Remove unwanted Carriage Return
-
@neil-schipper said in Remove unwanted Carriage Return:
(?<!\R)\R(?!\R)
(?<[^\R])\R(?=[^\R])
My best explanation is that \R can be either 1 or 2 bytes, but a look-behind must be fixed width. Any comment?Since a negative look-behind must be fixed width, the way I use to get a valid expression is to replace
\Rby a\vor vertical tab, as follows:(?<!\v)\R(?!\R) -
@astrosofista said:
replace \R by a \v
Confirmed, and good to know, thanks. It’s strange that both constructs encode the 1 or 2 byte newline sequences, but only \v is valid.
a negative look-behind must be fixed width
Both positive and negative look-behinds have this limitation (perhaps what you meant to say).
-
@neil-schipper said in Remove unwanted Carriage Return:
Both positive and negative look-behinds have this limitation (perhaps what you meant to say).
Nope.
vs
Notice that only the lookbehind has the
pattern must be of fixed lengthcaveat; the lookahead can be variable width.And it’s very easy to test:
lookbehind
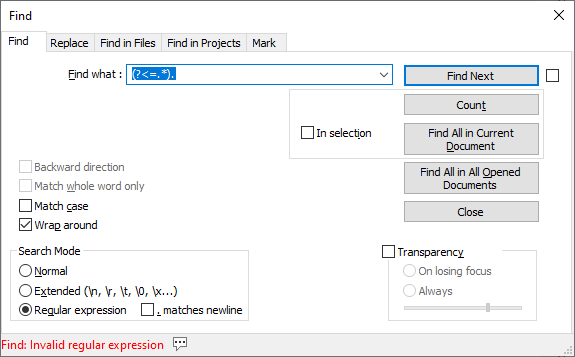
lookahead
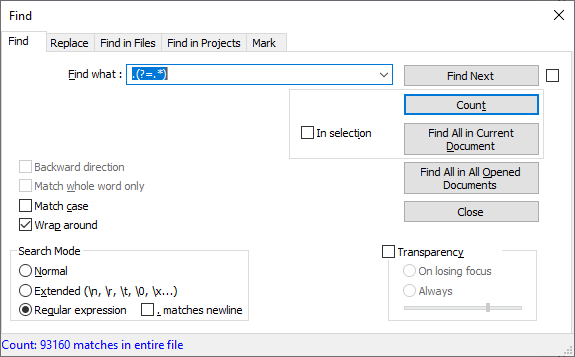
-
@peterjones My comment pertains to the two kinds of look-behind, positive
(?<=and negative(?<!(and I’ve tested both), and makes no mention of the two kinds of look-aheads. -
replace \R by a \v
This doesn’t make sense in the desired usage above.
A\Rcan be one or two characters, thus not fixed length.
A\vis always only one character, when it matches. -
@alan-kilborn said in Remove unwanted Carriage Return:
A \v is always only one character, when it matches.
Good point. But @astrosofista’s trick does work with conventional UTF-8 \r\n line endings; it’s a more tolerant way of simply specifying \n, and would also handle other non-standard line ending formats.
Your comment reminds me that it’s risky to get too used to throwing \v around: if used in a matched text expression which will be replaced, it’s easy to inadvertently destroy a pristine file’s uniform line endings.
-
Sorry, I misread. Time to stop trying to think for the evening, apparently
-
@neil-schipper said in Remove unwanted Carriage Return:
@astrosofista’s \v trick does work with conventional UTF-8 \r\n line endings; it’s a more tolerant way of simply specifying \n, and would also handle other non-standard line ending formats.
I don’t think it has value. If you need to match \r\n then \v\v will match it, but it will also match other things (that maybe aren’t wanted), so…no real point in it.
-
@neil-schipper said in Remove unwanted Carriage Return:
Both positive and negative look-behinds have this limitation (perhaps what you meant to say).
Yes, that’s what I meant. My apologies for the possible misunderstanding.
Anyway, although both lookbehinds share such limitation, they differ because in the case of the positive lookbehind we have at our disposal the alternative of the operator \K, but no operator for the negative one.
It would be nice if this issue could be fixed sometime.
-
@astrosofista said in Remove unwanted Carriage Return:
It would be nice if this issue could be fixed sometime.
It’s just a coincidence that
\Kcan be used as a variable length positive lookbehind.
Because there is no equivalent for a negative lookbehind, doesn’t mean there’s an issue that could be “fixed”. -
@alan-kilborn said in Remove unwanted Carriage Return:
@astrosofista said in Remove unwanted Carriage Return:
It would be nice if this issue could be fixed sometime.
Because there is no equivalent for a negative lookbehind, doesn’t mean there’s an issue that could be “fixed”.
The lookbehind fixed-length restriction is caused by the Boost::regex library, not by anything Notepad++ does. So the issue would have to be fixed there.
To find more of the history of Boost::regex, and how long they’ve known about that restriction, I went to https://www.boost.org/doc/libs/ (I kept cutting stuff out of the 1.78 URL until I found a page that listed what other versions were available), and looked at old versions until I found the earliest Boost::regex that I noticed lookbehind syntax documented: v1.33.1 from 2004 – where they already note that restriction. If they’ve known about that limitation since 2004 and never gotten rid of that restriction, there’s probably a good technical reason that it’s too hard to implement, and it’s not likely to change anytime soon.
-
@peterjones said in Remove unwanted Carriage Return:
there’s probably a good technical reason that it’s too hard to implement, and it’s not likely to change anytime soon.
I think the limitation probably is rooted in runtime complexity for the engine that would provide a poor user experience (way too long for it to examine every possible match, potential for engine catastrophic overflow, etc.). Just my hunch.
-
@alan-kilborn @astrosofista @PeterJones
Open ended variable length negative look-behinds using subexpressions like
hello.*would have huge performance implications.Upper-bounded variable length expressions like
dog|puppyor\d{1,500}would be “easy-peasy” (ie, computers doing exactly what computer are good at doing), and extremely useful. -
@neil-schipper said in Remove unwanted Carriage Return:
would be “easy-peasy”
I am sure if you can get that PR written and submitted to Boost::regex, they would be quite happy for your implementation. ;-)
-
@neil-schipper said in Remove unwanted Carriage Return:
dog|puppy
Also, since Boost::regex was derived as a PCRE, with roots in Perl, it still has the TIMTOWTDI philosophy:
(?<=dog|puppy)chowcan be represented as((?<=dog)|(?<=puppy))chow
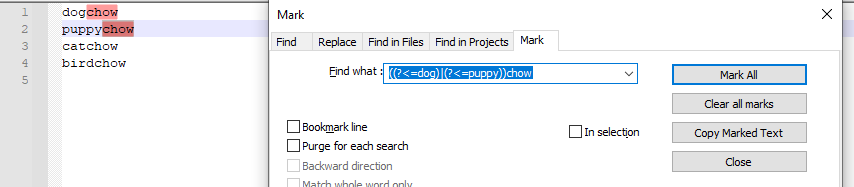
(?<!dog|puppy)chowcan be represented as((?<!dog)(?<!puppy))chow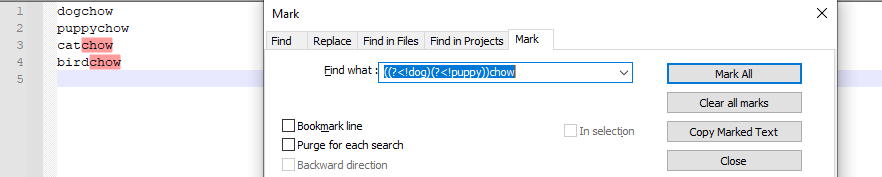
- note that because of De Morgan’s Laws,
NOT(A OR B)becomes NOT(A) AND NOT(B)`
- note that because of De Morgan’s Laws,
\d{1,500}is admittedly harder to come up with an equivalent lookbehind that will work. And by harder, I mean, I couldn’t in the last 5 minutes. (Specifically, we obviously don’t want to construct 500 alternatives manually, or fill up that space in the regex. That would have been the “easy” alternative, but not practical.) -
@guy038 said in Remove unwanted Carriage Return:
… the parts [^\R] just match any character … But … R … [and r if case sensitivity]
Yes, confirmed.
Interestingly, however, I also confirmed that each of these sets:
[\d] [\w] [\r] [\n] [\x31] [^\d] [^\w] [^\r] [^\n] [^\x31]do match the specified character class or control character, or their complement, exactly “as advertised”.
I couldn’t find any reference to the extremely exceptional behavior of
[\R]and[^\R]either in the npp docs or in the 1.7.8 Boost doc Peter linked to earlier.I can’t imagine I’m the first to notice this.
-
@neil-schipper said in Remove unwanted Carriage Return:
extremely exceptional behavior of [\R] and [^\R]
IMO there is no exceptional behavior here.
Everything inside[…]is “one character”.[\d]is one digit character
etc.Because
\Ris variable and can be one or two characters, its use inside[…]is not considered.Thus
[\R]will matchR(orrif not case sensitive specified).Easy enough to do
[\r\n]anyway, right? -
@alan-kilborn said in Remove unwanted Carriage Return:
Everything inside […] is “one character”.
You are backfilling into the spec(s) from observation a concept that isn’t there, even though observation indeed suggests that’s a plausible description of the internals.
Reading the specs, \d and \R are “peers”, and behave thusly in other contexts, such as \d+ and \R+, and, (?=\d) and (?=\R).
Easy enough to do [\r\n] anyway, right?
There’s the loss of generality/abstraction. The specs themselves suggest we expect to encounter
\x85|\x{2028}|\x{2029}line endings now and again.If 0.5% of people seeking regex help had files in those formats, an experienced person such as yourself would not simply include
[\r\n]in a solution without elaborating on its limitations. -
 N Neil Schipper referenced this topic on
N Neil Schipper referenced this topic on
-
N Neil Schipper referenced this topic on
-
Ok, so I guess you can persist with what you’re talking about, but I suppose you’ll just be talking to yourself. :-)
-
Reading the specs, \d and \R are “peers”,
I disagree. But I do agree that maybe it could be explained better in the Notepad++ Searching document. However, that document does point you to the canonical Boost regex documentation, which is the official spec for the regex used by Notepad++; and, in my opinion, the Boost documents can only be interpreted to say that
\Rbehaves differently than\dor\ror\nor even\hor\vor\s.In that document, you will see that
\r,\n,\t,\vand others are listed under the sentence, “The following escape sequences are all synonyms for single characters:” – meaning that each of those sequences matches only a single character at a time. So\vmight match any of the vertical spaces (CR, LF, and the weird ones), but a single\vin a regex will only match a single character at a time. So if you had the stringAB\r\nand matched for\v, the first FIND would find just the\r.The
\Ris described in its own section called “Matching Line Endings”, which shows that it expands into(?>\x0D\x0A?|[\x0A-\x0C\x85\x{2028}\x{2029}]), which is an expression with parentheses around it and including an internal alternation|– searching for(?>), you find it’s the syntax for an independent sub-expression . This is different than all the single-character escapes listed previously. With the same stringAB\r\n, searching for\R, the first FIND would match the two-character sequence\r\n. The\Rbehaves differently than all those other single-character escapes, because it can match multiple characters at once.Then if you back up a few paragraphs to Character sets, you will see the rules for character sets, including the sentence, “A bracket expression may contain any combination of the following:”. The sub-sections that follow underneath that are “Single characters”, “Character ranges”, “Negation”, “Character classes”, “Collating Elements”, “Collating Elements”, “Equivalence classes”, “Escaped Characters”, and “Combinations”. Note that none of those include “independent sub-expression”, or any other term that references a parentheses-based expression.
The bracket
[]-based character sets cannot contain parentheses()-based expressions. That is why\Rdoes not work in a bracket[]-based class.An updated version of the usermanual mentions of
\Rcan be found at https://github.com/pryrt/npp-usermanual/blob/backslashBigR/content/docs/searching.md (that temporary URL will be changed to the permanent URL by moderator power once the changes are merged into the main usermanual repository)- First, it’s been moved out of the Control Characters section into its own special section:

- Second, the Character Classes section has been improved to note that character classes cannot contain any parentheses-based group, including
\R.
- Third, in the Character Escape Sequences section, which contains the
\h,\v, and\s(and thus people might assume that\Rfits in there), it is clarified that being a group causes\Rto be treated differently:
Hopefully, this is sufficient description in enough locations that it will prevent future confusion when users are looking up the meaning of
\Rand whether or not it can go inside a character class. - First, it’s been moved out of the Control Characters section into its own special section:
-
N Neil Schipper referenced this topic on
-
N Neil Schipper referenced this topic on
-
H Hellena Crainicu referenced this topic on
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login