Extract specific data from log files?
-
I have a log file that I need to extract specific data elements from.
Example text:[22-12-20 21:16:04.521] FROM LIVE <$011B4B50:FleetCard_10:1,51.75,1,1,200001,Fleet No,5411,34319,TARJETA,,51.75,,3,0,1> [22-12-20 21:16:04.553] auth accepted tag=9812120450668474 device=V2 [22-12-20 21:16:40.185] FROM LIVE <02:PAYDONE=0000022851> [22-12-20 21:17:20.677] TO LIVE <$011B4910:FleetCard_1:9812120450669349> [22-12-20 21:17:21.270] FROM LIVE <$011B4910:FleetCard_10:1,49.48,1,1,200001,Fleet No,5237,34320,TARJETA,,49.48,,2,0,1> [22-12-20 21:17:21.333] auth accepted tag=9812120450669349 device=V1 [22-12-20 21:18:44.345] FROM LIVE <02:PAYDONE=0000022852> [22-12-20 21:19:16.399] FROM LIVE <03:PAYDONE=0000022853> [22-12-20 21:20:18.292] TO LIVE <$011B5150:FleetCard_1:9812120450669482> [22-12-20 21:20:19.073] FROM LIVE <$011B5150:FleetCard_10:1,51.75,1,1,200001,Fleet No,2001,34321,TARJETA,,51.75,,3,0,1> [22-12-20 21:20:19.167] auth accepted tag=9812120450669482 device=V1 [22-12-20 21:21:53.536] TO LIVE <$011B4B50:FleetCard_1:9812120450668854> [22-12-20 21:21:54.286] FROM LIVE <$011B4B50:FleetCard_10:1,51.75,1,1,200001,Fleet No,5418,34322,TARJETA,,51.75,,3,0,1> [22-12-20 21:21:54.301] auth accepted tag=9812120450668854 device=V2 [22-12-20 21:25:11.284] FROM LIVE <02:PAYDONE=0000022854> [22-12-20 21:25:20.141] FROM LIVE <04:PAYDONE=0000022855>I want to extract like below
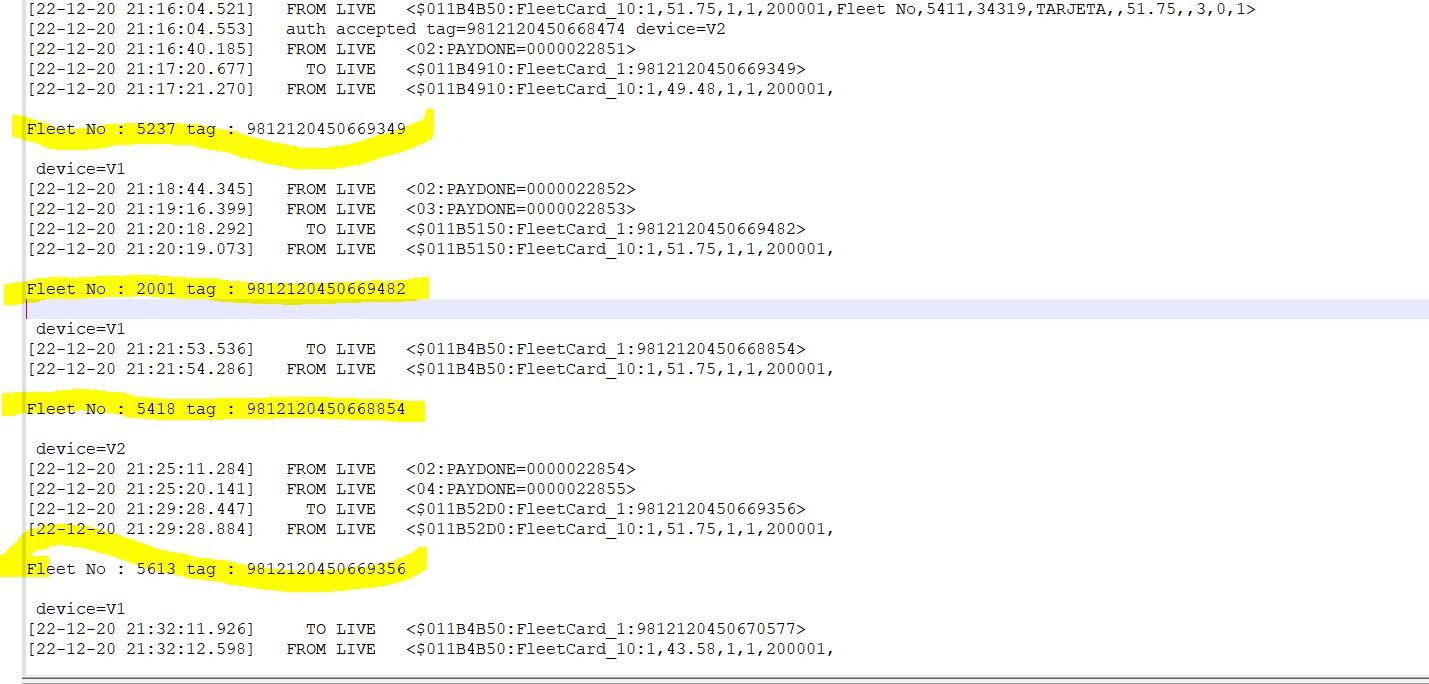
Fleet No : 5411 tag :9812120450668474 Fleet No: 5237 tag:9812120450669349 Fleet No : 2001 tag:9812120450669482This is my first question here and would like any support for above
-
Please don’t let those 16-digit numbers above be bank card numbers … and if they are, please let them be obscured and you didn’t copy / paste real numbers, non-anonymized, into this public forum.
Cheers.
-
Its just an internal reference ,
-
Phew.
The regex:
Fleet No\,(\d{4})\,.*?auth accepted tag=(\d{16})with the “Regular expression” radio button and “. matches newline” checked will find your data.
Using the replace dialogue on a copy of your file (this operation would be destructive), you could use:
\n\nFleet No : $1 tag : $2\n\n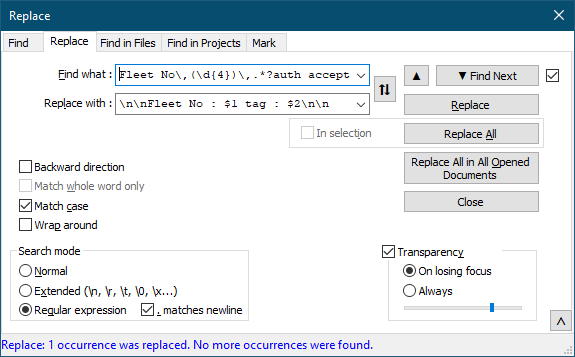
Cheers.
-
@Michael-Vincent said in Extract specific data from log files?:
\n\nFleet No : $1 tag : $2\n\n
just there, i want to delete everything except the selected file

-
@Zorba-Greek said in Extract specific data from log files?:
i want to delete everything except the selected file
An expert more versed than I may be able to help with a single stroke - for me, without a scripting solution, this is a multi-step process.
Now that you have the lines you want, use the Search => Mark menu item to bookmark the lines:
Find what:
Fleet No : \d{4} : \d{16}Check the “Bookmark line” checkbox:
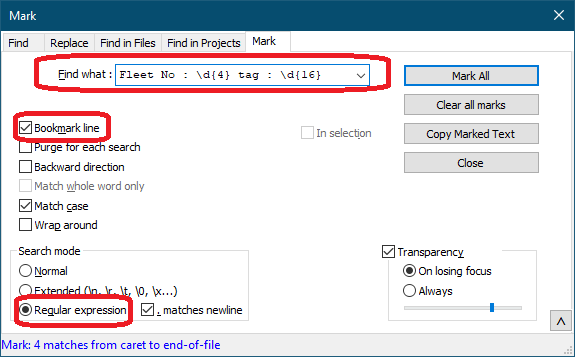
The right-click the bookmark margin and select “Copy Bookmarked Lines”, open a new tab and paste.
Cheers.
-
@Michael-Vincent said in Extract specific data from log files?:
An expert more versed than I may be able to help with a single stroke - for me, without a scripting solution, this is a multi-step process.
Don’t underestimate your abilities @Michael-Vincent. Your answer is perfectly acceptable, and I would have also likely given the same. Often when providing solutions to those who are yet to understand the complexities of regex, doing it in several “easy” steps is easier to understand.
The alternative would be to use alternation which is not so easy to understand for the uninitiated.
Terry
-
Thanks @Michael-Vincent , helpful …
-
@Terry-R ,
I agree with your analysis. One can’t understand the more complex, nor how to come to figure it out, if they don’t do the baby steps. I’m reminded myself, as I take on doing another UDL for one of our older versions of dBASE for those still using it and wanting to use it in NPP, that I’ve started using Mark in NPP as a test bed of my fledgling regex instead of going straight to Regex101.com, since it’s almost as interactive as their web page, but since they don’t have Boost as a test engine, it behooves me to do the work in NPP with the native regex, and I’ve found that Mark is a great way test my regex in stages. Plus, sometimes, the problem has to be divided in two to accomplish it…like trimming the ellipsis and page numbers from a list of Commands from a doucment, to replacing the spaces with the hex equivalent to make it work in NPP, etc…
Until I came to do this UDL for the language, I hadn’t even scratched the surface of NPP, and now that I have, I find myself in awe of the things it’s going to allow me to do…but only if I take it in baby steps. :)
-
Hello, @zorba-greek, @michael-vincent, @terry-r and All,
A one way solution would be to use the following regex S/R :
SEARCH
(?xs-i) ^ .+? Fleet \x20 No , ( \d+ ) , .+? tag= ( \d+) .+? $ | ^ .+REPLACE
(?1Fleet No \: $1 tag \: $2:)This regex :
-
Searches for two consecutive lines, without the ending line-break, containing the string Fleet No, with this exact case, in the first line and the string tag=, with this exact case, in the second one and replace these two lines with the string Fleet No :
$1tag :$2, where$1and$2are the numbers located after Fleet No and tag= -
When no more line contains the string Fleet No, it graps all the remaining text till the very end of the file and deletes it
So for instance, I will try to describe the process with this dummy example below :
FIRST alternative : (?xs-i) ^ .+? Fleet \x20 No , ( \d+ ) , .+? tag= ( \d+) .+? $ [22-12-20 21:18:44.345] FROM LIVE <02:PAYDONE=0000022852>CRLF <---------------------------------------------------------------- ^ .+? [22-12-20 21:19:16.399] FROM LIVE <03:PAYDONE=0000022853>CRLF ----------------------------------------------------------------- .+? [22-12-20 21:21:54.286] FROM LIVE <$011B4B50:FleetCard_10:1,51.75,1,1,200001,Fleet No,5418,34322,TARJETA,,51.75,,3,0,1>CRLF -------------------------------------------------------------------------------->Fleet No,<--><-------------------------------- .+? Fleet No, \d+ .+? Fleet No, $1 [22-12-20 21:21:54.301] auth accepted tag=9812120450668854 device=V2CRLF --------------------------------------->tag=<--------------><--------> ( line-break NOT included in the regex ) .+? tag= ( \d+ ) .+? $ tag= $2 SECOND alternative : ^ .+ [22-12-20 21:25:11.284] FROM LIVE <02:PAYDONE=0000022854>CRLF ----------------------------------------------------------------- ^ .+ [22-12-20 21:25:20.141] FROM LIVE <04:PAYDONE=0000022855>CRLF ----------------------------------------------------------------- ( End of file ) .+
Now, given the exact INPUT text, provided by @zorba-greek :
[22-12-20 21:16:04.521] FROM LIVE <$011B4B50:FleetCard_10:1,51.75,1,1,200001,Fleet No,5411,34319,TARJETA,,51.75,,3,0,1> [22-12-20 21:16:04.553] auth accepted tag=9812120450668474 device=V2 [22-12-20 21:16:40.185] FROM LIVE <02:PAYDONE=0000022851> [22-12-20 21:17:20.677] TO LIVE <$011B4910:FleetCard_1:9812120450669349> [22-12-20 21:17:21.270] FROM LIVE <$011B4910:FleetCard_10:1,49.48,1,1,200001,Fleet No,5237,34320,TARJETA,,49.48,,2,0,1> [22-12-20 21:17:21.333] auth accepted tag=9812120450669349 device=V1 [22-12-20 21:18:44.345] FROM LIVE <02:PAYDONE=0000022852> [22-12-20 21:19:16.399] FROM LIVE <03:PAYDONE=0000022853> [22-12-20 21:20:18.292] TO LIVE <$011B5150:FleetCard_1:9812120450669482> [22-12-20 21:20:19.073] FROM LIVE <$011B5150:FleetCard_10:1,51.75,1,1,200001,Fleet No,2001,34321,TARJETA,,51.75,,3,0,1> [22-12-20 21:20:19.167] auth accepted tag=9812120450669482 device=V1 [22-12-20 21:21:53.536] TO LIVE <$011B4B50:FleetCard_1:9812120450668854> [22-12-20 21:21:54.286] FROM LIVE <$011B4B50:FleetCard_10:1,51.75,1,1,200001,Fleet No,5418,34322,TARJETA,,51.75,,3,0,1> [22-12-20 21:21:54.301] auth accepted tag=9812120450668854 device=V2 [22-12-20 21:25:11.284] FROM LIVE <02:PAYDONE=0000022854> [22-12-20 21:25:20.141] FROM LIVE <04:PAYDONE=0000022855>We get the expected OUTPUT text :
Fleet No : 5411 tag : 9812120450668474 Fleet No : 5237 tag : 9812120450669349 Fleet No : 2001 tag : 9812120450669482 Fleet No : 5418 tag : 9812120450668854
Notes :
-
In the search regex, I use the free-spacing mode,
(?x), for an easy reading of the different parts of this regex -
You probably noticed that all ranges of text, in my regex, need to be non-greedy ranges ( Syntax =
.+?), as each range must not contain, itself, the strings Fleet No and tag= nor the final line break ! -
As this regex does not include the final line-break, it will keep them, as is, in the OUTPUT text
-
The replacement regex
(?1Fleet No \: $1 tag \: $2:)means :-
IF a Fleet number is found (
(?1...) it rewrites the string Fleet No : followed with the Fleet number ($1), the string tag = and the tag number$2, all separated withspacechars andcolonchars when needed -
ELSE it replaces with everything between the last
:character, after$2and the end of the conditional replacement)i.e. nothing so it deletes all the remaining text till the very end of current file !
-
-
Remark that the two first
:chars, in replacement, are literal characters and must be escaped, in order to be rewritten as is when the group1is present
Best Regards,
guy038
-
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login