Looking for a freelancer to develop a plugin: Misspelled Word Counter
-
I’m curious, it seems you already have a plugin that does this.
At least the screenshot implies you have such a plugin.
What’s wrong with it?
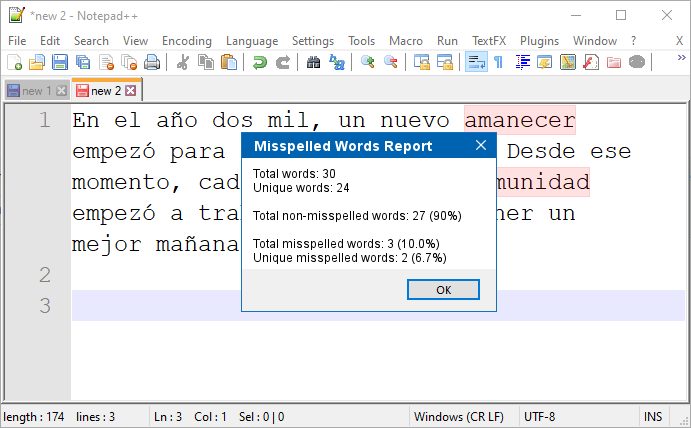
If it is a mock, then a pythonscript solution, which means you
need to install PythonScript plugin, might look like this.from Npp import editor, notepad words = [] indicator_id = 19 # used by DSpellChecker if I'm correct def collect_words(m): span = m.span() words.append((editor.getTextRange(*span), span)) editor.research('\w+', collect_words) error_words = [word for word, pos in words if editor.indicatorValueAt(indicator_id, pos[0])] total = len(words) unique = len(set(words)) misspelled = len(error_words) misspelled_unique = len(set(error_words)) report = '''Total words: {0} Unique words: {1} Total non-misspelled words: {2} ({3:.1%}) Total misspelled words: {4} ({5:.1%}) Unique misspelled words: {6} ({7:.1%}) '''.format(total, unique, total-misspelled, # non-misspelled (float(total-misspelled) / total) if misspelled else 1, # non-misspelled % misspelled, (float(misspelled) / total) if misspelled else 0, misspelled_unique, (float(misspelled_unique) / total) if misspelled_unique else 0) notepad.messageBox(report,'Misspelled Words Report') -
Umm, did you just short-circuit people’s ability to make money on this?? :-)
-
?? hää ??
-
Ohhhh - I see. @Miguel-Lescano, please consider donating to @donho instead.
-
@Ekopalypse Hi! Yes, it’s just a mockup made with GIMP. I like creating mockups to make my ideas clearer.
Your script worked! Can I buy you a drink? How do I donate to @donho?
-
BTW, it seems to only take into account misspelled words that are currently on screen. It does not take into account those offscreen… Is there any way to solve this?
-
@Miguel-Lescano said in Looking for a freelancer to develop a plugin: Misspelled Word Counter:
It does not take into account those offscreen… Is there any way to solve this?
The spell check plugin doesn’t highlight words offscreen that are misspelled. Why would somebody need them highlighted if they can’t see them? :-)
Your need is different, though.
I think the code would have to forget about the plugin (except for its dictionary database) and do its own checking.
-
@Alan-Kilborn I see. Here’s how I do this calculation manually:
- I go to DSpellCheck > Additional actions > Copy all misspelling to clipboard. This copies all unique misspellings to the clipboard, one per line.
- I paste the result to a new document. I check how many lines the document has, or I just double-click on the status bar to pull up the summary and see how many words it has.
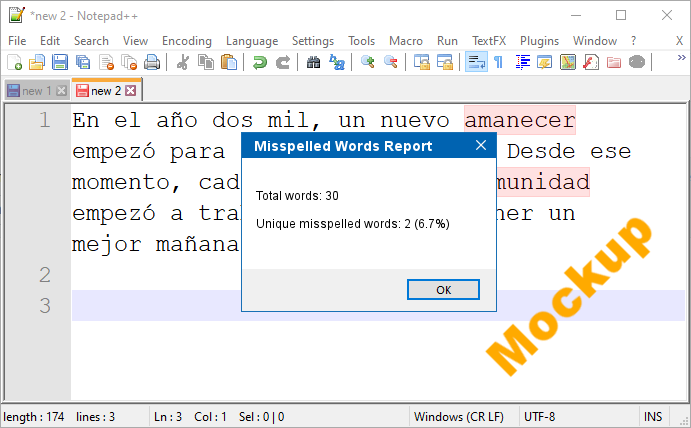
- I then open the Windows calculator and calculate the percentage of unique misspellings vs. total length of the text. This number is actually the most important to me: The percentage of unique misspellings.
Maybe the script/plugin can also use the “copy all misspelling to clipboard” command, count the number of words in the clipboard and use that number to calculate the percentage of unique misspelled words vs. total number of words? This is the most important number of all. So, something like this would be enough:
I guess I should clarify what I’m trying to achieve. I’m a Spanish tutor on italki and I write short stories for my students. I compiled my own list of the top 5,000 word forms a student needs to know in order to watch Netflix TV shows from Latin America and Spain. (How I built this list is a good story… for another day). So I want to be able to write stories that contain no more than 2.0% of unique words outside a particular level, in 5 levels:
Top 1K word forms
Top 2K word forms
etc…To check in real time if I’m using a word outside a list, I downloaded some DSpellCheck dictionaries (Hunspell) and replaced the content of the .dic file with my own word lists. I chose dictionaries with the letters A, B, C, D and E for this purpose:
“Arabic” is the top 1K word forms in Spanish
“Belarusian” is the top 2K
“Catalan” is top 3K
“Danish” is top 4K
“English (Australia)” is top 5KThis way I can write short stories for my students knowing that I’m focusing on common words instead of rare words. I keep the number of unique words outside each list at 2% or less, because that’s the top number of unknown words you can tolerate while reading and still be able to understand everything. (Extensive reading).
So yeah, actually I could work with a plugin that ignores DSpellCheck, if that plugin contains the lists I’ve created.
-
@Miguel-Lescano said in Looking for a freelancer to develop a plugin: Misspelled Word Counter:
I guess I should clarify what I’m trying to achieve.
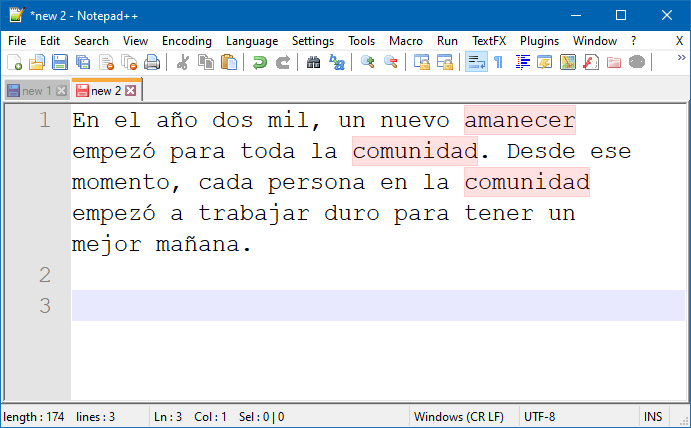
Now I understand why “amanecer” and “comunidad” were marked as misspelled words, when in fact those words were fine. Actually quite common words.
Regards/Saludos
-
Yea, really your “spec” may be a bit too bound up in your current usage.
If I were you, I’d forget about the DSpellCheck plugin stuff and what you’re currently doing, and just say what you want/need (you have started doing this, so, that’s good). -
@Miguel-Lescano said in Looking for a freelancer to develop a plugin: Misspelled Word Counter:
Ok, the goal is to keep the use of “not ordinary” words in the stories within a defined limit.
What I do not understand is why you need 5 “TOP” word lists?
I would assume that the TOP 1K words are also included in the TOP 5K list, right?
I’m currently assuming that “Arabic, Belarusian”… is referring to A,B,…
and that all are ONLY lists of Spanish words.Regarding a script, where I currently assume that this can be realized,
what is the best way to realize this for you?Possibility 1: Call the script manually and display it as a dialog like in the mockup?
Possibly output in the console for copy/paste operations?Possibility 2: “Realtime Analysis” - here a dialog would be annoying,
unless the dialog should only be shown when the limit is reached.
Possibly change the filetype, the first field in the status bar, with the “realtime data”?Since I am currently still at work (lunch break), I would give it a try in about 6 hours.
Regarding the Donate, just click on this link.
-
@Ekopalypse Hi, thank you for your response.
Yes, that’s the goal. To write stories with limited vocabulary. But it’s very difficult to write interesting stuff if you completely avoid words outside a particular list, so I want to keep the number of unique words outside a list under control. I’m a big fan of Stephen Krashen’s language acquisition hypothesis, and he’s also a promoter of extensive reading. Extensive reading is defined as reading at 95-98% comprehension. BTW, you can read some of my stories here: www.spanishinput.com. At first my goal was to write stories in 3 levels: 5,000 words, 10,000 words and 20,000 words, but then I realized that for most students it’s better to focus on the first 5,000 words. So now I’m aiming at 5 levels: Top 1K, top 2K, 3K, 4K and 5K.
So… I need 5 lists because I’m going to write stories in 5 different levels. For beginners, the stories will focus on the top 1K words, then the second level will have stories using the top 2K words, and so on. You’re correct. The top 1K words are also included in the top 5K list.
Ideally, I would have a Hunspell dictionary called “Spanish top 1000”, another one called “Spanish top 2000” and so on. However, I could not find a way to create new Hunspell dictionaries with custom names, so I installed some of the existing dictionaries and replaced their .dic files with my own word lists. Yes, it’s all Spanish. I chose one language starting with A, another one with B, and so on to make it easier for me to remember which one represents what.
The one starting with A represents the 1000 Spanish word list.
The one starting with B represents the 2000 Spanish word list
and so on.Yes, a real time analysis tool would be amazing! I actually asked the owner of the easypronunciation.com website to create this tool for me:
https://easypronunciation.com/en/spanish-word-frequency-counter-real-time
But it has a few problems, including:- The CSS is messy and the highlight does not align properly with the text
- No way to save your work
- It’s slow, because the analysis runs on the server side. It does not run on your browser.
So I’m looking for a local, offline solution. It took me a long time to figure out how to make Notepad++ highlight the words I need to be highlighted by replacing the Hunspell .dic files with my own lists.
When you mention the filetype, are you referring to the field that says “Normal text file”? If this could be changed to display the info I need, it would be fantastic! I know people have asked for a real-time word counter to be included in Notepad++ for a long time, so I assumed it was not possible. That’s why I was asking for a script to create a dialog. But if it’s possible to do this realtime, yes, that’s even better!
-
here my first version.
from Npp import notepad, editor, NOTIFICATION, SCINTILLANOTIFICATION, STATUSBARSECTION, MODIFICATIONFLAGS import os class WORD_CHECKER: def __init__(self): self.report = ('Total: {0:<5} ' 'Unique: {1:<5} ' 'Total non-misspelled: {2:<5}({3:.1%}) ' 'Total misspelled: {4:<4}({5:.1%}) ' 'Unique misspelled: {6:<4}({7:.1%})') editor.callbackSync(self.on_modified, [SCINTILLANOTIFICATION.MODIFIED]) notepad.callback(self.on_buffer_activated, [NOTIFICATION.BUFFERACTIVATED]) current_dict_path = os.path.join(notepad.getPluginConfigDir(), 'Hunspell') current_dict_file = os.path.join(current_dict_path, 'Spanish TOP972.dic') with open(current_dict_file, 'r') as f: self.current_dict = f.read().splitlines()[1:] # skip length entry self.on_buffer_activated({}) def check_words(self): words = [] editor.research('\w+', lambda m: words.append(m.group())) error_words = [word for word in words if word.lower() not in self.current_dict] # insensitive word check total = len(words) unique = len(set(words)) misspelled = len(error_words) misspelled_unique = len(set(error_words)) notepad.setStatusBar(STATUSBARSECTION.DOCTYPE, self.report.format(total, unique, total-misspelled, # non-misspelled (float(total-misspelled) / total) if misspelled else 1, # non-misspelled % misspelled, (float(misspelled) / total) if misspelled else 0, misspelled_unique, (float(misspelled_unique) / total) if misspelled_unique else 0)) def on_modified(self, args): if ((args['modificationType'] & MODIFICATIONFLAGS.INSERTTEXT) or (args['modificationType'] & MODIFICATIONFLAGS.DELETETEXT)): self.check_words() def on_buffer_activated(self, args): self.check_words() WORD_CHECKER()I assume your customized hunspell file is in
.\plugins\Config\Hunspelland is a file
having one word per line? If this is not the case, then please post a few lines how this file look like.
Btw. to get a Spanish Top 1000 dict, just name it so. I named mineSpanish TOP972.dicand this resulted in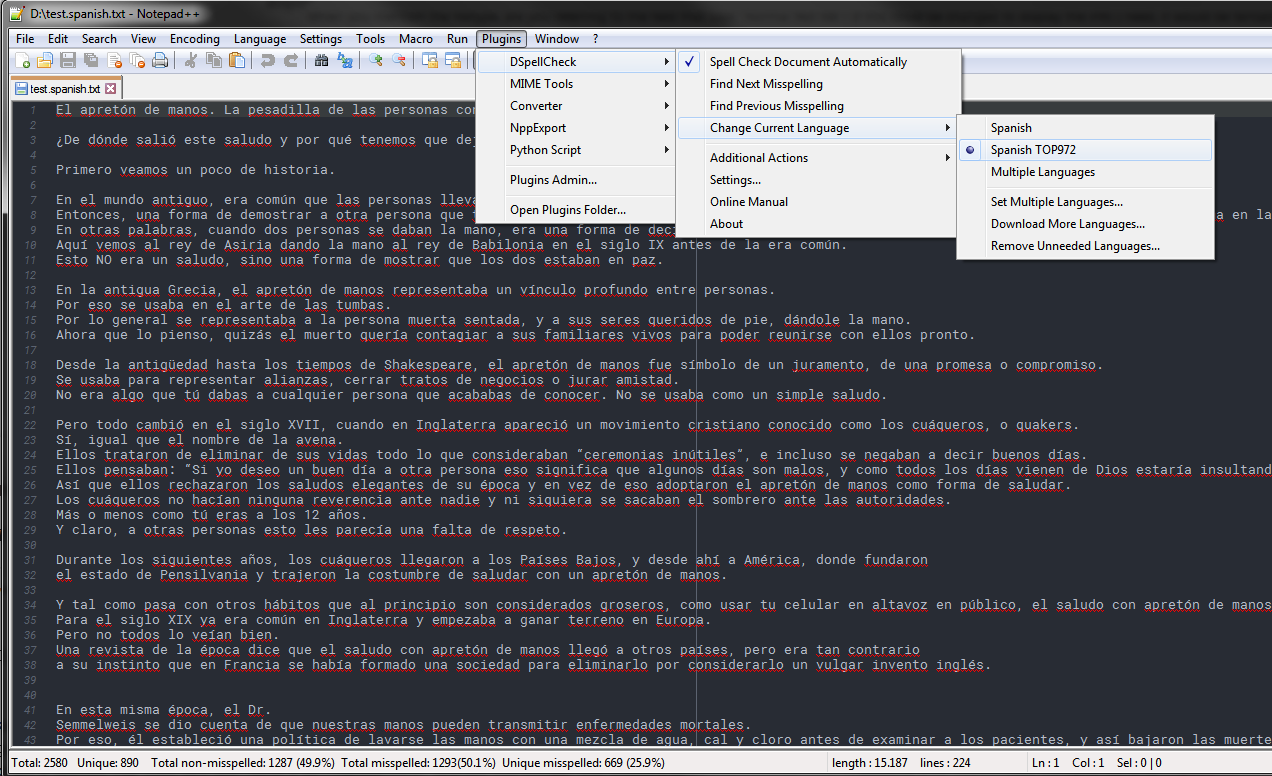
Open question are
- How do you plan to switch between Top??? dictionaries. Is this something you do while editing a story?
- Currently, all open documents are affected. Do you want a toggle switch mechanism?
Known issues:
- Currently it seems that my script calculates misspelled words differently than DSpellCheck,
because with the example text I see 669 unique misspelled words whereas DSpellCheck reports 620.
I’ll check this out.
If something does not work as expected, take a look into the console (Plugins->PythonScript-Show Console)
to see if there is an error logged. And if you have something else in mind, let me know. -
Hello, @miguel-lescano and All,
Did you notice that, since the version
1.4.16of DSpellCheck, a new option to bookmark all lines, containing misspelled words, is available for further process, viaSearch > Bookmark?- Support bookmarking lines containing misspelled words via additional actions
Also, since the
1.14.0version, this hidden option, below, could be of some interest to you :- Add hidden option
Word_Minimum_Lengthto disable checking of words with length less or equal to its value
For any
DSpellCheckrelease, refer to :https://github.com/Predelnik/DSpellCheck/releases
Best Regards,
guy038
-
@Ekopalypse Thanks a lot! It’s fantastic! I just had to change the name of the dictionary file inside the .py file and it worked!
Yes, my customized dictionary files are in C:\Users\Miguel\AppData\Roaming\Notepad++\plugins\config\Hunspell
And yes, it has one word per line, starting with the number of words. Here’s how it looks:
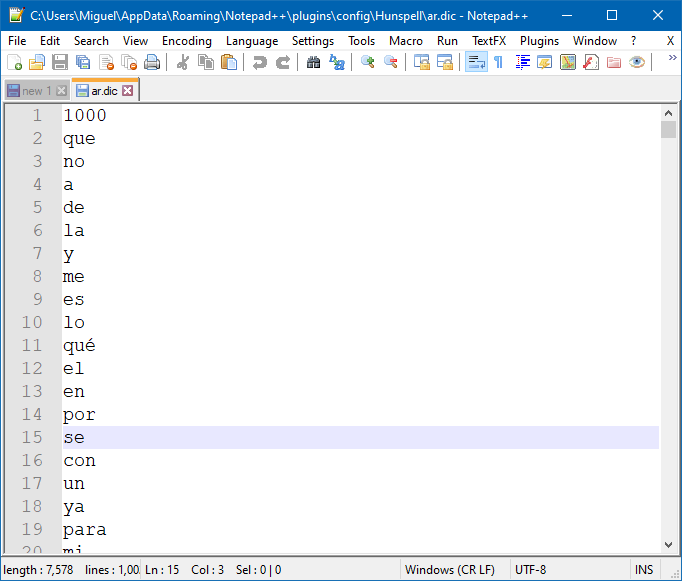
Your tip to just change the name of the .aff and the .dic files worked! The weird thing is, if I copy the .aff from arabic and just rename it, say, “Spanish TOP1000”, it works, but if I change the contents of the .aff file it treats all words with diacritics as misspellings. Strange. I guess I’ll just keep the content of the arabic .aff file. What’s supposed to be inside the .aff, anyway? Without an .aff file I noticed the dictionary won’t appear, and if I just type “Spanish” inside the .aff file it, again, marks all words with diacritics as misspellings.
I don’t switch a lot between dictionaries when editing a story. I decide which level I’m going for and just go for it, unless I decide the story is too difficult to write at the level I chose and change the level. But I see I can just make 5 copies of the script and give them different names pointing to different dictionaries.
Having all documents affected is not a problem. I’m very unlikely to be working on two stories for different levels at the same time.
And yes, I noticed it calculates misspellings a bit different. The differences from DSpellCheck default settings are that DSpellCheck ignores:
-Numbers
-Words containing numbers
-ALL CAPS words, such as USA or V&M.
-Words containing _There also seem to be some non-visible characters being counted as misspellings. The file I’m linking to here has 37 misspellings, but the script counts 38.
https://www.spanishinput.com/uploads/1/1/9/0/11905267/37_misspellings.txtThanks a lot for your help! I’ve just donated to the link you provided. The donation buttons didn’t play nice with my Chrome cookies, so I had to open an incognito window.
-
@guy038 Thanks for the tips!
-
I have already found two problems, replacing the regex string
\w+with[[:alpha:]]+
should eliminate many false positives and in addition, creating an
insensitive error_words list will reduce the number of unique errors,
because then Amèrica and amèrica are the same, which brings me to
the first question, which encoding do you use?When I open the uploaded file, I see the following

If possible, you should use utf8 encoded files.
As far as the aff files are concerned and as far as I understand it, they
are basically rule files that the hunspell engine tells how to treat the file
and how it should treat certain rules for words with special notation.But treat this information with skepticism, since I only started to
investigate hunspell yesterday.
I will try to see if I can find more information about the aff format,
maybe this will help to get the same results as hunspell itself.By the way, if I were you, I would use the spanish.aff as a template for all your TOP dictionaries.
The donation buttons didn’t play nice with my Chrome cookies, so I had to open an incognito window.
@donho, maybe something you are interested in??
-
ok, after some more research I guess I can confirm my opinion on
affix files. They are more or less rule files. In your case there is only
a few lines needed and these can be the same for all your 5 aff
files. If you want to go into detail about the file format, here the
link to the description.My aff file looks like this
SET UTF-8 FLAG UTF-8 TRY aeroinsctldumpbgfvhzóíjáqéñxyúükwAEROINSCTLDUMPBGFVHZÓÍJÁQÉÑXYÚÜKWHere the updated script which gets the same result as DSpellCheck on the example text I used earlier.
from Npp import notepad, editor, NOTIFICATION, SCINTILLANOTIFICATION, STATUSBARSECTION, MODIFICATIONFLAGS import os class WORD_CHECKER(object): def __init__(self): self.report = ('Total: {0:<5} ' 'Unique: {1:<5} ' 'Total non-misspelled: {2:<5}({3:.1%}) ' 'Total misspelled: {4:<4}({5:.1%}) ' 'Unique misspelled: {6:<4}({7:.1%})') editor.callbackSync(self.on_modified, [SCINTILLANOTIFICATION.MODIFIED]) notepad.callback(self.on_buffer_activated, [NOTIFICATION.BUFFERACTIVATED]) current_dict_path = os.path.join(notepad.getPluginConfigDir(), 'Hunspell') current_dict_file = os.path.join(current_dict_path, 'Spanish TOP972.dic') with open(current_dict_file, 'r') as f: self.current_dict = f.read().splitlines()[1:] # skip length entry self.on_buffer_activated({}) def check_words(self): words = [] editor.research('[[:alpha:]]+(?=[\h|[:punct:]|\R|\Z])', lambda m: words.append(m.group())) error_words = [word.lower() for word in words if word.lower() not in self.current_dict and # insensitive word check not word.isupper() # ignore all uppercase only words ] total = len(words) unique = len(set(words)) misspelled = len(error_words) misspelled_unique = len(set(error_words)) notepad.setStatusBar(STATUSBARSECTION.DOCTYPE, self.report.format(total, unique, total-misspelled, # non-misspelled (float(total-misspelled) / total) if misspelled else 1, # non-misspelled % misspelled, (float(misspelled) / total) if misspelled else 0, misspelled_unique, (float(misspelled_unique) / total) if misspelled_unique else 0)) def on_modified(self, args): if ((args['modificationType'] & MODIFICATIONFLAGS.INSERTTEXT) or (args['modificationType'] & MODIFICATIONFLAGS.DELETETEXT)): self.check_words() def on_buffer_activated(self, args): self.check_words() WORD_CHECKER()You stated that you want to run 5 copies of the script.
If you run it in 5 different npp instances, then yes, that might
be a solution but if you want to run this script in an npp instance with 5 different documents then it won’t do what you
probably expect. -
@Ekopalypse THANKS A LOT!!! It now exactly matches the number of misspellings reported by DSpellcheck!
The txt file I uploaded is UTF-8 on my PC. Maybe uploading it to Weebly changed the format. I should have zipped it.
BTW, I actually like the fact that you’re ignoring numbers and words with numbers from the total words, because when I type those I don’t want them to influence the statistics.
This will make it a LOT easier for me to write stories for my students.
I’d love to credit you in my website for writing this amazing tool. Should I credit you as “Ekopalypse” or do you prefer something else? May I post the script to my website for free so other language teachers can use it? Of course, crediting you. I’ll also post a video to my channel explaining why to use it and how to use it.
-
Thank you, yes you are welcome to publish this for free and there is no copyright claim from my side.
It is not necessary to mention me, but if you should mention me, please use my Ekopalypse pseudonym.I hope that this can be helpful for you and others, but I’m almost sure that with other languages
and/or other DSpellCheck settings this will not always achieve the same results as DSpellCheck.
Actually this feature would be better available in DSpellCheck I guess.
Maybe you could convince predelnik to implement it!? My approach could serve as a template.
Maybe another tab called Statistics under Settings… with an option to display this in realtime in the DocType field!?This brings us to another point.
I noticed that DSpellCheck produces an exception when you wants to start a Python script via the toolbar.
This will not happen if the script is started from either the Scripts submenu, the PythonScript main menu or via KeyboardShortcut.
I opened an issue for this here.Otherwise I can only wish you good luck for your stories.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login