Replacing text from x to y
-
Fellow Notepad++ Users,
Could you please help me the the following search-and-replace problem I am having?
I want to replace (remove) a part of many .txt files at once. These parts are different but they start and end with the same words. Is it possible to do that?Here is the data I currently have (“before” data):
state={ id=774 name="STATE_774" history={ owner = FRA add_core_of = CHA victory_points = { 2081 1 } buildings = { infrastructure = 2 } } provinces={ 1473 1883 1993 2081 3123 3181 4897 4978 7919 9152 13138 13211 } manpower=1442456 buildings_max_level_factor=1.000 state_category=pastoral }Here is how I would like that data to look (“after” data):
state={ id=774 name="STATE_774" provinces={ 1473 1883 1993 2081 3123 3181 4897 4978 7919 9152 13138 13211 } manpower=1442456 buildings_max_level_factor=1.000 state_category=pastoral }I have no idea how to do something like that. What is similar in all files is history={ at the beginning and } at the end. But there are few more } and it has to be the last one that is under the history={
Could you please tell me if something like that is possible and how to do that?
Thank you.
-
Hello, @mleczny-sernik and All,
I’ve got a nice solution which is a bit difficult to explain, because it uses a particular kind of regex, called recursive regex ! You get this kind of regex when a subroutine call to a group, with the syntax
(?#), is located within the group it refers to !
Here is the road map :
-
Open the Replace dialog (
Ctrl + H) -
SEARCH
(?-i)^\h*history=(\{(?:[^{}]++|(?1))*\})\R+ -
REPLACE
Leave EMPTY -
Tick, preferably, the
Wrap aroundoption -
Select the
Regular expressionsearch mode -
Click, either, once on the
Replace Allbutton or several times on theReplace button
Voila !
-
Note that the inner part of the regex
(\{(?:[^{}]++|(?1))*\}), between the outer parentheses, define a group1which matches, successively :-
An opening brace character
{ -
Then, in a non-capturing group
(?:•••), repeated0or more times, matching either :-
The largest range of characters, all different from
{and}, without any possible backtracking due to its atomic quantifier++ -
A subroutine call
(?1)to group1which is, itself, an inner block{•••••}
-
-
An ending brace character
}
-
So, this regex will match any history section IF, of course, it contains a well-balanced number of
{and}delimiters, even an empty history section ashistory={}with its line-break chars ;-))Best Regards,
guy038
-
-
@Mleczny-Sernik Hi. There are a few things about your description that are open to interpretation.
I have a regex solution that is very rigid, and only matches the type of whitespace, and the amount of indentation, shown in your sample.
Since the regex is deleting several lines, I prefer, as a starting point, to delete too little rather than too much.
I will assume the block you want deleted:
- always starts exactly with an empty line, then (on next line) a single TAB, then the text “history={”
- always ends exactly with: a line that contains one TAB, then text ‘}’, and nothing else
If the files you are processing are human-typed there’s a good chance that variations in whitespace, or commenting, will cause this solution to be incomplete. If the files are machine made, chances are better the solution will meet your need.
Find what:
^\r\n^\thistory={.*?^\t}\r\n
Ensure the “Replace with:” entry is completely empty
Do check the “. matches newline”Do not rely on it without a lot of testing.
You may wish to enable (Np++ menu) “View - Show Symbol - Show all chars” when examining files before and after applying the regex.
-
@guy038 Hi. Your solution is far, far, far more sophisticated than anything I could have come up with.
However, re:
IF, of course, it contains a well-balanced number of { and } delimiters
what if a goofball, perhaps someone named something like Neil, was the author of one of these files, and in the course of development, he left one of the files to be processed looking something like this:
history={ owner = FRA add_core_of = CHA victory_points = { 2081 1 } //structures = { // obsolete name! clean out after testing buildings = { infrastructure = 2 } }This would be a problem, I believe.
-
@Neil-Schipper said in Replacing text from x to y:
what if a goofball, perhaps someone named something like Neil, was the author of one of these files, and in the course of development, he left one of the files to be processed looking something like this:
In every solution, whether it be a regex; simple to complex like @guy038 one here; through pythonscript code, through UDL’s, they ALL rely on data integrity.
So if someone comes to the forum seeking help and shows a “sample” of their data, the solution, whatever it may be will be based on that example. We may give a caveat, such as @guy038 did here, the need for balanced delimiters. In the end it is always the OP’s responsibility to provide enough “evidence” that we can trust our solution to act appropriately on the data.
If you were to read back through a lot of the posts in this forum, you will find however that the OP’s generally have a naive view of their data. Often the forum member(s) who are striving to help are the ones to ask the “right” questions about the data and thus jolt the OP enough that they gain a new respect for their data. Only through that process can the solution providers believe enough in their solution to provide it, albeit sometimes with a caveat.
Often solution providers will also suggest running the solution over a copy of the data and vetting the result before fully integrating it into their workflow.
I think your question, whilst having some merit is over thinking the process. OP’s ask for help. Solution providers may ask for additional information and/or examples. A solution is then provided, sometimes with information on how it works and what is required of the data to get valid results and it’s left to the OP to test. Hopefully the OP comes back with a “thank you” (amazing how many times we NEVER get that) so we know it solved their problem, or a gotcha so the process repeats with the additional information loaded in.
So don’t sweat it and get too bogged down in what-ifs when helping someone. You learn to rely on judgement and sometimes in the end the solution doesn’t work through no fault of the person helping.
Terry
-
Hi, @mleczny-sernik, @neil-schipper, @terry-r and All,
Neil, to solve the case you mention, we have
3possibilities :-
The first possibility is quite obvious :
-
Open the Find dialog (
Ctrl + F) -
Type in a
{or a}char in the Find what zone -
Tick the
Wrap aroundoption -
Click on the
Countbutton
=> The number of
{chars must be identical to the number of}chars ! If not, the program’s logic is broken and I wish you good luck to identify the missing or extra brace ! -
-
The second possibility is to decide that an escaped
{or}char will be considered as a normal character, different from[{}].-
=> Any allowed character, inside a
{•••••}section, is represented by the regex(?:\\[{}]|[^{}]) -
Then, the search regex to use becomes
(?-i)^\h*history=(\{(?:(?:\\[{}]|[^{}])++|(?1))*\})\R+ -
Of course, your comment line must then be re-written as
//structures = \{ // obsolete name! clean out after testing
-
-
The third possibility is to use the following regex which identifies the longest contiguous zone with an identical number of opening brace and ending brace character(s)
-
This magic regex is
(?:[^{}]*(\{(?:[^{}]++|(?1))*\}))+[^{}]*|[^{}]+ -
Do not tick the
Wrap aroundand perform some tests, moving the caret to different locations, in your program, which should help you, to some extent, to spot the guilty brace char ! -
Note that a simple text, without any brace char, is also matched by this regex. Logical, this text contains the same number of opening and ending brace chars :
0;-))
-
BR
guy038
P.S. :
You may test the regex
(?:[^{}]*(\{(?:[^{}]++|(?1))*\}))+[^{}]*|[^{}]+against this text, pasted in a new tab :{{{{ab{{{cd{{{}}}}}ef}}}}}} 1234 567 89198765 43210x 0 {{ab{{{{cd{{{ef{{}}}}}gh}}}}ijkl}}}} 12 3456 789 1119876 5432 10xx 010 {{{{{{ab{cd{ef{{{}}}}}gh}ijkl}}}mn}}}}} 123456 7 8 91119876 5 432 10xxx 010 {{01ab{cd{ef23gh{ij45kl}mn}op{{qr67st}uvwx}34}yz}}128956}abc 12 3 4 5 4 3 45 4 3 2 10 xFor example , move your cursor at the beginning of each line and click on the
Find Nextbutton ! This damn regex is never wrong !! -
-
Hi Guy,
I played with your bullet 3 regex against your sample text. It works, and it’s very cool.
If you wished (and you do not need to prove yourself as someone who likes challenges – I for sure would not try it) you could try to make it so that on successive Find Next clicks, rather than resume from text after the entire prior match, it could crawl from where prior match started to the next open brace and go from there, allowing user to see the enclosed region shrink bit by bit… Leading to the next challenge: going left bit by bit, and watching the region grow… maybe that’s too many levels of super-cool, I dunno… and then I remember that I/we already get matching brace highlighting (maybe only for some known languages?) (I forget if it’s a native Np++ feature or provided by a plugin.)
I tried the regex in your 2nd bullet and although it still works against the original sample code, it’s not working for me with that extra line I threw in, with the open brace but backslash-escaped. Don’t know why, and I’m not inclined to try to debug it; I’m really a noob in regex flow control.
Your conclusion in Bullet 1 is not strictly correct (unless file were stripped of all comments) but it’s not worth sweating about.
-
@Neil-Schipper said in Replacing text from x to y:
it’s not working for me
Sorry, I should have said why: it’s matching one more level of right brace.
-
Hi, @mleczny-sernik, @neil-schipper, @terry-r and All,
Ah…Ok ! So, I improve this magic regex to this version :
(?:[^{}]*(\{(?:[^{}]++|(?1))*\}))+[^{}]*|[^{}]+|}+I just added the alternative|}+at the end of the regexAgain, test it against the text below :
-
Move your caret/cursor right before each
¤char, first -
Note that I indicated, with the
^character, the char changed in the5following lines¤{{{{ab{{{cd....., in comparison with the first one -
Right above each line
¤{{{{ab{{{cd.....:-
Any range
-.....-represents a match of the main part(?:[^{}]*(\{(?:[^{}]++|(?1))*\}))+[^{}]*|[^{}]+ -
Any range
b.....brepresents a match of the final part{+
-
---------------------------b----------------------------------bb------------------------------------bbb--------------------------------------------------------b--- ¤{{{{ab{{{cd{{{}}}}}ef}}}}}}{{ab{{{{cd{{{ef{{}}}}}gh}}}}ijkl}}}}{{{{{{ab{cd{ef{{{}}}}}gh}ijkl}}}mn}}}}}{{01ab{cd{ef23gh{ij45kl}mn}op{{qr67st}uvwx}34}yz}}128956}abc ---------------------------------------------------------------b------------------------------------bbb--------------------------------------------------------b--- ¤{{{{ab{{{cd{{{}}}}}ef}}}}}{{{ab{{{{cd{{{ef{{}}}}}gh}}}}ijkl}}}}{{{{{{ab{cd{ef{{{}}}}}gh}ijkl}}}mn}}}}}{{01ab{cd{ef23gh{ij45kl}mn}op{{qr67st}uvwx}34}yz}}128956}abc ^ ---------------------------b------------------------------------------------------------------------bbb--------------------------------------------------------b--- ¤{{{{ab{{{cd{{{}}}}}ef}}}}}}{{ab{{{{cd{{{ef{{}{}}}gh}}}}ijkl}}}}{{{{{{ab{cd{ef{{{}}}}}gh}ijkl}}}mn}}}}}{{01ab{cd{ef23gh{ij45kl}mn}op{{qr67st}uvwx}34}yz}}128956}abc ^ ---------------------------b----------------------------------bb----------------------------------bbbbb--------------------------------------------------------b--- ¤{{{{ab{{{cd{{{}}}}}ef}}}}}}{{ab{{{{cd{{{ef{{}}}}}gh}}}}ijkl}}}}{{{}{{ab{cd{ef{{{}}}}}gh}ijkl}}}mn}}}}}{{01ab{cd{ef23gh{ij45kl}mn}op{{qr67st}uvwx}34}yz}}128956}abc ^ ---------------------------b----------------------------------bb------------------------------------bbb------------------------------------------------bb------b--- ¤{{{{ab{{{cd{{{}}}}}ef}}}}}}{{ab{{{{cd{{{ef{{}}}}}gh}}}}ijkl}}}}{{{{{{ab{cd{ef{{{}}}}}gh}ijkl}}}mn}}}}}{{01ab{cd}ef23gh{ij45kl}mn}op{{qr67st}uvwx}34}yz}}128956}abc ^ ---------------------------------------------------------------------------------------------------bbbb--------------------------------------------------------b--- ¤{{{{ab{{{cd{{{}}}}}ef}}}}}{{{ab{{{{cd{{{ef{{}{}}}gh}}}}ijkl}}}}{{{}{{ab{cd{ef{{{}}}}}gh}ijkl}}}mn}}}}}{{01ab{cd}ef23gh{ij45kl}mn}op{{qr67st{uvwx}34}yz}}128956}abc ^ ^ ^ ^ ^In this last example, the regex automatically advances to the next well-balanced range of characters ! I note, with an lower-case letter
s( for skipped ), the character(s) skipped :---------------------------------------------------------------------------------------------------bb---bbs--------------------------ss--ssss--------------s------ ¤{{{{ab{{{cd{{{}}}}}ef}}}}}{{{ab{{{{cd{{{ef{{}{}}}gh}}}}ijkl}}}}{{{}{{ab{cd{ef{{{}}}}}gh}ijkl}}}mn}}}abc}}{{01ab{cd}ef23gh{ijkl}mn}op{{12{{{{34{}{qr}st{uv}{{34}yz
Now, regarding the second bullet of my previous post
(?-i)^\h*history=(\{(?:(?:\\[{}]|[^{}])++|(?1))*\})\R+, if I escape the opening brace, in you comment line, as a convention which changes the brace as an ordinary character, giving thishistorysection :history={ owner = FRA add_core_of = CHA victory_points = { 2081 1 } //structures = \{ // obsolete name! clean out after testing buildings = { infrastructure = 2 } }The regex does match all the section ! So could you show me an example where the regex fails to match this
historyblock ?
Finally, my answer, in bullet
1was, indeed, rather vague and I suppose that most IDE has tools to identify and correct the unmatched blocks of programming languages ! But running first my simple work-around means necessarily an error when numbers are different, isn’t it ?Best Regards,
guy038
-
-
Thanks everyone for help :) It worked
-
@guy038 said in Replacing text from x to y:
The regex does match all the section ! So could you show me an example where the regex fails to match this history block ?
I’m seeing it match past end of state’s } (includes all trailing newlines) rather than past history’s as desired:
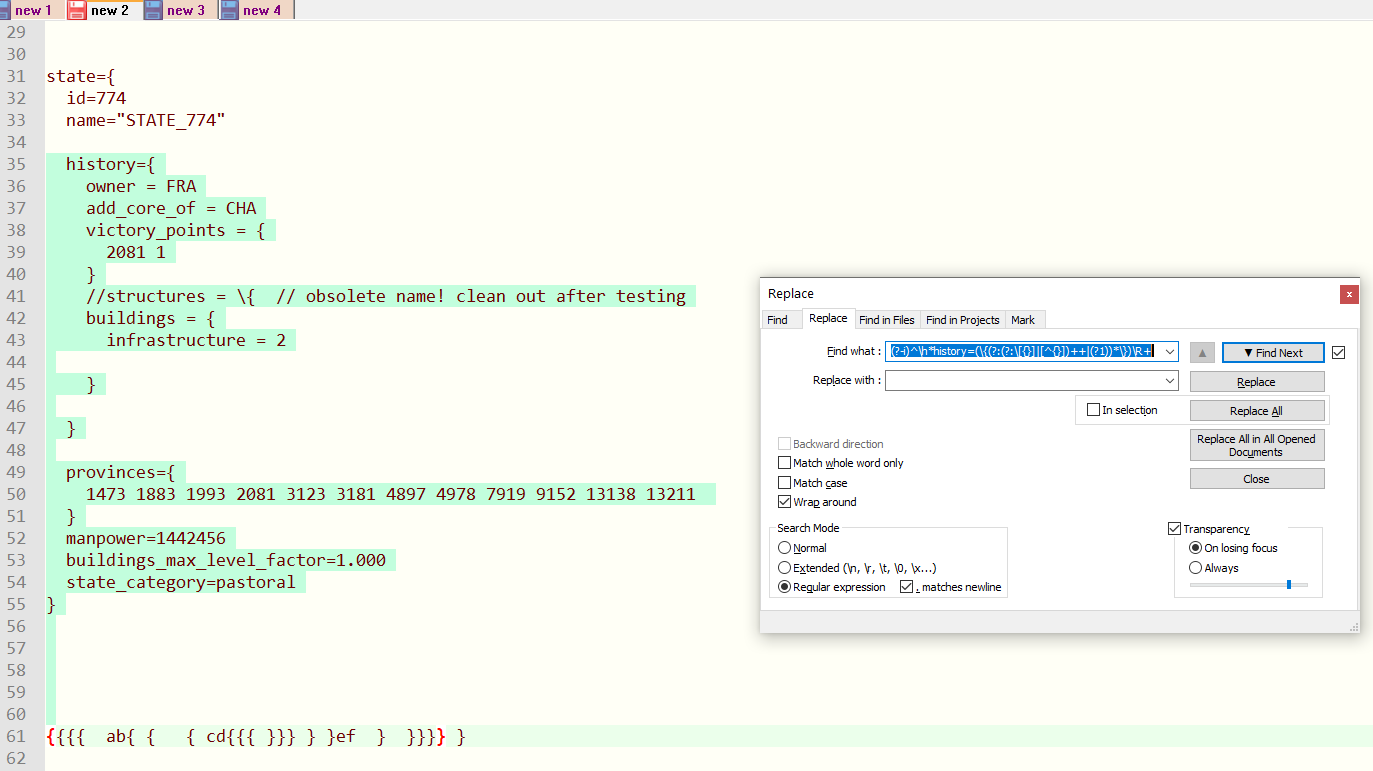
v7.9.5 64-bit -
Ah, yes ! I needed to indicate two consecutive
\characters in the regex ( in order to search for a literal\char ! )So the correct regex is rather :
(?-i)^\h*history=(\{(?:(?:\\\[{}]|[^{}])++|(?1))*\})\R+BR
guy038
-
@guy038 said in Replacing text from x to y:
So the correct regex
Confirmed. In hindsight I should’ve spotted it myself – every instance of backslash-leftbracket on this site should be treat with suspicion and caution.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login