Custom lexer and Unicode UTF-8 text file content
-
I’m updating the CSV Lint plug-in which has a custom lexer for syntax highlighting, so Notepad++ adds colors to the data files.
It works pretty well for the most part, however it still has a bug with special characters in combination with the Windows
Unicode UTF8 setting, as described in this postIn Windows 10 and Windows 11 there is a setting “Use Unicode UTF-8 for worldwide language support”, see
Control Panel -> Clock and Region -> Region, tab “Administrative”, button “Change system locale”. When the Windows Unicode UTF-8 is enabled then Notepad++ codepage is set to65001, when it’s disabled then it’s1252(= English + most European languages, at least on my laptop).When Unicode UTF-8 is enabled and the user opens a textfile with
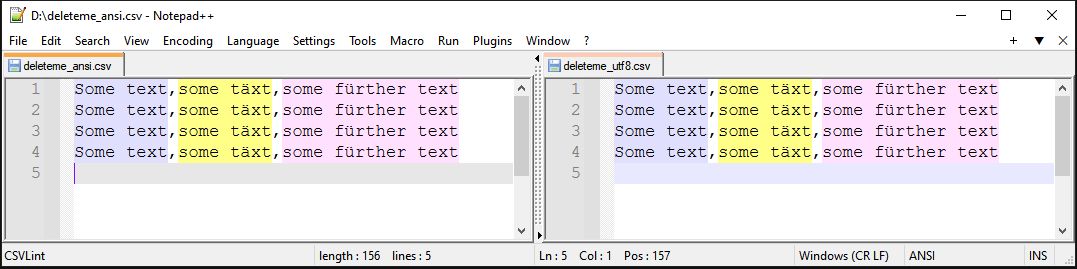
any non-ASCII characters (i.e. anything non-Englishëáพสระ你好etc) Notepad++ will internally have a different text-encoding and this causes problems with syntax highlighting. See screenshots below.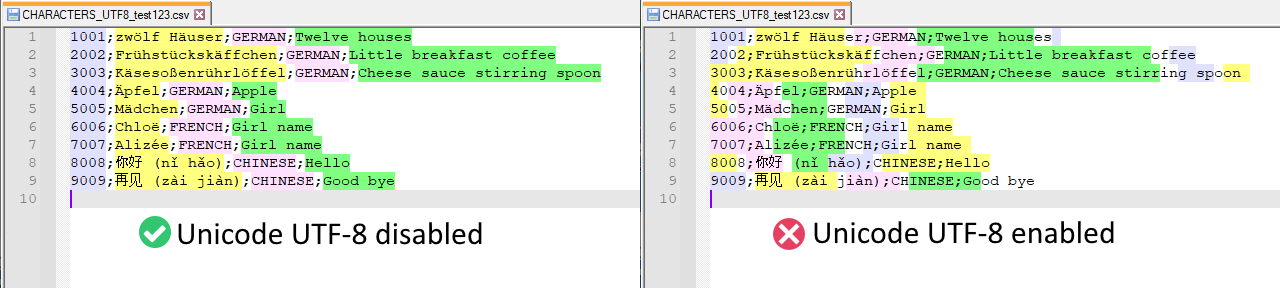
The problem is the way the lexer iterates through the text content. I won’t paste the complete code here but see a summary of the Lexer code below
public static void Lex(IntPtr instance, UIntPtr start_pos, IntPtr length_doc, int init_style, IntPtr p_access) { // .. IDocumentVtable vtable = (IDocumentVtable)Marshal.PtrToStructure((IntPtr)idoc.VTable, typeof(IDocumentVtable)); // allocate a buffer IntPtr buffer_ptr = Marshal.AllocHGlobal(length); vtable.GetCharRange(p_access, buffer_ptr, (IntPtr)start, (IntPtr)length); //.. // convert the buffer into a managed string string content = Marshal.PtrToStringAnsi(buffer_ptr, length); length = content.Length; nt start = (int)start_pos; for (i = 0; i < length - 1; i++) { // check for separator character char cur = content[i]; if (cur == ',') end_col = i; //.. // if end of column found if (bEndOfColumn) { // style the column vtable.StartStyling(p_access, (IntPtr)(start)); vtable.SetStyleFor(p_access, (IntPtr)(end_col - start), (char)idx); // etc.It probably should get the textfile content differently, but still be able to iterate through the character and byte positions somehow. I mean it should inspect each character to determine if it is the column separator, but at the same time should be able to find the correct parameters for the
StartStylingandSetStyleForfunctions.Any ideas on how to fix this?
-
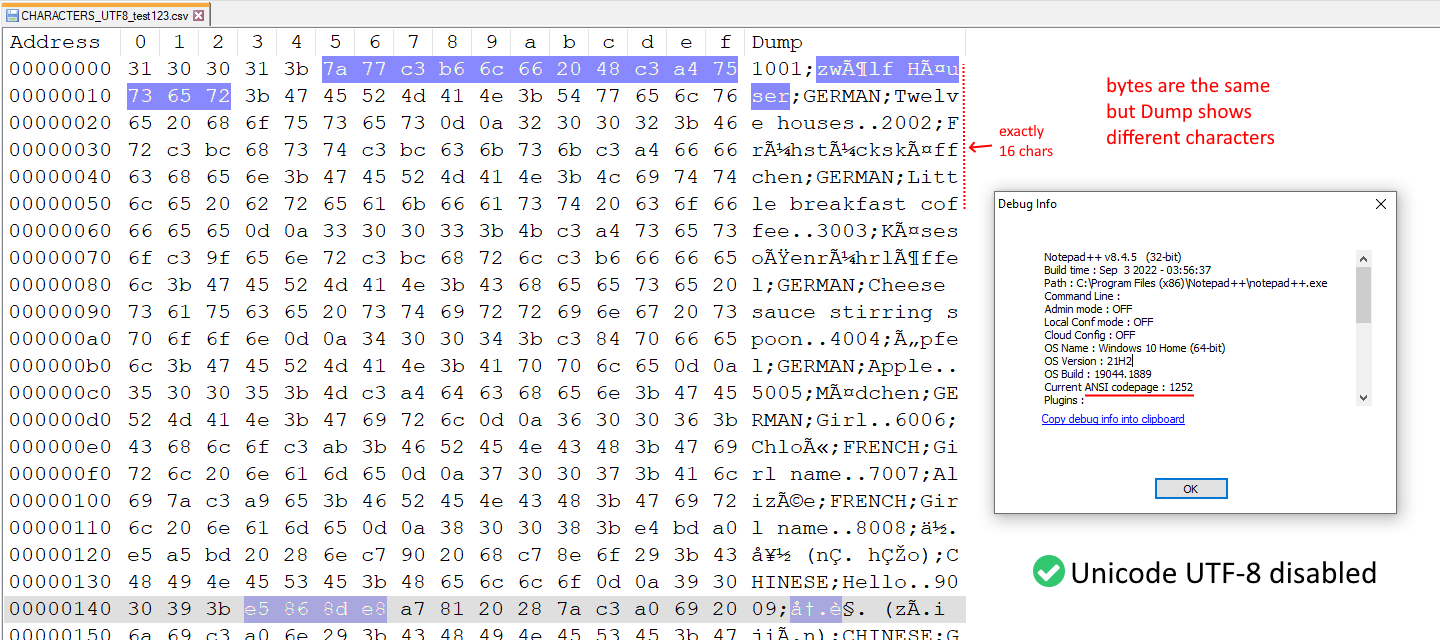
Btw you can also see the different “text parsing”(?) by using the Hex editor plug-in. See screenshots below.
Hex editor with Unicode UTF-8 disabled
Hex editor with Unicode UTF-8 enabled:
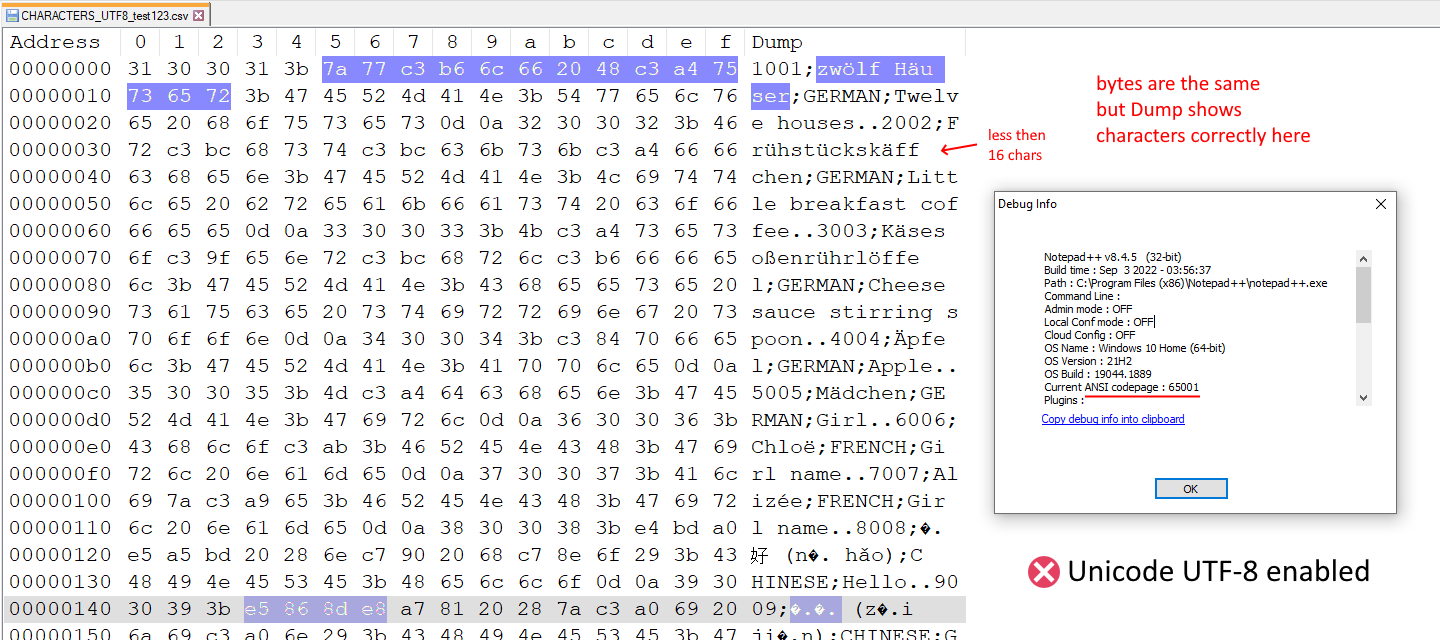
With Unicode UTF-8 disabled or enabled, the bytes of the text file are exactly the same in both. In the “Dump” part you can see extra characters when Unicode UTF-8 is disabled, and there are exactly 16 characters in one row. But when Unicode UT-8 is enabled, then the “Dump” displays the correct characters, although each row don’t always contain exactly 16 character.
Also, you can see that the out-of-sync colors are caused by how many “special characters” have been encountered up to that point in the text. See screenshot below.
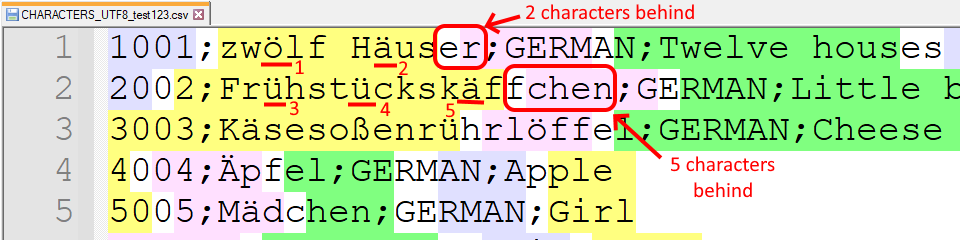
This is the content of the text file:
1001;zwölf Häuser;GERMAN;Twelve houses 2002;Frühstückskäffchen;GERMAN;Little breakfast coffee 3003;Käsesoßenrührlöffel;GERMAN;Cheese sauce stirring spoon 4004;Äpfel;GERMAN;Apple 5005;Mädchen;GERMAN;Girl 6006;Chloë;FRENCH;Girl name 7007;Alizée;FRENCH;Girl name 8008;你好 (nǐ hǎo);CHINESE;Hello 9009;再见 (zài jiàn);CHINESE;Good bye -
Hello @bas-de-reuver and All
Just a remark : as for me, as I’m French, this parameter can be found in :
Paramètres > Heure et Langue > LANGUE > Paramètres de la langue d'administration > Modifier les paramètres régionaux > Bêta : Utiliser le format Unicode UTF-8 pour une prise en charge des langues à l'échelle mondialeBest Regards,
guy038
-
A guess, maybe try PtrToStringAuto instead of
PtrToStringAnsi!? -
A guess, maybe try PtrToStringAuto instead of
PtrToStringAnsi!?No. The problem is that the separator-finding loop is only counting the lowest byte of every character. Higher code points occupy multiple bytes in UTF-8 (see for example how line 2 is off by the exact number of umlauts:
ö,ä). The CLRchartype transparently covers up the difference, since everything is UTF-16 internally.@Bas-de-Reuver, you should be comparing
bytes, notchars; like this:diff --git a/CSVLintNppPlugin/PluginInfrastructure/Lexer.cs b/CSVLintNppPlugin/PluginInfrastructure/Lexer.cs index 5e0c53d..0f8217b 100644 --- a/CSVLintNppPlugin/PluginInfrastructure/Lexer.cs +++ b/CSVLintNppPlugin/PluginInfrastructure/Lexer.cs @@ -467,8 +467,18 @@ public static void Lex(IntPtr instance, UIntPtr start_pos, IntPtr length_doc, in string content = Marshal.PtrToStringAnsi(buffer_ptr, length); // TODO: fix this; this is just a quick & dirty way to prevent index overflow when Windows = code page 65001 + // Start by assuming an ANSI CP like 1252 => 1 byte / character length = content.Length; + var byteBuf = new char[length]; + content.CopyTo(0, byteBuf, 0, content.Length); + byte[] contentBytes = System.Text.Encoding.Default.GetBytes(byteBuf); + if (OEMEncoding.GetACP() == 65001) + { + // CP UTF-8 => 1 or more bytes per character; count them all! + contentBytes = System.Text.Encoding.UTF8.GetBytes(byteBuf); + length = contentBytes.Length; + } // column color index int idx = 1; bool isEOL = false; @@ -576,10 +586,10 @@ public static void Lex(IntPtr instance, UIntPtr start_pos, IntPtr length_doc, in char quote_char = Main.Settings.DefaultQuoteChar; bool whitespace = true; // to catch where value is just two quotes "" right at start of line - for (i = 0; i < length - 1; i++) + for (i = 0; i < contentBytes.Length - 1; i++) { - char cur = content[i]; - char next = content[i + 1]; + byte cur = contentBytes[i]; + byte next = contentBytes[i + 1]; if (!quote) { @@ -640,7 +650,7 @@ public static void Lex(IntPtr instance, UIntPtr start_pos, IntPtr length_doc, in vtable.StartStyling(p_access, (IntPtr)(start + start_col)); vtable.SetStyleFor(p_access, (IntPtr)(length - start_col), (char)idx); // exception when csv AND separator character not colored AND file ends with separator so the very last value is empty - if ( (separatorChar != '\0') && (!sepcol) && (content[length-1] == separatorChar) ) + if ( (separatorChar != '\0') && (!sepcol) && (contentBytes[length-1] == separatorChar) ) { // style empty value between columns vtable.StartStyling(p_access, (IntPtr)(start + i)); @@ -943,4 +953,10 @@ public static IntPtr PropertyGet(IntPtr instance, IntPtr key) return Marshal.StringToHGlobalAnsi($"{value}\0"); } } + + internal static class OEMEncoding + { + [DllImport("Kernel32.dll")] + public static extern uint GetACP(); + } } -
@rdipardo said in Custom lexer and Unicode UTF-8 text file content:
you should be comparing
bytes, notcharsSee the fuller explanation in my PR comment: https://github.com/BdR76/CSVLint/pull/38
-
I fully agree with your explanation and initially assumed that ANSI and UNICODE document should be treated differently, but this was not the case, which confused me. That now a UNICODE OS setup poses this problem confuses me even more.
This is what an ansi and unicode look like on an ANSI setup OS
-
As I’ve said before, there are two completely distinct settings involved here:
-
the system’s (“ANSI”) code page, controlling how GUI text is rendered (and, also, the default encoding of string data by the .NET Framework; see below)
-
the text encoding of the document, controlling how content bytes are saved to disk
In summary, this is a .NET problem (
1.), not a Notepad++ problem.C:\>type cp.csscript System.Console.WriteLine("Default encoding of .NET strings: " + System.Text.Encoding.Default.EncodingName); // vim: ft=cs C:\>reg query HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage /v ACP HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage ACP REG_SZ 1252 C:\>csi cp.csscript Default encoding of .NET strings: Western European (Windows) C:\>reg add HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage /v ACP /t REG_SZ /d 65001 /f The operation completed successfully. C:\>csi cp.csscript Default encoding of .NET strings: Unicode (UTF-8) -
-
@rdipardo thanks for clarifying the Windows settings and the PR, it looks very useful. One question though, if I understand correctly the code in the PR creates a copy of the file content into a managed byte array. But the text data files can often be quite large, like 100MB, so then it would make a copy of 100MB right?
That would basically double the memory usage and add performance overhead every time the syntax highlighting is applied to a csv file.
Is there maybe a way to use the buffer_ptr directly, like in this stackoverflow answer? I know it’s “unsafe” code from the CLR perspective, as in using an unmanaged memory pointer, but it would probably perform better, so instead of:
string content = Marshal.PtrToStringAnsi(buffer_ptr, length);do something like
byte *byte_buffer = (byte *)buffer_ptr; for (var idx=0; idx < length;idx++) //etc.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login