Help with UDL config
-
i basically want to style each operator differently and leave the text the default. i cant seem to figure it out
i think the fix would be to add an option of the user checking forward or backward to the keywords. Or just add more separate Operators boxes or add the option to nest ‘default text font’
or maybe i just cant figure it out… if someone could do it I would appreciate it. here is a screenshot
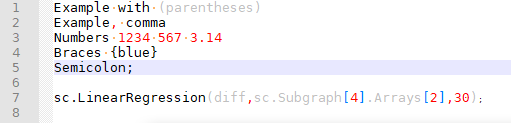
• Open and closing ( ) light grey
• Commas red
• Numbers red
• Open closing braces blue
• Ending semi colon reduced sizesc.LinearRegression(diff,sc.Subgraph[4].Arrays[2],30);
-
@JR said in Help with UDL config:
sc.LinearRegression(diff,sc.Subgraph[4].Arrays[2],30);
[img]https://i.imgur.com/dJWBWi4.png[/img]This forum uses markdown, not bbcode.
=>

By using delimiters, you can come close, but not exactly what you want:
- operator1 =
, - delimiter1 =
(…) - delimiter2 =
[…] - keyword1 =
;
On the delimiters, I allowed nesting of just about everything, so other colors would come through.
It’s close, but the parentheses as delimiters means that things inside the parens also get light grey. And getting only semicolons at the end of a line cannot be done in UDL – by making it a keyword, if it comes after non-word character (like after close paren or after whitespace) it will be highlighted as a keyword; however, after text (as shown in
Semicolon;in my pic), it won’t highlight.If that’s not sufficient, you can add extra highlighting to a UDL language using regexes via the script
EnhanceUDLLexer.pythat @Ekopalypse shares in this linked post( @Ekopalypse : are you planning on making similar updates to EnhanceUDLLexer and put it on your github, like you did for EnhanceAnyLexer? Or even just put a copy there? If you do, I’ll update my boilerplate)
- operator1 =
-
@PeterJones said in Help with UDL config:
like you did for EnhanceAnyLexer
I stand corrected: I looked at the updated
EnhanceAnyLexer.pycode, and its comments claim to handle both builtin and UDL lexers now. Cool.So, @JR, you can use the updated script from his github, rather than the one in the post I previously linked
-
@PeterJones said in Help with UDL config:
EnhanceAnyLexer.py code, and its comments claim to handle both builtin and UDL lexers now.
I guess that is the reason for the renaming so that
Anyis in the name now. :-) -
@PeterJones thanks for the reply.
now how do i implement this EnhanceAnyLexer.py script? use PythonScripts plugin? list in under ‘Machine Scripts’? is there a gui or how are the rules implemented?
if you can just point me in the general direction i can figure it out (just new to np) thanks again
-
@JR ,
Yes, it uses PythonScript plugin. It can go in either Machine or User scripts. You have to configure it in the code, then run it. It can be run from startup.py to run every time you load NPP. I believe that the thread I linked earlier probably explains how to do that
-
@PeterJones said in Help with UDL config:
It can go in either Machine or User scripts.
Why is this even a factor.
You should create a new script with Python Script -> New Script and then name it and then paste the code into it.
The plugin will put the code file where it “belongs”. -
feel free to open an issue if something is unclear from the usage description in the script.
As for the startup.py, if you use the one under machine then there is
a chance that it gets overwritten once an PythonScript plugin update happens. Like @Alan-Kilborn said, I would create a custom script with “New Script” and name it startup.py.
It is automatically created in the correct path.
By the way, the PythonScript configuration has to be changed from LAZY to ATSTARTUP so that it is executed at every npp startup.
![https://i.imgur.com/dJWBWi4.png[/img]](https://i.imgur.com/dJWBWi4.png%5B/img%5D){kind=link}
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login