Trying to get Notepad++ to use: ˓ and: ˒ as delimiter characters for syntax hi-liting.
-
i am trying to use the delimiters feature as documented here: https://ivan-radic.github.io/udl-documentation/delimiters/
Specifically, source code comments of a new programming language are bracketed with " ‹ " and " › ", but Notepad++ ignores these characters - seemingly for no other reason than that they are not standard ASCII characters!
if i use " < " and " > ", then the syntax hi-liting works, but i can’t use " ‹ " or " › " for open comment and close comment, which is really annoying.
any ideas?
~marc f. -
@Marc-Forward said in Trying to get Notepad++ to use: ˓ and: ˒ as delimiter characters for syntax hi-liting.:
that they are not standard ASCII characters!
This is a long-known limitation of the UDL.
I didn’t see it documented in the user manual; perhaps it should be. -
sigh. this limitation in the UDL certainly should have been documented, it needlessly wasted my time.
as limitations go, this one is severe and the tragedy is that it is so utterly arbitrary.
lack of orthogonal support for Unicode is a deal breaker for me, i was really hoping to use Notepad++, but now have to find another editor without this limitation (if none out there, will be forced to program my own editor). sigh. -
@Marc-Forward said in Trying to get Notepad++ to use: ˓ and: ˒ as delimiter characters for syntax hi-liting.:
lack of orthogonal support for Unicode is a deal breaker for me
You are probably gone, but if you do check for replies still, you could use EnhanceAnyLexer plugin to add regex-based foreground highlighting to any lexer, including any UDL. And that plugin does support Unicode in the regex.
-
@Marc-Forward said in Trying to get Notepad++ to use: ˓ and: ˒ as delimiter characters for syntax hi-liting.:
in the UDL certainly should have been documented, it needlessly wasted my time
Well, as the product you were using cost you nothing, a possible “waste of time” is a reasonable cost.
-
@PeterJones, thanks muchly, you have given me a lead i can pursue and explore.
but am not looking forward to rolling up my sleeves and getting my hands all greasy in the bowels of a regexing system.
-
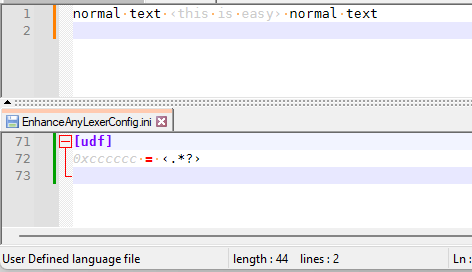
If your langauge is called MyCoolLanguage, then all you need in the EnhanceAnyLexer config is
[MyCoolLanguage] 0xcccccc = ‹.*?›I just set mine to the default “User Defined Language”, which needs
[udf]as the config-file header, but this shows it working:
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login