Finding matches
-
Hello guys
I have this question, kinda related to the previous question I asked.
I have the following exact file NOTE (not all the lines have this format “1234|1234|567891234|Mario|X” some lines are just numbers like in the example below )
1234|1234|567891234|Mario|X
5678|5678|123456789|Steve|X
5678|5678|454354355|Cristian|X
567891234
567891234
425345430If you check, the numbers highlighted match, I have many many numbers, more than 200 thousand how do I find all the numbers that match?
-
Unfortunately, the only way I know of to do that solely with the Search engine would be to do a fancy capture then \K then check for pattern group again after the \K, but the
(?s)\b(\d{9})\b.*?\K\1I came up with would only mark the first future-line occurrence of a number on a future line and it doesn’t mark the “source” line either
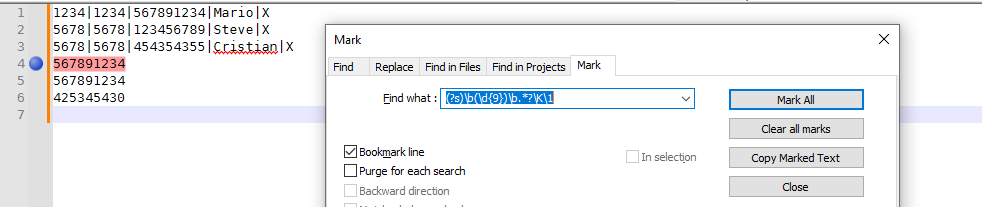
If you can make edits to the file (make a copy first), then I’d suggest the following steps
- Duplicate the 9-digit number to the beginning of the line, followed by a tab:
FIND =(?-s)^.*\|(\d{9})\|.*
REPLACE =$1\t$0
SEARCH MODE = Regular Expression
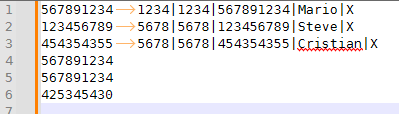
- Edit > Line Operations > Sort Lines as Integers Ascending
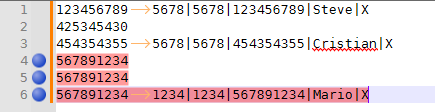
- Search > Mark >
FIND =(?-s)^(\d{9}).*(\R^\1.*)+,
Mark All
If order matters, then you’d have to number the lines first. The column-editor could help with that, but it’s hard to do for 200,000 lines. I know we’ve shown scripts before that use PythonScript or similar to number all the lines in the file – search the forum, or if you cannot find it, ask, and one of us might be able to find it.
But if you can figure out how to number the lines in the text, then translating the following into reality is left as an exercise for the reader:
A. you could number the lines
B. move all the 9digits to before the line numbers as step B (similar to original step 1)
C. sort as (same as step 2)
D. add a “marker” character to the END of any line where the line above or the line below has the same 9digit prefix
E. move the line numbers to the first position for easy sorting (probably by deleting the 9digit copied number)
F. Sort by the original line number
G. Clean out the original line number (and the duplicated 9digit number if that didn’t get cleaned in E like I would probably do)
H. All the lines that have your marker character at the end are the ones that are duplicated somewhere-—
Useful References
- Please Read Before Posting
- Template for Search/Replace Questions
- Formatting Forum Posts
- FAQ: Where to find regular expressions (regex) documentation
- Notepad++ Online User Manual: Searching/Regex
-—
Please note: This Community Forum is not a data transformation service; you should not expect to be able to always say “I have data like X and want it to look like Y” and have us do all the work for you. If you are new to the Forum, and new to regular expressions, we will often give help on the first one or two data-transformation questions, especially if they are well-asked and you show a willingness to learn; and we will point you to the documentation where you can learn how to do the data transformations for yourself in the future. But if you repeatedly ask us to do your work for you, you will find that the patience of usually-helpful Community members wears thin. The best way to learn regular expressions is by experimenting with them yourself, and getting a feel for how they work; having us spoon-feed you the answers without you putting in the effort doesn’t help you in the long term and is uninteresting and annoying for us.
- Duplicate the 9-digit number to the beginning of the line, followed by a tab:
-
I said,
The column-editor could help with that, but it’s hard to do for 200,000 lines.
Actually, if you create the macro described here, then you can use the Begin/End Column Select macro to easily create the column selection (Ctrl+Home, Begin/End Column Select, Ctrl+End, Home, Begin/End Column Select; if you wanted, you could do a TAB now, then redo that sequence to insert the line numbers before the TAB or spaces), at which point running the Edit > Column Editor and numbering from 1 with leading zeros will number 200000 lines without much difficulty.
(I tend to forget I had the easy macro version, because I tend to use my expanded PythonScript version as a custom button on my toolbar, which converts just about selection into a column selection, but didn’t want to have to explain the use of that script to you.)
-
@PeterJones said in Finding matches:
you’d have to number the lines first. I know we’ve shown scripts before that use PythonScript to number all the lines in the file – one of us might be able to find it.
Hmm, don’t remember that one (but it could be a bad memory problem), but as a new candidate example for the math-replacement-FAQ, how about:
# -*- coding: utf-8 -*- from Npp import editor counter = 0 def get_counter(m): global counter counter += 1 return '{:08} '.format(counter) editor.rereplace('^', get_counter)This is actually tightly based on an example in the PS docs, that I’ve only recently noticed.
-
@Alan-Kilborn said in Finding matches:
but as a new candidate example for the math-replacement-FAQ
We’ve gussied up the code above and did indeed add it to the FAQ.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login