Regex: Find those files that doesn't contain the same link in 2 different html tags
-
@Hellena-Crainicu said in Regex: Find those files that doesn't contain the same link in 2 different html tags:
buy the way, my mistake. I cannot edit again the post.
Hence my confusion. So straight away we have a problem, but it is only a small one. So my first regex should change to
\R(?!<link rel).Terry
-
@Terry-R said in Regex: Find those files that doesn't contain the same link in 2 different html tags:
(?-s)(.+?https://([^"]+))(?=.+?https)(?!.+?\2)@Terry-R your regex is not working
-
@Hellena-Crainicu said in Regex: Find those files that doesn't contain the same link in 2 different html tags:
@Terry-R your regex is not working
It worked for me in a small test, see:
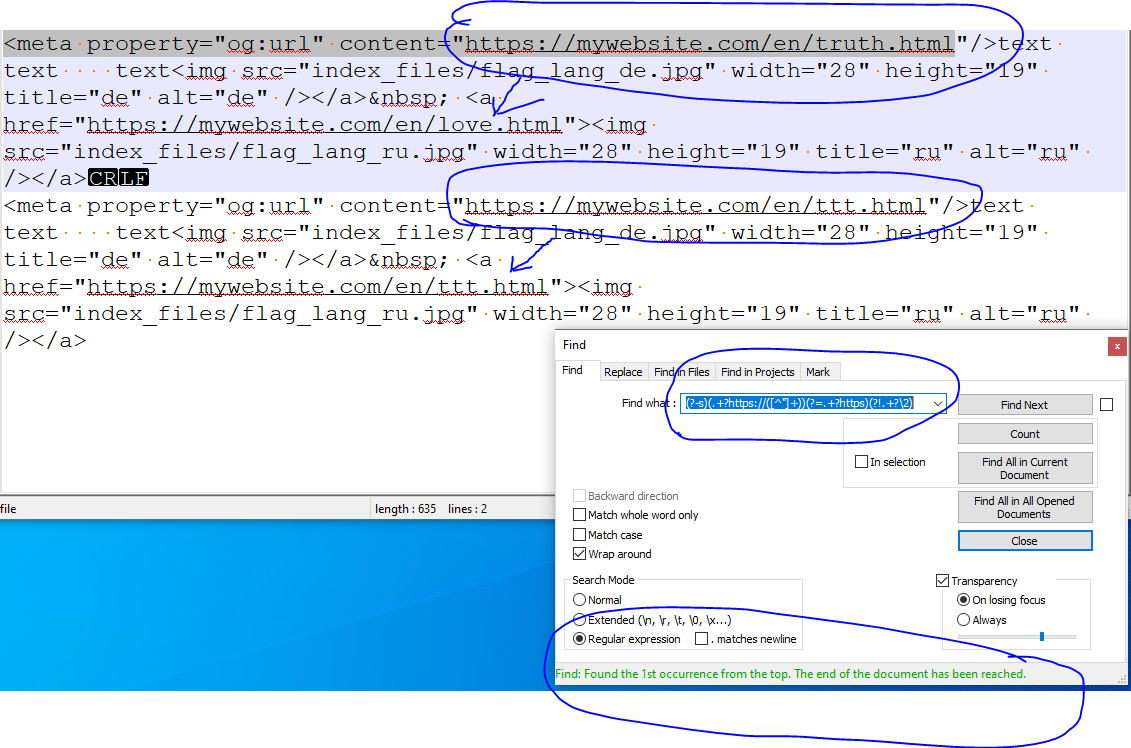
Note I had 2 “groups”, one with matching https references, the other mismatching. It finds the mismatch and then states the end of the document has been reached signifying no further occurrences. If there were further occurrences it doesn’t show this statement.
So not sure why your attempt failed. Does you real data not match the example, or do you have more then 2 https references for each group. Was it my first regex that failed or second. Try the solution on just 1 file inside of notepad++ so you can monitor it’s progress by using “Find” rather than replace for some steps.
Terry
-
@Terry-R said in Regex: Find those files that doesn't contain the same link in 2 different html tags:
(?-s)(.+?https://([^"]+))(?=.+?https)(?!.+?\2)
yes, Terry. Your regex seems to be good, but only if I make the replacement. Now, if I have several html files, I cannot make that replacement just to find something. It will ruin my html code.
And, by the way. you have 2 meta property. i don’t have any in my example :)
-
@Hellena-Crainicu said in Regex: Find those files that doesn't contain the same link in 2 different html tags:
It will ruin my html code.
It seems you missed my statement that as we will be editing the files, you need to work on “copies” of the files:
So my solution means we will be editing the files somewhat so it should be done on a copy of the html files.Terry
PS I realise my image showing it working has meta property, but the regexes don’t use that now as I stated replace first regex with your amended detail “link…”
The second regex doesn’t use that either so it isn’t affected by your change in example data. -
@Hellena-Crainicu said in Regex: Find those files that doesn't contain the same link in 2 different html tags:
y the way. you have 2 meta property. i don’t have any in my example :)
By the way. you have 2 meta property. i don’t have any in my example :)
<link rel="canonical" href="https://mywebsite.com/en/truth.html" /> text text text <img src="index_files/flag_lang_de.jpg" width="28" height="19" title="de" alt="de" /></a> <a href="https://mywebsite.com/en/trsuth.html"><img src="index_files/flag_lang_ru.jpg" width="28" height="19" title="ru" alt="ru" /></a> -
@Hellena-Crainicu said in Regex: Find those files that doesn't contain the same link in 2 different html tags:
I should find the files that doesn’t contain the same link up and down.
I may have found a way to search the html files without having to edit them. Even better is the “Find in Files” search result window will give precise locations as to filename and line number where you need to fix the problems of mismatched https references.
It uses some advanced regex functions only available to Notepad++ since version 7.7. Read the excellent postings by @guy038 here.
In this solution I make use of the
(*SKIP)function. The regex is:
(?s)^<link rel.+?https://([^"]+).+?https://(*SKIP)(?!\1)
So for a description we have the regex:- finding a line starting with
<link rel - advancing character by character (lazy) until the first
https://sequence is found, then capturing it - continuing to capture characters so long as they are NOT the
". This is captured as group 1. - advancing character by character (lazy) until the next (second)
https://sequence is found, then capturing it - this is where the fun begins. At this point it can advance to the next sub expression within the regex, the
(*SKIP)is passed over going forward with no reaction. The next step is a test that the next few characters do NOT match the first https reference (group 1). Normally if this test fails, the regex will backtrack and attempt to consume more characters until this sub-expression is TRUE. That would normally mean progressing into the next group oflink rel...With the(*SKIP)if the regex attempts to backtrack this prevents the backtrack from occurring and thus the regex fails overall.
So the use of
(*SKIP)only allows the 2nd https reference to be tested against the first. A mismatch means success, a match would mean the regex fails and it restarts at the next group oflink rel....Hopefully I have this described correctly and also hopefully it will satisfy your initial request without the need to edit copies.’
It did work on an open file I had with 5 groups, 3 of which had the mismatch and they were all correctly identified.
So the major assumption is that your group (starting with
<link reland ending just before the next<link relstarts) has at least 2 https references and where the test is between the first and second https reference ONLY!Best of luck, I’d be very interested in knowing if this works for you with real world data so please do post back, good or bad. This is my first attempt at using
(*SKIP).Terry
- finding a line starting with
-
Hello, @hellena-crainicu, @terry-r and All,
I don’t think that working on copies is necessary ;-)) So, Hellena, simply use this regex :
SEARCH
(?s)<link\h+rel="canonical"\h*\Khref="([^"]+)".+<a href="(?!\1).+?"
Notes :
-
The
\hsyntax is equivalent to the[\t\x20\xA0]syntax -
The group
1is the regex[^"]+and represents the link•••••in the expression<link rel="canonical" href="•••••" /> -
Due to the
<a href="(?!\1).+?", this link must not be present in thehrefatttribute of the<a>tag -
The
\Kfeature cancels the match attempt so far (<link\h+rel="canonical"\h*) and resets the working position of the regex engine at the wordhref. So, the overall regex will catch the range of chars between the firsthref="•••••"expression and the lasthref="•••••", only !
Finally, the main problem was to be sure that the range of chars, between the two double-quotes of the first link, does end at the closing double-quote and not later, because of the internal backtracking process of the regex engine !
For instance, let’s suppose this text, with the same link
test.comhref="test.com" test="value" href="test.com"Oddly, the regex
(?-si)href="(.+?)".+href="(?!\1).+?"matches this text. The common sense tells that it shouldn’t as we have the negative look-ahead(?!\1)structure !?So why ? Let’s try to follow the regex engine process !
-
First the regex engine matches the
href="string and catches the shortest range of chars till a double-quote so the valuetest.comis stored in group1 -
Then, it matches the part
.+href=". But, as the second link is the same as the first one, the negative look-ahead, which follows, prevent from matching the remainder range of chars -
Now, that’s the important point : the regex engine backtracks and try, by all means, to get a positive match attempt !
-
The regex engine moves back to the location right after the first
href="string and catches an other shortest range of chars till a double-quote. Thus, this time, the valuetest.com" test="valueis stored as group1! Indeed that text is embedded between"! -
Then, again, it matches the part
.+href=". And, now, as the second linktest.comis obviously different from the contents of the group1** (test.com" test="value) the negative look-ahead returns TRUE and the overall regex wrongly matches the complete texthref="test.com" test="value" href="test.com"
-
-
We now understand the way to get the right regex. We just need to avoid that each char between double-quotes may be, themselves, a
"char ! -
So, the second regex version
(?-si)href="([^"]+)".+href="(?!\1).+?", as expected, does not find the text
href="test.com" test="value" href="test.com"And would get this one !
href="test.com" test="value" href="tests.com"Best Regards,
guy038
-
-
@guy038 said in Regex: Find those files that doesn't contain the same link in 2 different html tags:
SEARCH (?s)<link\h+rel=“canonical”\h*\Khref=“([^”]+)“.+<a href=”(?!\1).+?"
I used the below example set for my test and got the 3 mismatch hits I created. When I ran your regex on my example set I only got 1 hit. I think I see where your interpretation differed from mine. I did not know for sure there would ONLY be 2 https references in each file, the OP wasn’t specific enough. Now that I see your interpretation I can see that the OP may have suggested that. So certainly if that’s the case I have definitely overworked my regex.
Cheers
Terry<link rel="canonical" href="https://mywebsite.com/en/truth.html"/> text text text <img src="index_files/flag_lang_de.jpg" width="28" height="19" title="de" alt="de" /></a> <a href="https://mywebsite.com/en/love.html"><img src="index_files/flag_lang_ru.jpg" width="28" height="19" title="ru" alt="ru" /></a> <link rel="canonical" href="https://mywebsite.com/en/ttt.html"/> text text text <img src="index_files/flag_lang_de.jpg" width="28" height="19" title="de" alt="de" /></a> <a href="https://mywebsite.com/en/ttt.html"><img src="index_files/flag_lang_ru.jpg" width="28" height="19" title="ru" alt="ru" /></a> <link rel="canonical" href="https://mywebsite.com/en/truth.html"/> text text text <img src="index_files/flag_lang_de.jpg" width="28" height="19" title="de" alt="de" /></a> <a href="https://mywebsite.com/en/sloven.html"><img src="index_files/flag_lang_ru.jpg" width="28" height="19" title="ru" alt="ru" /></a> <link rel="canonical" href="https://mywebsite.com/en/lovel.html"/> text text text <img src="index_files/flag_lang_de.jpg" width="28" height="19" title="de" alt="de" /></a> <a href="https://mywebsite.com/en/lovely.html"><img src="index_files/flag_lang_ru.jpg" width="28" height="19" title="ru" alt="ru" /></a> <link rel="canonical" href="https://mywebsite.com/en/lov.html"/> text text text <img src="index_files/flag_lang_de.jpg" width="28" height="19" title="de" alt="de" /></a> <a href="https://mywebsite.com/en/lov.html"><img src="index_files/flag_lang_ru.jpg" width="28" height="19" title="ru" alt="ru" /></a> -
Hi, @hellena-crainicu, @terry-r and All,
Reading the Terry’s post made me think that I had not considered the possibility of successive couples
<link rel="canonical" href="–<a href="in a sameHTMLfile !For instance, against the text :
<link rel="canonical" href="https://mywebsite.com/en/truth.html" text text <a href="https://mywebsite.com/en/truth.html" text text <link rel="canonical" href="https://mywebsite.com/en/love.html" text text <a href="https://mywebsite.com/en/love.html"My previous regex would wrongly match all text after
<link rel="canonical". Indeed, as each couple of links are identical ( 2 × truth and 2 × love ), I suppose, @Hellena-crainicu, that you do not want a match, in that specific case, too !
So, @hellena-crainicu, prefer this second version, more robust !
SEARCH / MARK
(?s)<link\h+rel="canonical"\h*\Khref="([^"]+)"((?!<link).)+?<a href="(?!\1).+?"As you can see, the changed part is
((?!<link).)+?which represents the shortest range of characters, not containing the string<link, at any position, globally, between the first and lasthrefattribute !BR
guy038
-
@Terry-R said in Regex: Find those files that doesn't contain the same link in 2 different html tags:
I did not know for sure there would ONLY be 2 https references in each file, the OP wasn’t specific enough.
I note that I did show the OP a previous test I did which had 3 sets i tested against (image). The OP did not mention at that time that he only had 1 set in each file, guess we need the OP to verify if ONLY 1 set in each html file or MANY!
So @Hellena-Crainicu does each html file contain only 1 set of https references (so 2 https references in each file) or many sets that the test must be carried out on.
Terry
-
This post is deleted! -
now I see, there is a small problem.
@Terry-R Your regex seems to be good on my example:
(?s)^<link rel.+?https://([^"]+).+?https://(*SKIP)(?!\1)find only the files whose links are different.@guy038 Your regex, also, it is good on my example:
(?s)<link\h+rel="canonical"\h*\Khref="([^"]+)"((?!<link).)+?<a href="(?!\1).+?"But, I put that TEXT TEXT between those 2 tags, that means that those links can be find more than twice. For this reason we have specified exactly the lines to be considered. Please see the entire code I have:
<link rel="canonical" href="https://mywebsite.com/en/truth.html" /> <meta name="copyright" content="me, https://mywebsite.com/"/> <link rel="sitemap" type="application/rss+xml" href="rss.xml" /> <link rel="image_src" type="image/jpeg" href="https://mywebsite.com/icon-facebook.jpg" style="display:none"/> <meta itemprop="image" content="https://mywebsite.com/icon-facebook.jpg"/> <meta property="og:image" content="https://mywebsite.com/icon-facebook.jpg"/> <meta property="og:type" content="article" /> <meta property="fb:app_id" content="2156440"/> <meta property="fb:admins" content="16454242"/> <meta property="og:url" content="https://mywebsite.com/en/other-car.html"/> <body> TEXT TEXT <div class="search"> <div align="left"> <a href="https://mywebsite.com/hope.html"><img src="index_files/flag_lang_ro.jpg" title="ro" alt="ro" width="28" height="19" /></a> <a href="https://mywebsite.com/fr/book.html"><img src="index_files/flag_lang_fr.jpg" title="fr" alt="fr" width="28" height="19" /></a> <a href="https://mywebsite.com/en/truth.html"><img src="index_files/flag_lang_en.jpg" title="en" alt="en" width="28" height="19" /></a> <a href="https://mywebsite.com/es/green.html"><img src="index_files/flag_lang_es.jpg" title="es" alt="es" width="28" height="19" /></a> <a href="https://mywebsite.com/pt/yellow.html"><img src="index_files/flag_lang_pt.jpg" title="pt" alt="pt" width="28" height="19" /></a> <a href="https://mywebsite.com/ar/truth.html"><img src="index_files/flag_lang_ae.jpg" width="28" height="19" title="ar" alt="ar" /></a> <a href="https://mywebsite.com/zh/truth.html"><img src="index_files/flag_lang_zh.jpg" width="28" height="19" title="zh" alt="zh" /></a> <a href="https://mywebsite.com/hi/truth.html"><img src="index_files/flag_lang_hi.jpg" width="28" height="19" title="hi" alt="hi" /></a> <a href="https://mywebsite.com/de/truth.html"><img src="index_files/flag_lang_de.jpg" width="28" height="19" title="de" alt="de" /></a> <a href="https://mywebsite.com/ru/truth.html"><img src="index_files/flag_lang_ru.jpg" width="28" height="19" title="ru" alt="ru" /></a> TEXT TEXT <div id="pixxell"> <a href="https://mywebsite.com/en/book-miracle.html">I find a miracle </div> TEXT TEXT -
so, the second tag
<img src=...>is extracted from the<div class="search">section. Must be taken into account this part. -
Hi, @hellena-crainicu, @terry-r and All,
I’m really sorry but I still don’t understand what is your goal !
- First, my last regex
(?s)<link\h+rel="canonical"\h*\Khref="([^"]+)"((?!<link).)+?<a href="(?!\1).+?", unlike you said, does not match anything against your last text, even if I remove the partsTEXT TEXT!? Anyway, I don’t care about it as the next regex version will surely be very different !
Now, the important points are :
- Firstly : Does the
HTMLtext that you provided, and which is repeated, below, represents a real part of youHTMLfiles ?
<link rel="canonical" href="https://mywebsite.com/en/truth.html" /> <meta name="copyright" content="me, https://mywebsite.com/"/> <link rel="sitemap" type="application/rss+xml" href="rss.xml" /> <link rel="image_src" type="image/jpeg" href="https://mywebsite.com/icon-facebook.jpg" style="display:none"/> <meta itemprop="image" content="https://mywebsite.com/icon-facebook.jpg"/> <meta property="og:image" content="https://mywebsite.com/icon-facebook.jpg"/> <meta property="og:type" content="article" /> <meta property="fb:app_id" content="2156440"/> <meta property="fb:admins" content="16454242"/> <meta property="og:url" content="https://mywebsite.com/en/other-car.html"/> <body> TEXT TEXT <div class="search"> <div align="left"> <a href="https://mywebsite.com/hope.html"><img src="index_files/flag_lang_ro.jpg" title="ro" alt="ro" width="28" height="19" /></a> <a href="https://mywebsite.com/fr/book.html"><img src="index_files/flag_lang_fr.jpg" title="fr" alt="fr" width="28" height="19" /></a> <a href="https://mywebsite.com/en/truth.html"><img src="index_files/flag_lang_en.jpg" title="en" alt="en" width="28" height="19" /></a> <a href="https://mywebsite.com/es/green.html"><img src="index_files/flag_lang_es.jpg" title="es" alt="es" width="28" height="19" /></a> <a href="https://mywebsite.com/pt/yellow.html"><img src="index_files/flag_lang_pt.jpg" title="pt" alt="pt" width="28" height="19" /></a> <a href="https://mywebsite.com/ar/truth.html"><img src="index_files/flag_lang_ae.jpg" width="28" height="19" title="ar" alt="ar" /></a> <a href="https://mywebsite.com/zh/truth.html"><img src="index_files/flag_lang_zh.jpg" width="28" height="19" title="zh" alt="zh" /></a> <a href="https://mywebsite.com/hi/truth.html"><img src="index_files/flag_lang_hi.jpg" width="28" height="19" title="hi" alt="hi" /></a> <a href="https://mywebsite.com/de/truth.html"><img src="index_files/flag_lang_de.jpg" width="28" height="19" title="de" alt="de" /></a> <a href="https://mywebsite.com/ru/truth.html"><img src="index_files/flag_lang_ru.jpg" width="28" height="19" title="ru" alt="ru" /></a> TEXT TEXT <div id="pixxell"> <a href="https://mywebsite.com/en/book-miracle.html">I find a miracle </div> TEXT TEXT-
Secondly : If so, I suppose that the first line
<link rel="canonical" href="https://mywebsite.com/en/truth.html" />with the linkhttps://mywebsite.com/en/truth.htmlis the first of the two links to consider in the future ( correct ! ) regex -
Thirdly : I also suppose that any of the links, below, after
<div class="search">, and which are followed with an<img src=•••••>tag are taken as a second link to be considered in the future regex
href="https://mywebsite.com/hope.html"> href="https://mywebsite.com/fr/book.html"> href="https://mywebsite.com/en/truth.html"> href="https://mywebsite.com/es/green.html"> href="https://mywebsite.com/pt/yellow.html"> href="https://mywebsite.com/ar/truth.html"> href="https://mywebsite.com/zh/truth.html"> href="https://mywebsite.com/hi/truth.html"> href="https://mywebsite.com/de/truth.html"> href="https://mywebsite.com/ru/truth.html">Fourthly : As the tag
<link rel="canonical"••••" />contains the linkhref="https://mywebsite.com/en/truth.html, I suppose that, considering the list of links, above, you would like that the regex matches :-
FROM the expression
<link rel="canonical" href="https://mywebsite.com/en/truth.html" />or, at least, its linkhref="https://mywebsite.com/en/truth.html" -
TO the first link different from
href="https://mywebsite.com/en/truth.html", so, in this example, the first link of the listhref="https://mywebsite.com/hope.html">
As you can see, it’ is generally much more difficult to fully understand what are the OP’s needs than finding out any kind of regex ;-))
BR
guy038
- First, my last regex
-
@Hellena-Crainicu said in Regex: Find those files that doesn't contain the same link in 2 different html tags:
so, the second tag <img src=…> is extracted from the <div class=“search”> section
So hopefully you now understand providing us the most accurate information possible is key to getting a workable solution.
With my regex I think all you need to add is
</a> <a href="directly in front of the secondhttpsstring. I’m not on a PC currently, instead typing on a smartphone. But if you can try adding these characters I think my regex will work. It’s all a matter of getting the regex to consume characters up until the https tag we wish to check against. This adjustment should get you there. That is unless there are othernbspin between. But then your own regex was using thenbspas well so I feel confident.Terry
-
There are 2 particular lines, which is not repeated:
<link rel="canonical" href="https://mywebsite.com/en/truth.html" />and
<img src="index_files/flag_lang_de.jpg" width="28" height="19" title="de" alt="de" /></a> <a href="https://mywebsite.com/en/love.html"><img src="index_files/flag_lang_ru.jpg" width="28" height="19" title="ru" alt="ru" /></a>So, to be much better understood. I translated the site into ten languages.
For french section I have
href="https://mywebsite.com/fr/truth.html">
For russian section I havehref="https://mywebsite.com/ru/truth.html">so on. See those little De / FR / Ru / Hi / Ar …
I want to check if there is any link that I omitted (in the German section, “de”), and this link for german section is only found in the line with
<img src =Note that the links in English and German are the same, only the content of the html files is different.
the line with
<canonicalrepresents the page in English. For example:https://mywebsite.com/en/truth.htmlthe
<img src=.. taghas also a link, but that link must behttps://mywebsite.com/de/truth.htmlnot the same as canonicalhttps://mywebsite.com/en/truth.htmlThat is why I must find those files that doesn’t contain the same link on canonical an <img …de> tag. If are identically, means that I miss to translate the german section ( /de/ ). Because I copy the file from english, and translated only the text.
-
@guy038 said in Regex: Find those files that doesn't contain the same link in 2 different html tags:
I’m really sorry but I still don’t understand what is your goal !
I could see early on that this was where this thread was going to go; sometimes you can just “spot them”. :-)
Kudos to @guy038 and @Terry-R for carrying things on… -
I believe, much more simple was to use the
?!operators.Find with Regex:
alt="de" /></a> <a href="https://mywebsite.com/(?!de)because the important was not to have the same link for english part. Once it does not have EN it means that it is not the same. ;)
-
Hi, @hellena-crainicu, @terry-r, @alan-kilborn and All,
@hellena-crainicu, in this post, you provided an
HTMltext which contained this very long line :<a href="https://mywebsite.com/hope.html"><img src="index_files/flag_lang_ro.jpg" title="ro" alt="ro" width="28" height="19" /></a> <a href="https://mywebsite.com/fr/book.html"><img src="index_files/flag_lang_fr.jpg" title="fr" alt="fr" width="28" height="19" /></a> <a href="https://mywebsite.com/en/truth.html"><img src="index_files/flag_lang_en.jpg" title="en" alt="en" width="28" height="19" /></a> <a href="https://mywebsite.com/es/green.html"><img src="index_files/flag_lang_es.jpg" title="es" alt="es" width="28" height="19" /></a> <a href="https://mywebsite.com/pt/yellow.html"><img src="index_files/flag_lang_pt.jpg" title="pt" alt="pt" width="28" height="19" /></a> <a href="https://mywebsite.com/ar/truth.html"><img src="index_files/flag_lang_ae.jpg" width="28" height="19" title="ar" alt="ar" /></a> <a href="https://mywebsite.com/zh/truth.html"><img src="index_files/flag_lang_zh.jpg" width="28" height="19" title="zh" alt="zh" /></a> <a href="https://mywebsite.com/hi/truth.html"><img src="index_files/flag_lang_hi.jpg" width="28" height="19" title="hi" alt="hi" /></a> <a href="https://mywebsite.com/de/truth.html"><img src="index_files/flag_lang_de.jpg" width="28" height="19" title="de" alt="de" /></a> <a href="https://mywebsite.com/ru/truth.html"><img src="index_files/flag_lang_ru.jpg" width="28" height="19" title="ru" alt="ru" /></a>In order to better see all the contents of this loooooong line, I split it into
10lines, corresponding to your10languages !<a href="https://mywebsite.com/hope.html"><img src="index_files/flag_lang_ro.jpg" title="ro" alt="ro" width="28" height="19" /></a> <a href="https://mywebsite.com/fr/book.html"><img src="index_files/flag_lang_fr.jpg" title="fr" alt="fr" width="28" height="19" /></a> <a href="https://mywebsite.com/en/truth.html"><img src="index_files/flag_lang_en.jpg" title="en" alt="en" width="28" height="19" /></a> <a href="https://mywebsite.com/es/green.html"><img src="index_files/flag_lang_es.jpg" title="es" alt="es" width="28" height="19" /></a> <a href="https://mywebsite.com/pt/yellow.html"><img src="index_files/flag_lang_pt.jpg" title="pt" alt="pt" width="28" height="19" /></a> <a href="https://mywebsite.com/ar/truth.html"><img src="index_files/flag_lang_ae.jpg" width="28" height="19" title="ar" alt="ar" /></a> <a href="https://mywebsite.com/zh/truth.html"><img src="index_files/flag_lang_zh.jpg" width="28" height="19" title="zh" alt="zh" /></a> <a href="https://mywebsite.com/hi/truth.html"><img src="index_files/flag_lang_hi.jpg" width="28" height="19" title="hi" alt="hi" /></a> <a href="https://mywebsite.com/de/truth.html"><img src="index_files/flag_lang_de.jpg" width="28" height="19" title="de" alt="de" /></a> <a href="https://mywebsite.com/ru/truth.html"><img src="index_files/flag_lang_ru.jpg" width="28" height="19" title="ru" alt="ru" /></a>Now, if we isolate the line, relative to German, we get :
<a href="https://mywebsite.com/de/truth.html"><img src="index_files/flag_lang_de.jpg" width="28" height="19" title="de" alt="de" /></a> Apparently, in that line, the link
<a href="https://mywebsite.com/de/truth.html">seems to occur fisrt and the partalt="de"seems to occur later !Now the regex of your last post seems to search, first for the
alt="de" /></a> string, followed with a space char and then, for the beginning of theatag :<a href="https://mywebsite.com/(?!de)So, exactly the opposite that your previous example !? Again, I totally confused ! Could you provide us an exact and real example ?
Best Regards,
guy038
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login