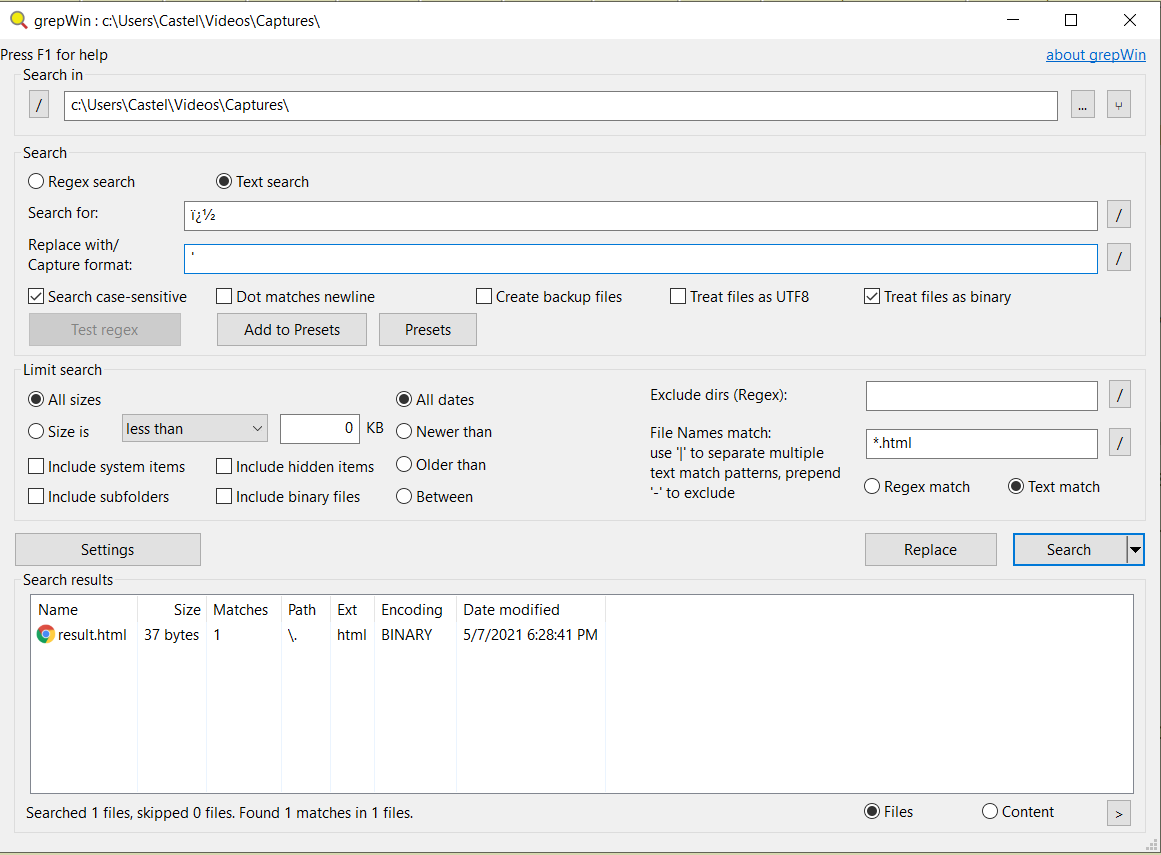
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login