.ics file selection problem
-
@PeterJones
Thank You, in this files there is always something after SUMMARY:
The @Terry-R idea with RegEx seems fair, as I have 8 files to check, in each up to 50 BEGIN:VEVENT to END:VEVENT blocks. If it would be tuned to find in this block SUMMARY: bla bla bla this would be more than enought -
This post is deleted! -
This is one of the many times when my standard advice of “show both data that matches and data that does not” would be really helpful.
Have I interpreted correctly: given the data in my text box, you would like to copy what I’ve shown selected in the image, but not the other sections. Am I correct?
BEGIN:VEVENT ... SUMMARY:dont include me ... END:VEVENT BEGIN:VEVENT ... SUMMARY:bla bla bla ... END:VEVENT BEGIN:VEVENT ... SUMMARY:dont include me ... END:VEVENT BEGIN:VEVENT ... SUMMARY:bla bla bla ... END:VEVENT BEGIN:VEVENT ... SUMMARY:dont include me ... END:VEVENT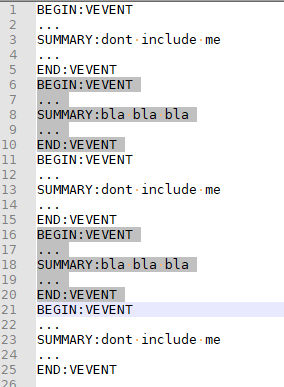
-
You also didn’t answer my question about whether
;ENCODING=...can modify theSUMMARYor not. Well, it can in general, but whether it can be in your example data or not.And the long form of my advice follows, since it hasn’t been in this thread yet:
-—
Do you want regex search/replace help? Then please be patient and polite, show some effort, and be willing to learn; answer questions and requests for clarification that are made of you. All example text should be marked as plain text using the
</>toolbar button or manual Markdown syntax. Screenshots can be pasted from the clipboard to your post usingCtrl+Vto show graphical items, but any text should be included as literal text in your post so we can easily copy/paste your data. Show the data you have and the text you want to get from that data; include examples of things that should match and be transformed, and things that don’t match and should be left alone; show edge cases and make sure you examples are as varied as your real data. Show the regex you already tried, and why you thought it should work; tell us what’s wrong with what you do get… Read the official NPP Searching / Regex docs and the forum’s Regular Expression FAQ. If you follow these guidelines, you’re much more likely to get helpful replies that solve your problem in the shortest number of tries. -
@PeterJones said in .ics file selection problem:
Have I interpreted correctly: given the data in my t
Yes that’s what I’m looking for.
-
@Marcin-Jewiarz said in .ics file selection problem:
If it would be tuned to find in this block SUMMARY: bla bla bla this would be more than enought
So my steps to be performed on the data already extracted is:
- Convert each “record set” into 1 line
- Mark those lines with “bla bla bla” in them
- Remove non-marked lines
- Convert the single line records back to normal
1: We will be using the Replace function.
Find What:(?s)\R(?!BEGIN)
Replace With:@#@
Search Mode must be regular expression and have wrap around ticked. Click on the “Replace All” button. All records sets should now be in single lines.2: Using the Mark function we have
Find What:(?i-s)SUMMARY.+?\Qbla bla bla\E
Have “bookmark lines” ticked. Replace thebla bla blain the line above with the “literal” text you want to look for. You will see it is encapsulated within the\Qand\Emetacharacters. This enables you to safely have any character within this area and not worry that some might have special meaning within the regex environment. Click on the "Mark All’ button. Close window once completed, some lines should be marked.3: Under Search, Bookmark, use the “Remove unmarked Lines”. So at this point ONLY those with “bla bla bla” should remain.
4: return the lines to normal. Use the Replace function
Find What:@#@
Replace With:\r\n
All sections of each record set should be on their own line now.I hope this helps.
Terry
-
@Terry-R said in .ics file selection problem:
(?i-s)SUMMARY.+?\Qbla bla bla\E
Thank You a lot. This is great, for sure I’ll try to learn more about RegEx, the second time during the week I’ve used it.
The first was a simple code found in one of the communities to extract important data form service register form laboratory equipment. Now, this. I can make a macro and use it to other files, with modifications to differentrSUMMARY:parameters
Once again Thank You @Terry-R ! -
Hello, @marcin-jewiarz, @Terry-r, @peterjones and All,
We may solve the problem in a more simple way, with these two other solutions :
-
First solution :
-
Use the Mark regex
(?xs-i) BEGIN:VEVENT ((?!BEGIN:).)*? \Qbla bla bla\E .*? END:VEVENT\R? -
Then, run the menu option
Search > Bookmark > Remove Unmarked Lines
-
-
Second solution :
-
Use the regex S/R, below, with a negative look-ahead :
-
SEARCH
(?xs-i) BEGIN:VEVENT \R ((?!BEGIN:|SUMMARY:\Qbla bla bla\E).)+? END:VEVENT \R? -
REPLACE
Leave EMPTY
-
-
See an updated version of these regexes at the end of this post :
https://community.notepad-plus-plus.org/post/58092
For instance, given this text :
BEGIN:VEVENT ... SUMMARY:dont include me ... END:VEVENT BEGIN:VEVENT ... SUMMARY:dont include me ... END:VEVENT BEGIN:VEVENT ... SUMMARY:bla bla bla ... END:VEVENT BEGIN:VEVENT ... SUMMARY:bla bla bla ... END:VEVENT BEGIN:VEVENT ... SUMMARY:dont include me ... END:VEVENT BEGIN:VEVENT ... SUMMARY:dont include me ... END:VEVENT BEGIN:VEVENT ... SUMMARY:bla bla bla ... END:VEVENT BEGIN:VEVENT ... SUMMARY:dont include me ... END:VEVENT BEGIN:VEVENT ... SUMMARY:dont include me ... END:VEVENT BEGIN:VEVENT ... SUMMARY:dont include me ... END:VEVENT BEGIN:VEVENT ... SUMMARY:bla bla bla ... END:VEVENT BEGIN:VEVENT ... SUMMARY:bla bla bla ... END:VEVENT BEGIN:VEVENT ... SUMMARY:dont include me ... END:VEVENT BEGIN:VEVENT ... SUMMARY:bla bla bla ... END:VEVENT BEGIN:VEVENT ... SUMMARY:dont include me ... END:VEVENTAfter running this S/R, we get our expected results :
BEGIN:VEVENT ... SUMMARY:bla bla bla ... END:VEVENT BEGIN:VEVENT ... SUMMARY:bla bla bla ... END:VEVENT BEGIN:VEVENT ... SUMMARY:bla bla bla ... END:VEVENT BEGIN:VEVENT ... SUMMARY:bla bla bla ... END:VEVENT BEGIN:VEVENT ... SUMMARY:bla bla bla ... END:VEVENT BEGIN:VEVENT ... SUMMARY:bla bla bla ... END:VEVENT
We may use the negative look-ahead feature , of the second regex, to force conditions on several lines, too ! For instance, let’s suppose that each
BEGIN:........END:block contains :-
A line containing
Line_<Letter>and that you want to keep the linesLine_A,Line_BandLine_C, only -
A line containing
Expression<Letter>and that you want to keep the linesExpression_X,Expression_YandExpression_Z, only
Then, given this sample :
BEGIN: ... Line_C ... test Expression_X ... END: BEGIN: ... Expression_PTEST ... Line_B ... END: BEGIN: ... Line_E ... Expression_X ... END: BEGIN: ... Expression_M ... Line_ATEST ... END: BEGIN: ... Line_B Expression_H ... ... END: BEGIN: ... Expression_X ... Line_K ... END: BEGIN: ... Line_C ... test Expression_U ... END: BEGIN: ... Test Line_E ... Expression_Q ... END: BEGIN: ... Expression_X ... TEST_Line_A ... END: BEGIN: ... Expression_Y_TEST ... Line_E ... END: BEGIN: ... Line_A ... __Expression_Y__ ... END: BEGIN: ... TESTLine_M_TEST_Expression_ZTest ... END: BEGIN: ... 123456789Expression_Y ... Line_B_OK ... END: BEGIN: ... Line_MTEST ... Expression_J ... END: BEGIN: ... Expression_H Line_L ... END: BEGIN: ... Expression_Z ... Line_G ... END:The following regex S/R deletes any block which does not contain the expression
Line_A,Line_BorLine_C:-
SEARCH
(?xs-i) ^\h* BEGIN: ((?!BEGIN:|Line_A|Line_B|Line_C).)+? END: .*?$ \R? -
REPLACE
Leave EMPTY
We get :
Line_C ... test Expression_X ... END: BEGIN: ... Expression_PTEST ... Line_B ... END: BEGIN: ... Expression_M ... Line_ATEST ... END: BEGIN: ... Line_B Expression_H ... ... END: BEGIN: ... Line_C ... test Expression_U ... END: BEGIN: ... Expression_X ... TEST_Line_A ... END: BEGIN: ... Line_A ... __Expression_Y__ ... END: BEGIN: ... 123456789Expression_Y ... Line_B_OK ... END:
This last regex S/R deletes any block which does not contain the expression
Expression_X,Expression_YorExpression_Z:-
SEARCH
(?xs-i) ^\h* BEGIN: ((?!BEGIN:|Expression_X|Expression_Y|Expression_Z).)+? END: .*?$ \R? -
REPLACE
Leave EMPTY
Nice ! Now, each remaining block, below, have, both :
-
A line containing
Line_A,Line_BorLine_C -
A line containing
Expression_X,Expression_YorExpression_Z
Line_C ... test Expression_X ... END: BEGIN: ... Expression_X ... TEST_Line_A ... END: BEGIN: ... Line_A ... __Expression_Y__ ... END: BEGIN: ... 123456789Expression_Y ... Line_B_OK ... END:
Notes :
-
The strings
BEGIN:andEND:may be preceded by some blank characters -
You may add characters after the strings
BEGIN:andEND: -
The expressions to exclude may occur at any location, within a block
Best Regards,
guy038
-
-
@guy038 said in .ics file selection problem:
We may solve the problem in a more simple way
I like it very much. Your were probably seeing the issue I had trying to LOOK for the bla bla bla, rather than your idea is we should look for any that DON’T have the bla bla bla in them, hence the negative lookahead.
Might I just add 2 sentences for the benefit of @Marcin-Jewiarz, just in case he didn’t notice.
- When you say to use the “Mark” regex (First solution) you forgot to mention the requirement to tick the “bookmark lines”. Obviously without it there are no lines bookmarked and the next step will therefore remove ALL lines.
- Use of the
(?xs-i), thexoption denotes the following as being of a “free form nature”. The spaces shown are NOT used, but exist ONLY to make it easier to read. This along with the\Qand\Eregex functions aren’t used much, but perhaps should be, especially when OP’s come to us with words like “bla bla bla” and we have to say insert your text in this position, however without knowing what the actual text is, it can sometimes cause issues when one or more is actually a metacharacter.
Cheers
Terry -
@guy038 said in .ics file selection problem:
We may solve the problem in a more simple way
@guy038 as your 2nd regex (which removes the non “bla bla bla” record sets) intrigued me I wondered if a slight alteration might allow the whole process to be carried out with 1 regex. So do a (book)mark with a single regex, then use the “remove unmarked line”.
I think I may have cracked it. I’m still a bit hesitant to put it forward as a solution as it’s quite complicated and dare I say it, not something I’d expect anybody to readily adapt to any future need. It was really just an exercise to satisfy my curiosity.
So the regex is:
(?s-i)BEGIN:VEVENT\R((?=SUMMARY:\Qbla bla bla\E).|(?!SUMMARY|BEGIN:).)+?END:VEVENT\R?
By bookmarking we will have after running this regex all record sets we want to keep. So we’re back with the positive look-ahead (at least in part) which allows us to remove all the extraneous data not of the BEGIN:VEVENT…END:VEVENT type and the non “bla bla bla” sets in one step.I’d value your input on the validity of this. It appears to work on some demo data which includes some without the “bla bla bla” text so from that point of view it is a success.
Terry
-
To all who are interested in my synopsis:
I actually fell onto this quite by chance. I’d edited @guy038 regex to try the positive lookahead again. My regex was picking up all the BEGIN:VEVENT…END:VEVENT sets again. On a whim I added in the ?!SUMMARY in front of the ?!BEGIN as an alternation and suddenly it seemed to work. Several tests later it was still working.
I’ve now been pulling my regex apart trying to better understand HOW it works, I suppose not quite believing it. It does seem contrary to both have a positive lookahead and then also a negative using the same characters. So if I understand it correctly:
- We start processing a record set starting with the BEGIN:VEVENT
- Several lines later we approach the SUMMARY line where we want to find the
bla bla blastring. This is the lookahead. - For a record set not containing
bla bla blawe fail this positive lookahead(?=SUMMARY:\Qbla bla bla\E). - As step 3 failed we use the alternation option. At this point it becomes a bit difficult to understand. As alternation works from left to right we first assert we don’t want
SUMMARY. As we do currently have this we immediately fail this side of the alternation, so to the right side we assert we don’t wantBEGIN:, we don’t and here I would have thought it would continue, but it appears to fail. At least that record set is NOT bookmarked and we start all over again. Actually a glimmer of light. Is it because once we commence moving into theSUMMARYline (so the ?!BEGIN actually was true to start with) the positive lookahead will always fail so we only use the alternation. And in the alternation option?!SUMMARYalso always fails, so we are ONLY using the?!BEGINas the method of stopping, and that eventually fails us as well, hence the regex fails. Thus the regex won’t bookmark a nonbla bla blaset.
Whew, have I actually understood it!
Terry
-
Further testing has given me another revised regex, shorter than before.
I think this one is very easy to understand and could serve as the final solution.
(?s-i)BEGIN:VEVENT\R((?=SUMMARY:\Qbla bla bla\E).|(?!SUMMARY:).)+?END:VEVENT\R?- We want a set that contains the BEGIN and END lines and contains `SUMMARY:bla bla bla’.
- If step 1 fails the alternation says we CANNOT have a line with SUMMARY in it within these boundaries. As that WILL fail (unless no SUMMARY line at all) then the regex fails and thus non
bla bla blarecord sets are NOT bookmarked.
So the proviso is the record set MUST contain valid start and end points, i.e. BEGIN:VEVENT and END:VEVENT (which we have always assumed throughout these posts) and it MUST contain a line starting with
SUMMARY:.Depending on what is between the\Qand\Epoints in the regex determines which record sets are marked and which are NOT.At this point I think I’ve spent enough time on it, my curiosity is now satiated.
Terry
-
Hi, @Terry-r and All,
In this post, you said :
I wondered if a slight alteration might allow the whole process to be carried out with 1 regex
I’m sorry but the two solutions given, at beginning of my post are totally independent ! So to solve the @marcin-jewiarz problem, you need to run :
- The first Mark regex , with the
Bookmark lineoption ticked, then use theSearch > Bookmark > Remove Unmarked Lines
OR
- The second regex S/R ,only
So, we do not have to try to mix them up ;-))
Then you asked my opinion about your regex :
(?s-i)BEGIN:VEVENT\R((?=SUMMARY:\Qbla bla bla\E).|(?!SUMMARY|BEGIN:).)+?END:VEVENT\R?Well, just look at the second alternative
(?!SUMMARY|BEGIN:).. This regex means that, between the expressionBEGIN:VEVENT\RandEND:VEVENT\R?, it should never occur the expressionSUMMARYorBEGIN:at any location !So, with this regex, between the expressions
BEGIN:VEVENT\R(andEND:VEVENT\R?-
When the regex engine is at any location, of the block, different from the beginning of a possible line
SUMMARY:bla bla bla, this second alternative matches and catches the single character. -
When the regex engine is, exactly at the beginning of a line
SUMMARY:bla bla bla, the first alternative(?=SUMMARY:\Qbla bla bla\E).does match and catches the single character., too !
So, in short, it matches any char of all blocks containing the expression
SUMMARY:bla bla blaNow let’s imagine that you slightly change your regex as below :
(?s-i)BEGIN:VEVENT\R((?=SUMMARY:\Qbla bla bla\E).|(?!SUMMARY:\Qbla bla bla\E|BEGIN:).)+?END:VEVENT\R?This time, the two alternatives are totally exclusive, regarding the
SUMMARY:bla bla blastring ! So the whole regex just matches any multi-lines blockBEGIN:VEVENT.........END:VEVENT!
Now, in your last post, you said :
Further testing has given me another revised regex, shorter than before
As your final regex does not contain the alternative
BEGIN:, in the negative look-head ! I support this point ;-)) Indeed, looking back to my second solution, this part is not needed ! I certainly needed this part, at one moment, during my tests, but it seems useless in my final try ;-))So, in summary, the two solutions of my previous post should be updated, without the free-spacing mode, as below :
-
First solution :
-
Use the Mark regex
(?s-i)BEGIN:VEVENT((?!BEGIN:).)*?\Qbla bla bla\E.*?END:VEVENT\R?with theBookmark lineticked -
Then, run the menu option
Search > Bookmark > Remove Unmarked Lines
-
-
Second solution :
-
Use the regex S/R, below, with a negative look-ahead :
-
SEARCH
(?s-i)BEGIN:VEVENT\R((?!SUMMARY:\Qbla bla bla\E).)+?END:VEVENT\R? -
REPLACE
Leave EMPTY
-
-
Remark : In the first solution, we still need to the regex
((?!BEGIN:).)*?instead of the.+?one, to restrict the match to a single block. Indeed, the simple regex.*?can match a lineEND:VEVENTand the lineBEGIN:VEVENTof the next block !Best Regards,
guy038
P.S. :
I’ve verified that my updated second solution does match, as expected, a
BEGIN:VEVENT....END:VEVENTblock, which does not contain any lineSUMMARY:........like :BEGIN:VEVENT ... ... END:VEVENT - The first Mark regex , with the
-
@guy038 said in .ics file selection problem:
at beginning of my post are totally independent !
Firstly my apologies. I got fixated on the concept of using a positive lookahead after looking at both of your solutions. For some reason later on a did mix them together and thinking there were 2 steps.
Perhaps in my defence I’ve just come to realise my reasoning all the way through was that there would be extraneous lines between the END:VEVENT and BEGIN:VEVENT lines, that is, between the record sets. I’ve just googled a typical ics file and whilst that isn’t true there are additional lines before AND after (header and footer info) the sets we were identifying with the regexes. I’ve got a longish one and reduced the size so you can see what shows in the file.
BEGIN:VCALENDAR PRODID:-//Google Inc//Google Calendar 70.9054//EN VERSION:2.0 CALSCALE:GREGORIAN METHOD:PUBLISH X-WR-CALNAME:ECML PKDD 2015 X-WR-TIMEZONE:Europe/Lisbon X-WR-CALDESC:The European Conference on Machine Learning and Principles and Practice of\nKnowledge Discovery in Databases (ECMLPKDD) will take place i n Porto\,\nPortugal\, from September 7th to 11th\, 2015 (http://www.ecmlpkd d2015.org).\n\nThis event is the leading European scientific event on machi ne learning and\ndata mining and builds upon a very successful series of 25 ECML and 18 PKDD\nconferences\, which have been jointly organized for the past 14 years. BEGIN:VTIMEZONE TZID:Europe/Lisbon X-LIC-LOCATION:Europe/Lisbon BEGIN:STANDARD TZOFFSETFROM:+0100 TZOFFSETTO:+0000 TZNAME:WET DTSTART:19701025T020000 RRULE:FREQ=YEARLY;BYMONTH=10;BYDAY=-1SU END:STANDARD BEGIN:DAYLIGHT TZOFFSETFROM:+0000 TZOFFSETTO:+0100 TZNAME:WEST DTSTART:19700329T010000 RRULE:FREQ=YEARLY;BYMONTH=3;BYDAY=-1SU END:DAYLIGHT END:VTIMEZONE BEGIN:VEVENT DTSTART:20180907T083000Z ... SUMMARY:Ex. Ep. Especial: IP/PROGI TRANSP:OPAQUE END:VEVENT BEGIN:VEVENT DTSTART;VALUE=DATE:20150803 ... SUMMARY:Workshops - Camera Ready TRANSP:TRANSPARENT END:VEVENT BEGIN:VEVENT DTSTART;VALUE=DATE:20150901 ... SUMMARY:Tutorials - Tutorials Material TRANSP:TRANSPARENT END:VEVENT END:VCALENDARSo although the OP never showed this I had made the assumption I couldn’t guarantee there weren’t other lines, nor did I think to ask.
Thanks for critiquing my regexes. I had made a discovery and couldn’t quite believe I hadn’t considered it before. There have been lots of instances where I wanted to find a data set with a specific string using the lookahead and seeing it would continue through other sets UNTIL it found the correct one. The realisation I had the power to stop it upon a failed string search within the 1 data set was (dare I say it) overwhelming. It was like a light had suddenly switched on, learning a new ability with regexes.
Cheers
Terry
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login