Find/remove duplicate multiple lines and keep the first occasions
-
@W-den-Boer said in Find/remove duplicate multiple lines and keep the first occasions:
But, I’m considering ordering Legic…and see what happens…
I’ve got the process boiled down to a few steps and yes it should be able to be made into a macro, might be 2 macros since I’m working across 2 files. Still have some fine tuning and presentation to achieve. I will be back at my work PC in approx 5hrs where my notes are and it should only take about 1hr to knock together the steps for you.
I have 2 questions. I originally thought the blank line in your “after” example was the result of leaving the CRLF from the last line when the 6 or so lines are removed but I now think it was due to an actual blank line in the sequence which you never removed. Since this is html code this blank line probably should be removed, do you agree?
2nd question, is it sufficient to ONLY use the h2 tag data to determine duplicity or should every title sequence need to test both h1 AND h2 tag data?I originally thought the duplicity test would be the hardest but it came together in just 1 step. It might even be possible to try it within the file now I’ve been testing so I will likely give you both processes as there is very little difference between them.
Terry
-
@Terry-R First: Thanks.
Second: Q1, A1: I checked, the only blank line in the original file (in the textbook-part) was here<div class="learning-text__title--h3"> blank </div>Q2: A1: I do think that the text between the h2-tags is also in the textbook as plain text. So only that text will result in more removals and not only the h1 and h2 and h3 etc tags. But if your duplicitysearch includes the notion it has to be next to h1, I think you’re right.
Q2: A2: I need only unique sets of h1/h2 left in the document. Each h1 will be there about 10-16 times (depends on how many paragraphes there are), but each paragraph (h2) will be unique.
Wdeb
-
@W-den-Boer said in Find/remove duplicate multiple lines and keep the first occasions:
But if your duplicitysearch includes the notion it has to be next to h1, I think you’re right.
My duplicity search/removal works on the 6 lines (exactly) which encompasses the h1,h2 and h3 tags. I note in your examples h3 is never used. Is that true for the entire file?
How many lines in the whole file, this will give me confidence on whether to aim at doing it within the 1 file or extracting, processing then returning remaining lines back to original file and completing the processing.
Currently my testing, as it is carried out in a separate file will only work on the sets of 6 lines of title data around the h1,h2 and h3 tags. Therefore no issue of removing too much as it does not see any of the “plain text”. If I keep it within the 1 file I will need to further test, but I feel it still won’t test against the “plain trxt” as I keep the test within those sets of 6 linesTerry
-
Hello, @w-den-boer, @ekopalypse, @terry-r and All,
As @Terry-r said, any block of lines, below, after the first one, must be replaced with a single empty line
<div class="element"> <div class="learning-text__title--h1">Groene chemie</div> <div class="learning-text__title--h2">xxxxxxxxxxxxxxxxx</div> <div class="learning-text__title--h3"> </div>So, I elaborated a method, which :
-
- Backup your file
-
- Change the multi-lines block, above, in one single line, in your file
-
- Add a numbering at beginning of all lines of your file
-
- Bookmark all the new “single lines” of your file
-
- Paste these lines in a new temporary file
-
- Delete each first line of an identical lines block, in the temporary file
-
- Append the remaining lines of the temporary file in your file
-
- Delete all lines of your file which is repeated in the appended part
-
- Restore the initial appearance of the file ( Rewrite the missing line_break characters and delete the leading digits and the appended lines, at end of file )
-
In all the explanations, below, relative to search/ replace or mark operations :
-
The search mode is always supposed to be the
Regular expressionmode -
The
Match caseoption is always ticked -
The
Wrap aroundoption is always UNTICKED ( IMPORTANT )
-
-
We’ll need a temporary character to replace some line-break characters. I decided to use the
@char, absent from your file. Of course, any other character (¤,#,~… ), not present in your file, can be suitable -
I assume that your file is given the name
Text_Book.txt
-
So, first, backup this file as
Text_Book.bak( IMPORTANT ) -
Open your file
Text_Book.txt -
Move the caret to the beginning of the first line
<div class="element">of your file ( IMPORTANT ) -
Perform this first S/R (
Ctrl + H) :-
SEARCH
(?-s)(^\h*<div class="element">|\G.+)\K\R(?!^\h*<div class="source source--12">) -
REPLACE
@ -
Click on the
Replace Allbutton (40occurrences were replaced )
-
-
Replace the caret to the beginning of the first line of your file (
Ctrl + Home) -
Select the
Edit > Column Editor...menu option (Alt + C)-
Select the
Number to Insertoption -
Type in
1in all the zones -
Tick the
Leading zerosoption -
Tick the
Decbutton, if necessary -
Click on the
OKbutton
-
-
Move the caret to the beginning of the first line of your file (
Ctrl + Home) -
Select the
Search > Mark...menu option (Ctrl + M)-
SEARCH
@ -
Tick the
Bookmark lineoption -
Click on the
Mark Allbutton (40matches )
-
-
Select the
Search > Bookmark > Copy Bookmark Linesmenu option -
Open a new file (
Ctrl + N) I suppose that its name isnew 1 -
Paste all the bookmarked lines in the
new 1file (Ctrl + V) -
Move the caret to the beginning of the first line of this temporary file (
Ctrl + Home) -
Perform this second S/R (
Ctrl + H), in thenew 1file :-
SEARCH
(?-s)^\d+(.+\R)((\d+\1)+) -
REPLACE
\2 -
Click on the
Replace Allbutton (2occurrences were replaced )
-
-
Select all the remaining contents of the
new 1file (Ctrl + A)) -
Copy these contents in the clipboard (
Ctrl + C) -
Select, again, the
Text_Book.txtN++ tab -
Go to the end of your file (
Ctrl + End) -
Type in a new line containing, at least, three
=signs and ended with a line-break -
Paste the contents of the clipboard under the
===....line ( so, thenew 1contents )
=> You should get the following
Text_Book.txtcontents :01</div> 02 </div> 03 <div class="element">@ <div class="learning-text__title--h1">Groene chemie</div>@ <div class="learning-text__title--h2">Wat is groene chemie?</div>@ <div class="learning-text__title--h3">@ @ </div> 04 <div class="source source--12"> 05 <h1 class="source__title">Eutrofiëring</h1> 06 <article> 07 <p>Eutrofiëring is e...en dus.</p> 08<p><img class="source__inline-image-author source__inline-image-author--middle source__inline-image-author--large" src="./HAVO 20200820_files/3941a287ef5383dfa1032b4e2b9eb160" data-allow-fullscreen="true"></p> 09 </article> 10</div> 11 </div> 12 <div class="element">@ <div class="learning-text__title--h1">Groene chemie</div>@ <div class="learning-text__title--h2">Wat is groene chemie?</div>@ <div class="learning-text__title--h3">@ @ </div> 13 <div class="source source--12"> 14 <h1 class="source__title">Wasmiddelen uit de jaren zestig</h1> 15 <article> 16 <p>In de ....n werk doen.</p> 17 </article> 18</div> 19 </div> 20 <div class="element">@ <div class="learning-text__title--h1">Groene chemie</div>@ <div class="learning-text__title--h2">Wat is groene chemie?</div>@ <div class="learning-text__title--h3">@ @ </div> 21 <div class="source source--12"> 22 <h1 class="source__title">Inleiding: wat is duurzame ontwikkeling?</h1> 23 <article> 24 <p><img class="source__inline-image-author source__inline-image-author--right "> <img class="source__inline-image-author source__inline-image-author--right source__inline-image-author--medium" src="./HAVO 20200820_files/912bdc45aa4c74f5ce0b66e877904b87">In de....ar grenzen. </p> 25 </article> 26</div> 27 </div> 28 <div class="element">@ <div class="learning-text__title--h1">Groene chemie</div>@ <div class="learning-text__title--h2">Wat is groene chemie?</div>@ <div class="learning-text__title--h3">@ @ </div> 29 <div class="source source--12"> 30 <h1 class="source__title">Zuinig met grondstoffen</h1> 31 <article> 32 <p>Gron.... trui?</p> 33<p><img class="source__inline-image-author source__inline-image-author--middle source__inline-image-author--large" src="./HAVO 20200820_files/91cd81fe1aff983dd518f3a55c0ec145"></p> 34 </article> 35</div> 36 </div> 37 <div class="element">@ <div class="learning-text__title--h1">Groene chemie</div>@ <div class="learning-text__title--h2">Wat is groene chemie?</div>@ <div class="learning-text__title--h3">@ @ </div> 38 <div class="source source--12"> 39 <h1 class="source__title">Wettelijke verplichtingen op het gebied energie</h1> 40 <article> 41 <p>En.....</p> 42 </article> 43</div> 44NEXT CHAPTER 45</div> 46 </div> 47 <div class="element">@ <div class="learning-text__title--h1">Groene chemie</div>@ <div class="learning-text__title--h2">Kan het wat sneller?</div>@ <div class="learning-text__title--h3">@ @ </div> 48 <div class="source source--12"> 49 <h1 class="source__title">Reactiesnelheid en de chemische industrie</h1> 50 <article> 51 <p>D....ebt:</p> 52<ul> 53<li>soort stof</li> 54<li>verdelingsgraad</li> 55<li>temperatuur</li> 56<li>concentratie</li> 57<li>aanwezigheid van een katalysator </li> 58</ul> 59<p>......</p> 60 </article> 61</div> 62 </div> 63 <div class="element">@ <div class="learning-text__title--h1">Groene chemie</div>@ <div class="learning-text__title--h2">Kan het wat sneller?</div>@ <div class="learning-text__title--h3">@ @ </div> 64 <div class="source source--12"> 65 <h1 class="source__title">Botsende deeltjes model</h1> 66 <article> 67 <p>In....ie.</p> 68<p>Alleen a.....</p> 69 </article> 70</div> 71 </div> 72 <div class="element">@ <div class="learning-text__title--h1">Groene chemie</div>@ <div class="learning-text__title--h2">Kan het wat sneller?</div>@ <div class="learning-text__title--h3">@ @ </div> 73 <div class="source source--12"> 74 <h1 class="source__title">Reactiesnelheid op microniveau</h1> 75 <article> 76 <ul> 77<li>De ...inden.</li> 78<li>Het...uur.</li> 79<li>Hie...ing.</li> 80<li>Bi....en.</li> 81</ul> 82 </article> 83</div> ============ 12 <div class="element">@ <div class="learning-text__title--h1">Groene chemie</div>@ <div class="learning-text__title--h2">Wat is groene chemie?</div>@ <div class="learning-text__title--h3">@ @ </div> 20 <div class="element">@ <div class="learning-text__title--h1">Groene chemie</div>@ <div class="learning-text__title--h2">Wat is groene chemie?</div>@ <div class="learning-text__title--h3">@ @ </div> 28 <div class="element">@ <div class="learning-text__title--h1">Groene chemie</div>@ <div class="learning-text__title--h2">Wat is groene chemie?</div>@ <div class="learning-text__title--h3">@ @ </div> 37 <div class="element">@ <div class="learning-text__title--h1">Groene chemie</div>@ <div class="learning-text__title--h2">Wat is groene chemie?</div>@ <div class="learning-text__title--h3">@ @ </div> 63 <div class="element">@ <div class="learning-text__title--h1">Groene chemie</div>@ <div class="learning-text__title--h2">Kan het wat sneller?</div>@ <div class="learning-text__title--h3">@ @ </div> 72 <div class="element">@ <div class="learning-text__title--h1">Groene chemie</div>@ <div class="learning-text__title--h2">Kan het wat sneller?</div>@ <div class="learning-text__title--h3">@ @ </div>-
Move the caret to the beginning of the first line of
Text_Book.txtfile (Ctrl + Home) -
Perform this third S/R (
Ctrl + H), in theText_Book.txtfile :-
SEARCH
(?s)^((^\d+)(?-s).+\R)(?=.+^===.+^\1) -
REPLACE
\2\r\n -
Click on the
Replace Allbutton (6occurrences were replaced )
-
-
Move, again, the caret to the beginning of
Text_Book.txt`** file, if necessary -
Finally, perform this fourth S/R (
Ctrl + H), which restores the initial appearance of the file :-
SEARCH
^\d+|(@)|^===(?s).+ -
REPLACE
?1\r\n -
Click on the
Replace Allbutton (94occurrences were replaced )
-
If we compare with the expected results, given in this post :
https://community.notepad-plus-plus.org/post/57758
We do get identical files , if we except the final line-break ;-)) Nice, isn’t it ?
If necessary, I could give you, next time, some hints on the regexes involved in the process !
Best Regards
guy038
-
-
@Terry-R h3 is never used, yes. At least, not as I saw it. The total file has around the 10.000 lines.
-
@guy038 Ofcourse I tried this. I even understand the steps…but… the result of step 7 leaves a blank file.
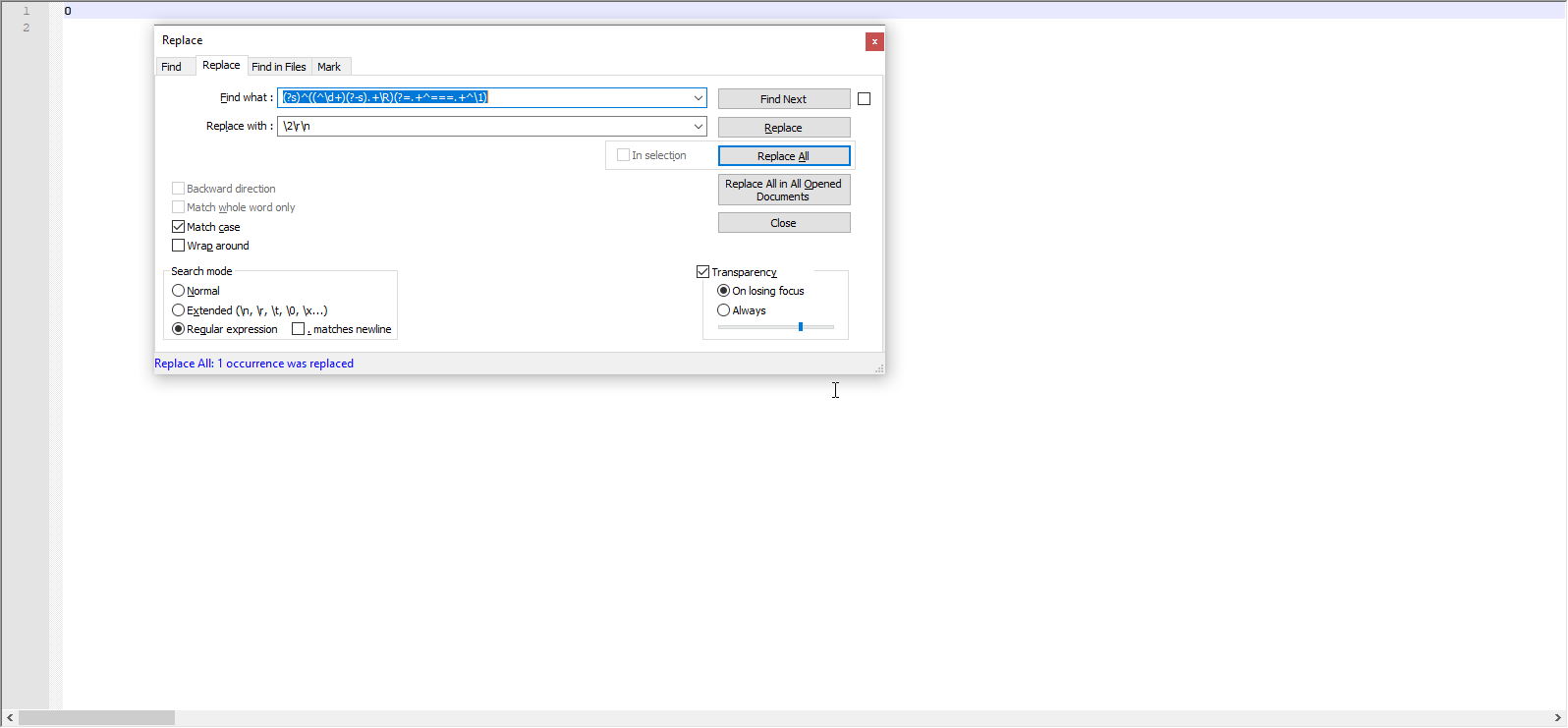
Is that the problem Terry revered to?
And I had a @ in my file, so I replaced with `, which was not in my file.
Wdeb
-
And I tried it with one module, same result.
-
Hi, @w-den-boer, @ekopalypse, @terry-r and All,
Unfortunately, you’re right about it ! Indeed, it’s the problem that @terry-r referred to :-(
Just an example : imagine there are about
3.000lines between a pseudo single line to delete and the same line, near the end of file, listed after the====....line. Then, It is very likely that a false positive match ( all file contents ) occurs !But, luckily, I’ve got the right solution :
-
Step 6 : Simply append the contents of
new 1file at the end of your file ( NO need to add the line of=signs ! ) -
New step 7 : Sort all the lines => The duplicate lines will, then, be all consecutive ! ( I should have thought about it . Obvious, isn’t it ? )
-
New step 8 : Modify the third S/R in order to replace two equal consecutive lines, with only, the numbering and a line-break character
-
New Step 9 = Old step 8 almost unchanged !
So, here is my updated method :
-
- Backup your file
-
- Change this multi-lines block in one single line, in your file
-
- Add a numbering at beginning of all lines of your file
-
- Bookmark all the new “single lines” of your file
-
- Paste these lines in a new temporary file
-
- Delete each first line of an identical lines block, in the temporary file
-
- Append the remaining lines, of the temporary file, at the end of your file
-
- Sort all the lines of your file, lexicographically ascending
-
- Replace all two consecutive duplicate lines of your file with a single line ( Numbering + Line-break char )
-
- Restore the initial appearance of the file ( Rewrite the missing line_break characters and delete the leading digits )
-
In all the explanations, below, relative to search/ replace or mark operations :
-
The search mode is always supposed to be the
Regular expressionmode -
The
Match caseoption is always ticked -
The
Wrap aroundoption is always UNTICKED ( IMPORTANT )
-
-
We’ll need a temporary character to replace some line-break characters. I decided to use the
@char, absent from your file. Of course, any other character (¤,#,~… ), not present in your file, can be suitable -
I assume that your file is given the name
Text_Book.txt
-
So, first, backup this file as
Text_Book.bak( IMPORTANT ) -
Open your file
Text_Book.txt -
Move the caret to the beginning of the first line
<div class="element">of your file ( IMPORTANT ) -
Perform this first S/R (
Ctrl + H) :-
SEARCH
(?-s)(^\h*<div class="element">|\G.+)\K\R(?!^\h*<div class="source source--12">) -
REPLACE
@ -
Click on the
Replace Allbutton (40occurrences were replaced )
-
-
Replace the caret to the beginning of the first line of your file (
Ctrl + Home) -
Select the
Edit > Column Editor...menu option (Alt + C)-
Select the
Number to Insertoption -
Type in
1in all the zones -
Tick the
Leading zerosoption -
Tick the
Decbutton, if necessary -
Click on the
OKbutton
-
-
Move the caret to the beginning of the first line of your file (
Ctrl + Home) -
Select the
Search > Mark...menu option (Ctrl + M)-
SEARCH
@ -
Tick the
Bookmark lineoption -
Click on the
Mark Allbutton (40matches )
-
-
Select the
Search > Bookmark > Copy Bookmark Linesmenu option -
Open a new file (
Ctrl + N) I suppose that its name isnew 1 -
Paste all the bookmarked lines in the
new 1file (Ctrl + V) -
Move the caret to the beginning of the first line of this temporary file (
Ctrl + Home) -
Perform this second S/R (
Ctrl + H), in thenew 1file :-
SEARCH
(?-s)^\d+(.+\R)((\d+\1)+) -
REPLACE
\2 -
Click on the
Replace Allbutton (2occurrences were replaced )
-
-
Select all the remaining contents of the
new 1file (Ctrl + A)) -
Copy these contents in the clipboard (
Ctrl + C) -
Select, again, the
Text_Book.txtN++ tab -
Go to the end of your file (
Ctrl + End) -
Paste the contents of the clipboard under the
===....line ( so, thenew 1contents )
=> You should get the following
Text_Book.txtcontents :01</div> 02 </div> 03 <div class="element">@ <div class="learning-text__title--h1">Groene chemie</div>@ <div class="learning-text__title--h2">Wat is groene chemie?</div>@ <div class="learning-text__title--h3">@ @ </div> 04 <div class="source source--12"> 05 <h1 class="source__title">Eutrofiëring</h1> 06 <article> 07 <p>Eutrofiëring is e...en dus.</p> 08<p><img class="source__inline-image-author source__inline-image-author--middle source__inline-image-author--large" src="./HAVO 20200820_files/3941a287ef5383dfa1032b4e2b9eb160" data-allow-fullscreen="true"></p> 09 </article> 10</div> 11 </div> 12 <div class="element">@ <div class="learning-text__title--h1">Groene chemie</div>@ <div class="learning-text__title--h2">Wat is groene chemie?</div>@ <div class="learning-text__title--h3">@ @ </div> 13 <div class="source source--12"> 14 <h1 class="source__title">Wasmiddelen uit de jaren zestig</h1> 15 <article> 16 <p>In de ....n werk doen.</p> 17 </article> 18</div> 19 </div> 20 <div class="element">@ <div class="learning-text__title--h1">Groene chemie</div>@ <div class="learning-text__title--h2">Wat is groene chemie?</div>@ <div class="learning-text__title--h3">@ @ </div> 21 <div class="source source--12"> 22 <h1 class="source__title">Inleiding: wat is duurzame ontwikkeling?</h1> 23 <article> 24 <p><img class="source__inline-image-author source__inline-image-author--right "> <img class="source__inline-image-author source__inline-image-author--right source__inline-image-author--medium" src="./HAVO 20200820_files/912bdc45aa4c74f5ce0b66e877904b87">In de....ar grenzen. </p> 25 </article> 26</div> 27 </div> 28 <div class="element">@ <div class="learning-text__title--h1">Groene chemie</div>@ <div class="learning-text__title--h2">Wat is groene chemie?</div>@ <div class="learning-text__title--h3">@ @ </div> 29 <div class="source source--12"> 30 <h1 class="source__title">Zuinig met grondstoffen</h1> 31 <article> 32 <p>Gron.... trui?</p> 33<p><img class="source__inline-image-author source__inline-image-author--middle source__inline-image-author--large" src="./HAVO 20200820_files/91cd81fe1aff983dd518f3a55c0ec145"></p> 34 </article> 35</div> 36 </div> 37 <div class="element">@ <div class="learning-text__title--h1">Groene chemie</div>@ <div class="learning-text__title--h2">Wat is groene chemie?</div>@ <div class="learning-text__title--h3">@ @ </div> 38 <div class="source source--12"> 39 <h1 class="source__title">Wettelijke verplichtingen op het gebied energie</h1> 40 <article> 41 <p>En.....</p> 42 </article> 43</div> 44NEXT CHAPTER 45</div> 46 </div> 47 <div class="element">@ <div class="learning-text__title--h1">Groene chemie</div>@ <div class="learning-text__title--h2">Kan het wat sneller?</div>@ <div class="learning-text__title--h3">@ @ </div> 48 <div class="source source--12"> 49 <h1 class="source__title">Reactiesnelheid en de chemische industrie</h1> 50 <article> 51 <p>D....ebt:</p> 52<ul> 53<li>soort stof</li> 54<li>verdelingsgraad</li> 55<li>temperatuur</li> 56<li>concentratie</li> 57<li>aanwezigheid van een katalysator </li> 58</ul> 59<p>......</p> 60 </article> 61</div> 62 </div> 63 <div class="element">@ <div class="learning-text__title--h1">Groene chemie</div>@ <div class="learning-text__title--h2">Kan het wat sneller?</div>@ <div class="learning-text__title--h3">@ @ </div> 64 <div class="source source--12"> 65 <h1 class="source__title">Botsende deeltjes model</h1> 66 <article> 67 <p>In....ie.</p> 68<p>Alleen a.....</p> 69 </article> 70</div> 71 </div> 72 <div class="element">@ <div class="learning-text__title--h1">Groene chemie</div>@ <div class="learning-text__title--h2">Kan het wat sneller?</div>@ <div class="learning-text__title--h3">@ @ </div> 73 <div class="source source--12"> 74 <h1 class="source__title">Reactiesnelheid op microniveau</h1> 75 <article> 76 <ul> 77<li>De ...inden.</li> 78<li>Het...uur.</li> 79<li>Hie...ing.</li> 80<li>Bi....en.</li> 81</ul> 82 </article> 83</div> 12 <div class="element">@ <div class="learning-text__title--h1">Groene chemie</div>@ <div class="learning-text__title--h2">Wat is groene chemie?</div>@ <div class="learning-text__title--h3">@ @ </div> 20 <div class="element">@ <div class="learning-text__title--h1">Groene chemie</div>@ <div class="learning-text__title--h2">Wat is groene chemie?</div>@ <div class="learning-text__title--h3">@ @ </div> 28 <div class="element">@ <div class="learning-text__title--h1">Groene chemie</div>@ <div class="learning-text__title--h2">Wat is groene chemie?</div>@ <div class="learning-text__title--h3">@ @ </div> 37 <div class="element">@ <div class="learning-text__title--h1">Groene chemie</div>@ <div class="learning-text__title--h2">Wat is groene chemie?</div>@ <div class="learning-text__title--h3">@ @ </div> 63 <div class="element">@ <div class="learning-text__title--h1">Groene chemie</div>@ <div class="learning-text__title--h2">Kan het wat sneller?</div>@ <div class="learning-text__title--h3">@ @ </div> 72 <div class="element">@ <div class="learning-text__title--h1">Groene chemie</div>@ <div class="learning-text__title--h2">Kan het wat sneller?</div>@ <div class="learning-text__title--h3">@ @ </div>-
Cancel any possible selection
-
Run the
Edit > Line Operations > Sort Lines Lexicographically Ascendingmenu option -
Move the caret to the beginning of the first line of
Text_Book.txtfile (Ctrl + Home) -
Perform this new third S/R (
Ctrl + H), in theText_Book.txtfile :-
SEARCH
^((\d+).+\R)\1 -
REPLACE
\2\r\n -
Click on the
Replace Allbutton (6occurrences were replaced )
-
-
Move, again, the caret to the beginning of
Text_Book.txtfile, if necessary -
Finally, perform this new fourth S/R (
Ctrl + H), which restores the initial appearance of the file :-
SEARCH
^\d+|(@) -
REPLACE
?1\r\n -
Click on the
Replace Allbutton (93occurrences were replaced )
-
If we compare with the expected results, given in this post :
https://community.notepad-plus-plus.org/post/57758
We do get identical files , if we except the final line-break ;-)) Nice, isn’t it ?
Cheers,
guy038
-
-
@W-den-Boer said in Find/remove duplicate multiple lines and keep the first occasions:
Is that the problem Terry revered to?
And I had a @ in my file, so I replaced with `, which was not in my file.
WdebI have an alternative to @guy038 solution, shorter in the number of steps and maybe a bit easier to process. It’s the solution I referred to but all in the one file.
Surprisingly I just ran a test on a dummy file containing 50K+ lines and a size approx 5MB, it all worked in the file, no need to export. So I will provide the steps which you can execute manually for now as I’m still concerned that in your tests the fault I explained about DID occur. For all search and replace functions below the “Search Mode” MUST be “Regular Expression”. Turn “Wrap around” off and make sure cursor is in the very first position of the file.
-
We will add line numbers. Yes we use the Ctrl-C function (Column Editor). I prefer to delimit the line numbers with a weird 2 character sequence so there will be no issues differentiating the inserted sequence from the original code. Make sure the cursor is in the very first position then add “#@” to start of every line, then add line numbering with leading zeroes. So with Column Editor we can either insert characters or numbers, the first run is with the
#@character sequence. Leave the cursor in the first position and repeat Column Editor, this time with the numbers, starting 1, incrementing 1 and tick leading zeroes. -
We sort the lines into “Integer Descending” order. Doesn’t sound right but in fact there is a method to this madness. In my testing I stumbled across the fact that by doing a decreasing sort the “title” sequences to be removed were the first ones of any pair. My regex (regular expression) grabs the first set, then compares with a look-ahead to the next set. If they are the same the set already captured are removed. This allows for the entire file to be processed in a single pass. Now this is likely where you will again stumble into the fault. If so I do have another alternative if my assumption is correct. That is, as this is a “book” duplicate titles (h2 tag data) will ONLY ever be sequential. They will always occur in groups, not randomly throughout the file.
Is that assumption correct? -
Use the Replace function to remove duplicates
Find What:(?-s)(^.+\R){3}.+title--h2">(.+)</div>\R.+title--h1">(.+)</div>\R(.+\R)(?s)(?=.+?\2(?-s).+\R.+\3)
Replace With:empty field here, nothing
Replace All button
Currently it uses both h1 and h2 to determine duplicate status, As you suggest h1 does NOT change then this regex can be made simpler? -
Re-sort the file into integer ascending.
-
Remove the line numbers using The Replace function
Find What:^\d+#@
Replace With:empty field here, nothing
Replace All button -
Hopefully completed as expected.
I did decide in light of what has been referred to, to remove that “blank line”. I see no need for it in a html coded file. It doesn’t really help with the viewing, as in editing of the file. Please do confirm one way or the other on whether you need this line or not. My processes above can be adjusted to suit. In my testing on a couple of the steps I went to run the regex only to find a previous step had left the first word in the file highlighted. This meant the regex was working on a selection ONLY. If this occurs, just click in the file’s very first position again before doing the next step.
Please read all the above steps and be familiar with the overlying reason for each of the steps (the regex itself doesn't matter). If at all unsure on what is occurring post back and it can be explained in more detail.I especially (and I think many others) will be VERY interested in knowing how my process went.
Cheers
Terry -
-
@Terry-R I think it works. In step 1 it is ALT-C insteed of CTRL-C
I have to compare it to the one I made, but here in the Netherlands it is late. So tomorrow. And I see you made the selection relative to the h2/h1 tags. Don’t understand it completely, but that;s what I make of it.
Thanks, I’m gonna check the Guy-method too and in the end compare it…
Will let you know.
Wdeb
-
@guy038 Thanks for the changes.
I know have two files, one by method of Terry and one by method of Guy.Strange thing happens in the Guy-method. Module 1 is not correct and every title got removed, but from module 2 it seems correct. I think that the problem is caused by a fault in my document, but as I said…tomorrow. Thanks both.
Wdeb
-
@W-den-Boer said in Find/remove duplicate multiple lines and keep the first occasions:
In step 1 it is ALT-C insteed of CTRL-C
Yes, my bad. I didn’t actually check that hotkey, thought I knew it although that is the copy command DUH!.
My quick test earlier was not a good one as I replicated a few sequences many times. So the regex never needed to search the entire file. However I just repeated the test, again with a 47K+ line file with only 1 pair of titles, one at the start and another very near the end. It still worked so I am very hopeful that your real life data should also work.
The regex does indeed use both h1 and h2 tags to identify where it is. At the point the h2 tag line is found it has the preceding 3 lines as well. Now note we look for h2 not h1 as currently the file is reversed, so h2 comes first, actually h3 does but it does not contain any data. Then we continue on to capture the h1 data. both h2 and h1 are used in the look-ahead
(?=.+?\2(?-s).+\R.+\3)to see if another sequence also has that same h2 and h1 data. In which case the regex is confirmed and the first set is removed.So I will work on removing the need to test for the h1 tag, leaving just the h2 tag as the identifier of a duplicate set. Also as this “seems” to work within the file (no export required) I might also be able to create a macro which then all you have to do is insert that into one of NPP’s configuration files. More on that later.
So outstanding question(s):
- As this is a “book” duplicate titles (h2 tag data) will ONLY ever be sequential. They will always occur in groups, not randomly throughout the file. Is that assumption correct?
- The “blank” line. What is your requirement, keep or discard?
Terry
-
@Terry-R said in Find/remove duplicate multiple lines and keep the first occasions:
I might also be able to create a macro which then all you have to do is insert that into one of NPP’s configuration files. More on that later.
I’ve been doing a lot of testing and still can’t guarantee it will work correctly every time within the 1 file due to the fault previously mentioned. I’ve had success on a 50K line file, then on another occasion failure on a 10K line file.
However there is a bright side, most of the steps can be automated into a macro, even when using the 2 file system (cut selected lines and insert into a temporary file). However all is not perfect. The initial steps of numbering the lines does NOT convert to a macro. Thus the steps to include the line number and
#@(my idea) must be completed manually. I do feel though that this a minor irritation.Macro’s are saved within the
shortcuts.xmlfile. Depending on how your installation was completed it may be in one of several locations. I’m going to use the way mine is setup, it will be up to you to find the correct file (same name) if it’s not the one I’m using.- Open Notepad++ (I’m going to call it NPP from here on) without ANY files being open (like a saved session). We need to operate this NPP session purely to edit the shortcuts.xml file ONLY!
- Select “Open…” and type
%appdata%and press enter. This will open a folder listing (amongst other things) the Notepad++ folder. Double click to open this folder. Within it is the file we seek; shortcuts.xml; double click to open that file. - Look within the file for a start tag of
<Macros>. There will also be a ending tag</Macros>. Within this there may already be a macro recorded, if so it will be surrounded by the tags<Macro>and</Macro>. What you will do is copy the contents of the box below and insert into this area so it becomes a new Macro. So insert immediately before the </Macros> tag, but NOT in between the <Macro> and </Macro> tags as that will affect another macro, should it exist.
<Macro name="20027" Ctrl="no" Alt="no" Shift="no" Key="0"> <Action type="3" message="1700" wParam="0" lParam="0" sParam="" /> <Action type="3" message="1601" wParam="0" lParam="0" sParam='(?-s)(^.+\R){6}(?=.+<div class="s)' /> <Action type="3" message="1625" wParam="0" lParam="2" sParam="" /> <Action type="3" message="1702" wParam="0" lParam="784" sParam="" /> <Action type="3" message="1701" wParam="0" lParam="1615" sParam="" /> <Action type="2" message="0" wParam="43018" lParam="0" sParam="" /> <Action type="0" message="2422" wParam="0" lParam="0" sParam="" /> <Action type="0" message="2325" wParam="0" lParam="0" sParam="" /> <Action type="2" message="0" wParam="41001" lParam="0" sParam="" /> <Action type="0" message="2179" wParam="0" lParam="0" sParam="" /> <Action type="3" message="1700" wParam="0" lParam="0" sParam="" /> <Action type="3" message="1601" wParam="0" lParam="0" sParam='(?-s)(^.+\R){3}.+title--h2">(.+)</div>\R.+?\R(?s)(?=.+?\2)' /> <Action type="3" message="1625" wParam="0" lParam="2" sParam="" /> <Action type="3" message="1602" wParam="0" lParam="0" sParam="" /> <Action type="3" message="1702" wParam="0" lParam="768" sParam="" /> <Action type="3" message="1701" wParam="0" lParam="1609" sParam="" /> <Action type="0" message="2326" wParam="0" lParam="0" sParam="" /> <Action type="0" message="2013" wParam="0" lParam="0" sParam="" /> <Action type="0" message="2178" wParam="0" lParam="0" sParam="" /> <Action type="0" message="2422" wParam="0" lParam="0" sParam="" /> <Action type="0" message="2325" wParam="0" lParam="0" sParam="" /> <Action type="2" message="0" wParam="44096" lParam="0" sParam="" /> <Action type="0" message="2316" wParam="0" lParam="0" sParam="" /> <Action type="0" message="2179" wParam="0" lParam="0" sParam="" /> <Action type="1" message="2170" wParam="0" lParam="0" sParam="
" /> <Action type="1" message="2170" wParam="0" lParam="0" sParam="
" /> <Action type="2" message="0" wParam="42061" lParam="0" sParam="" /> <Action type="3" message="1700" wParam="0" lParam="0" sParam="" /> <Action type="3" message="1601" wParam="0" lParam="0" sParam="^\d+#@" /> <Action type="3" message="1625" wParam="0" lParam="2" sParam="" /> <Action type="3" message="1602" wParam="0" lParam="0" sParam="" /> <Action type="3" message="1702" wParam="0" lParam="768" sParam="" /> <Action type="3" message="1701" wParam="0" lParam="1609" sParam="" /> </Macro>Note I called this Macro
20027(first line within box) in recognition of your post/topic number. Feel free to change this to a more suitable name upon inserting.
4. Save the shortcuts.xml file and exit NPP, very important no other work is carried out in the current session!
5. Re-open NPP and now under the Macro menu option there should be an item called in my case 20027, your’s whatever you named it to.
6. That completes a one off process to get the macro “recorded”. Now comes the best bit, actually processing one of your files.- So start NPP, again NO other files loaded, very important!
- Open the file you need to edit.
- Place cursor in the very first position of the file and open the “Column Editor”. First place the characters
#@as has previously been explained. Then repeat for the line number. - Make sure cursor is again in the first position.
- Click on the Macro you created (20027).
- Hopefully the process is fairly fast, for me on an almost 10K line file it took about 5 seconds.
- The file you opened should now be without the duplicated titles, be aware that at the point the macro ceases the file is “edited” but NOT saved!. You will also have a second tab which is the title sequences which were edited. This is only a temporary file and does not need saving, close it.
Obviously you will need to proof the changes made, I strongly suggest to do so. One way of determining the number of changes is to use a copy of the file (this is a destructive test), remove ALL but the h2 tag lines. Then sort and run your eye over the list to see what duplicates exist (if lots then a regex could identify them more accurately, you do seem to be somewhat regex aware so I leave that to you to do). For any duplicate use the tag data string (with the h2 tag string so it does not check “plain text”) to “Count” (within the Find function) on the original processed file, count should always be 1 ONLY!
So it is very hard to decipher a macro once created, although there are amongst us some “experts” in that field (NOT ME!), there is also some documentation should you feel the need to do so which will help.
What this macro does is:- Bookmarks the 6 line sequences throughout the file, then cuts the bookmarked lines and inserts into a “new tab”, that’s the temporary file I referred to above. I should mention here that I’m using version 7.8.9 64bit as I believe the bookmarking function originally only marked the first line of a sequence of lines, it now bookmarks all the lines a regex selects in this version.
- Sorts in Integer descending order.
- Removes the duplicates using ONLY the h2 tag data as the identifier. The blank line is removed as part of the sequence of 6 lines.
- Copies the remaining lines back into the original file and re-sorts integer ascending.
- Removes the line number and following 2 character delimiter.
Just check as there may be a straggler blank line either at start or end of the file. I came across that in testing and was never sure from where it came from. From a html coded file a blank line is inconsequential so I’ve haven’t been too bothered about it.
I’ve quite enjoyed getting my teeth into a major bit of work so I thank you for supplying it. I will say though that my “dummy” data can never replace “real” data so you may well find issue with it. I’d be only too happy to take another look should that arise. Regexes such as this can be a bit fragile (although we do try to build in some flexibility) so any change in the input could well stop the process, or at least cause a malformed file, so continue to do spot checks.
Terry
-
@Terry-R I finally found time to test the macro. I was so happy with the method you described, I did not had the need of testing the macro…
But, bad news. It doesn’t do the same. It removes too much. I could sent you the total files. I just don’t want to post them here.
I think I do understand the method without the macro. And at the moment I feel confident in using it and maybe even altering it for another sort-like problem…but I will be back about that.
Thanks a lot ,
Wdeb
-
@W-den-Boer said in Find/remove duplicate multiple lines and keep the first occasions:
But, bad news. It doesn’t do the same.
Sorry to hear the macro failed to faithfully follow the steps I had outlined. At least with the steps you may be able to generate your own macro. I will suggest if doing so to select the very first position in the file between each major step using Ctrl-Home (I think thats the hotkey).
Lately I’ve been seing what appears to be an anomaly where after a process has finished a word is highlighted. As this becomes a “selection” any subsequent process will likely ONLY work on that selection rather than the whole document.
Terry
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login