how to remove all lines that contains duplicates.
-

hi guys, i have a 8k lines text. and for some reason 800 lines, are duplicated, but only the first 10 characters are duplicated (phone number) like the first line with 5415359225 is duplicated like 2 times, but the second line continue with other name so is not the whole line unique. see example:
9144506800 ; Dear James A Brantley.
9144506800 ; Dear James A.Somehow i need to delete lines that repeat(duplicate) the first 10 characters only. Sorry for my english, hope you understand!
i alrady tried this:SEARVH
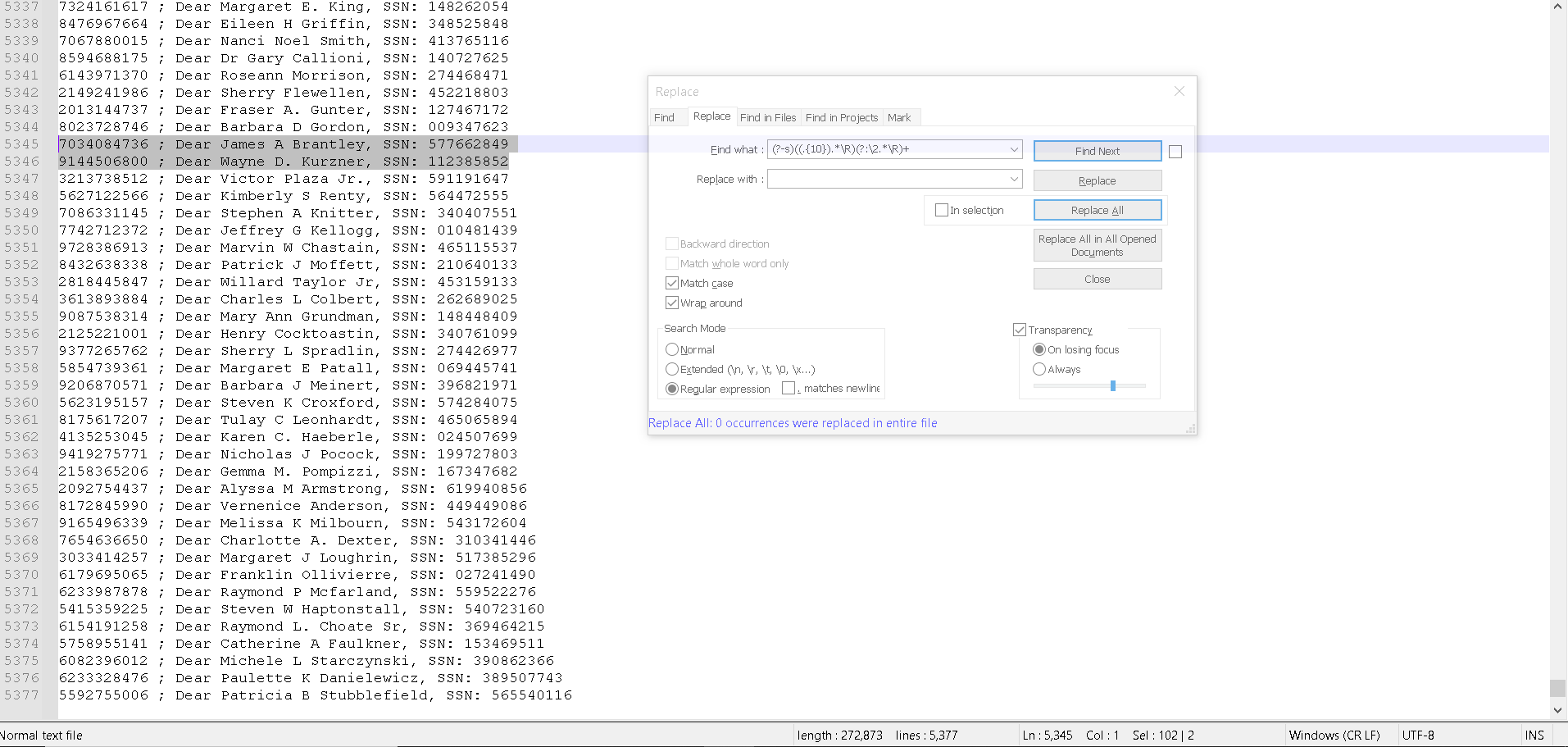
(?-s)((.{15}).*\R)(?:\2.*\R)+
REPLACE\1nothing happened, something i do wrong… idk what. i need a step by step guide i guess… Thank!
–moderator added forum formatting tags to regex to unhide the * in the regex
-
@andrea-mark-shaw said in how to remove all lines that contains duplicates.:
(?-s)((.{15}).*\R)(?:\2.*\R)+I’m not sure why you think it didn’t do anything.
5415259225 ; Dear Steven W Haptonstall 6154191258 ; Dear Someone 9144506800 ; Dear James A Brantley. 9144506800 ; Dear James A.then run that regex, I get
5415259225 ; Dear Steven W Haptonstall 6154191258 ; Dear Someone 9144506800 ; Dear James A Brantley.But I’m also not sure why you say “first 10 characters only”, but then use
{15}in your regex: 10 ≠ 15. -
wow, that was a fast answer, thank you very much. I did with 10 but idk what should exactly to do… is that right?
-
@andrea-mark-shaw said in how to remove all lines that contains duplicates.:
I did with 10 but idk what should exactly to do… is that right?
“right” by what definition? Given the example data that I showed,
(?-s)((.{10}).*\R)(?:\2.*\R)+will also remove the duplicate, and it means it’s really only matching on 10 characters (which is what you said you wanted), instead of matching on the 15 characters from your original regex. Whether that gets rid of all the “duplicates” that you want it to can only be known by you – and that’s the only meaningful definition of “right” in such tasks.(And note that either regex shown will have a problem if the duplicate is on the last two lines of the file, without a blank line after, because then the final
\Rdoesn’t match, and so the final duplicate isn’t removed. Just something to watch out for. If you want it to work even if the last line of the file doesn’t have a newline, then(?-s)((.{10}).*\R)(?:\2.*(\R|\Z))+, so it can match newline or end-of-file. -
Clarifications are needed here.
True or False: the duplicates will always be adjacent (= consecutive = one immediately following the other). You have sent mixed signals on this.
True or False: when a duplicate is identified, the first of the pair is always to be preserved (kept, retained), and the second of the pair is always to be removed (deleted, discarded). This is implied but should be clearly stated.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login