UDL Number Suffix 2 not working when character also in Extras 2
-
Hi there!
I seem to have trouble to make a user defined language to detect binary numbers ending with the suffix 2 B. I’d like to make notepad++ see 01010101B as a number, but this only works when putting B into the suffix 1 field, which also causes the keyword DB to be recognized as a number, which I do not want. And since binary numbers aren’t supposed to use hexadecimal digits anyway, suffix 2 would be the field to put it in, but this simply does not work with using the letter B as a suffix while also using it in Extras 2. It does seem to work with other letters like X, but I can’t figure out how to make B work.
It does work when removing uppercase B and lowercase b from extras 2, but this would exclude hexadecimal numbers using the digit b from working.
I’ve had a look at the documentation for UDL, but there isn’t much information on this specific problem:
https://ivan-radic.github.io/udl-documentation/numbers/I’ve attached a few screenshots that should help to explain the problem, I am just utterly unable to figure out what causes this and haven’t found a fix anywhere.
Maybe someone here is able to help me, thanks a lot in advance.With B in Suffix 2:
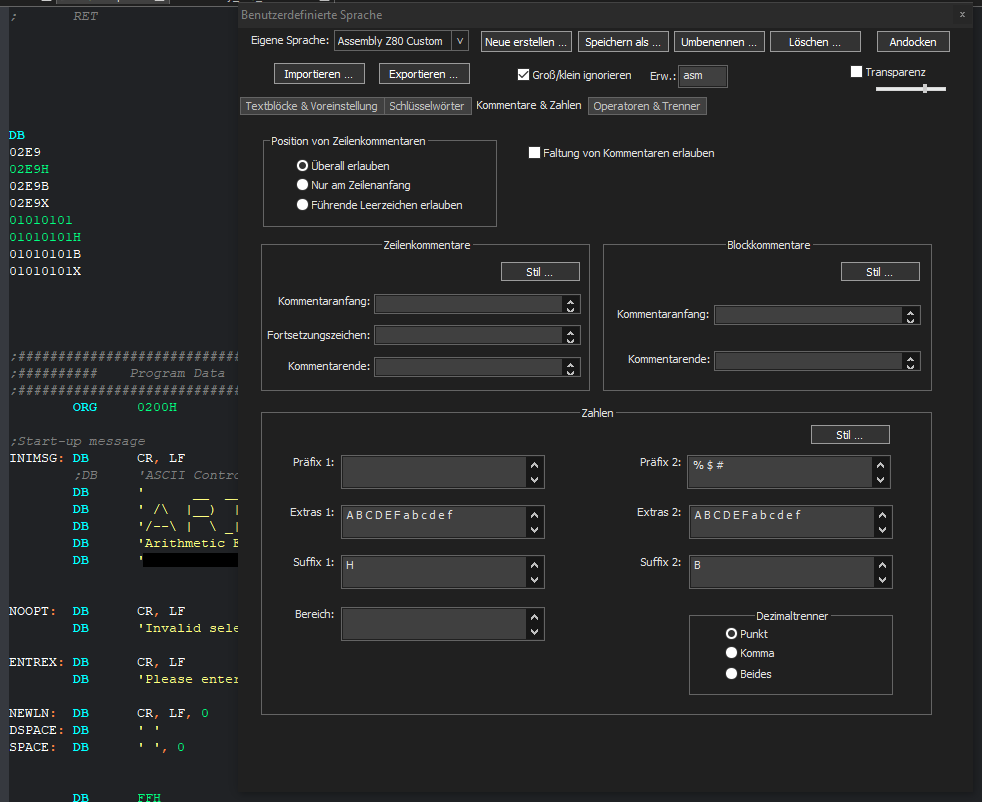
With B in Suffix 1:
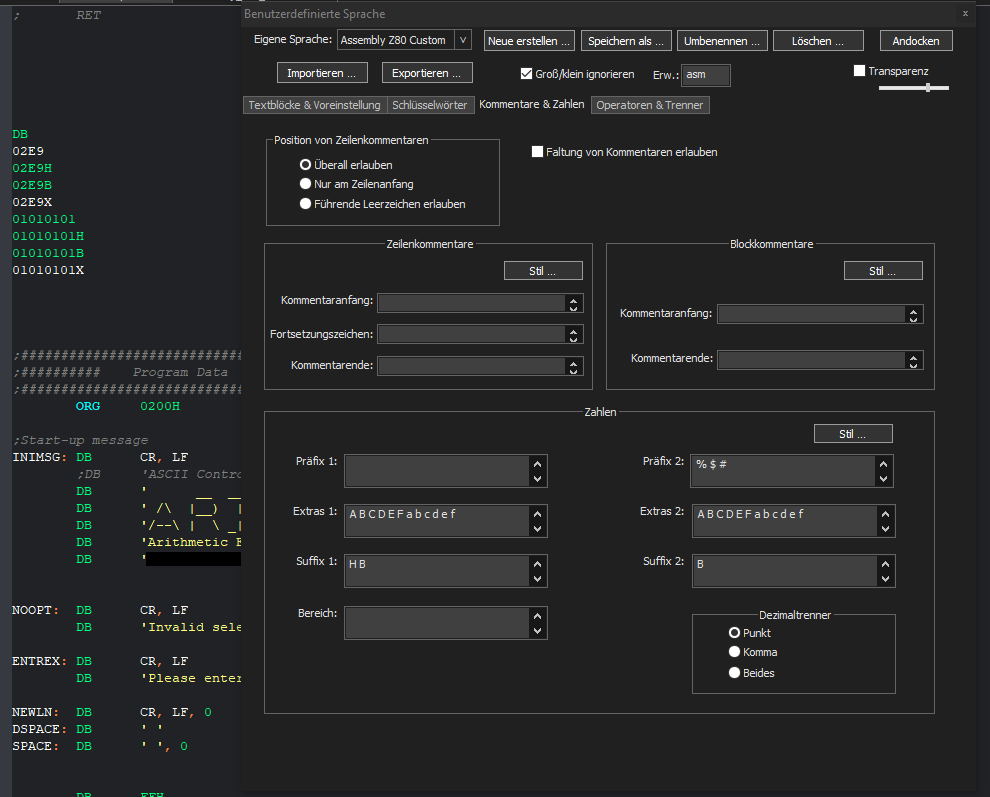
With X (just as an example) in Suffix 2:
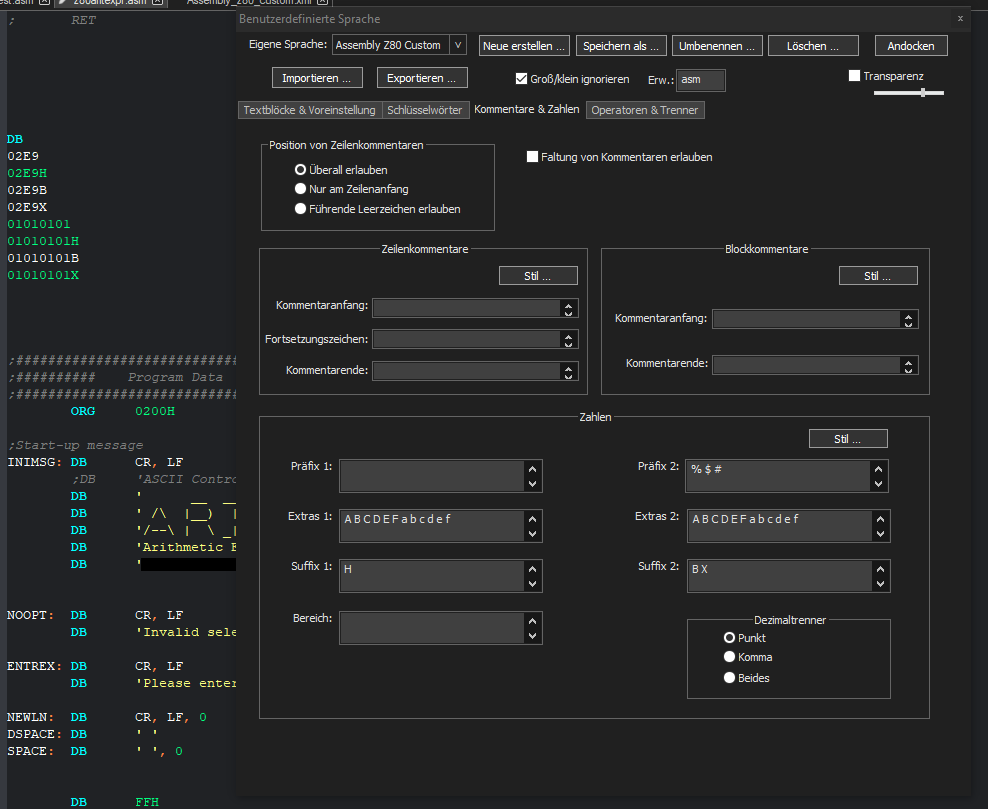
Without B and b in Extras 2:
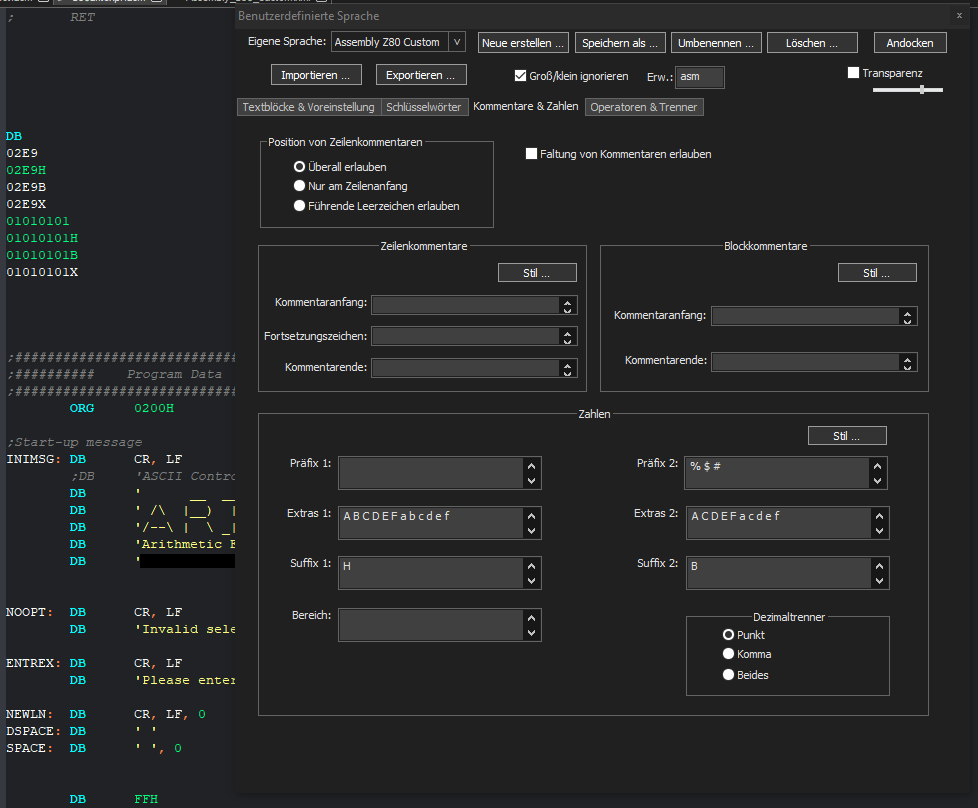
-
@Maggi-9295 said in UDL Number Suffix 2 not working when character also in Extras 2:
I am just utterly unable to figure out what causes this and haven’t found a fix anywhere
The problem is that when parsing, the UDL engine sees that B is in the Extras 2 list, and cannot recognize that you intended it to be a suffix in this instance. It’s one of the quirks / limitations of the UDL system. And unfortunately, the UDL system seems to be an aspect that the developer thinks is “good enough”, so bug reports and feature requests tend to go unanswered in the official issues tracker.
My recommendation: remove the
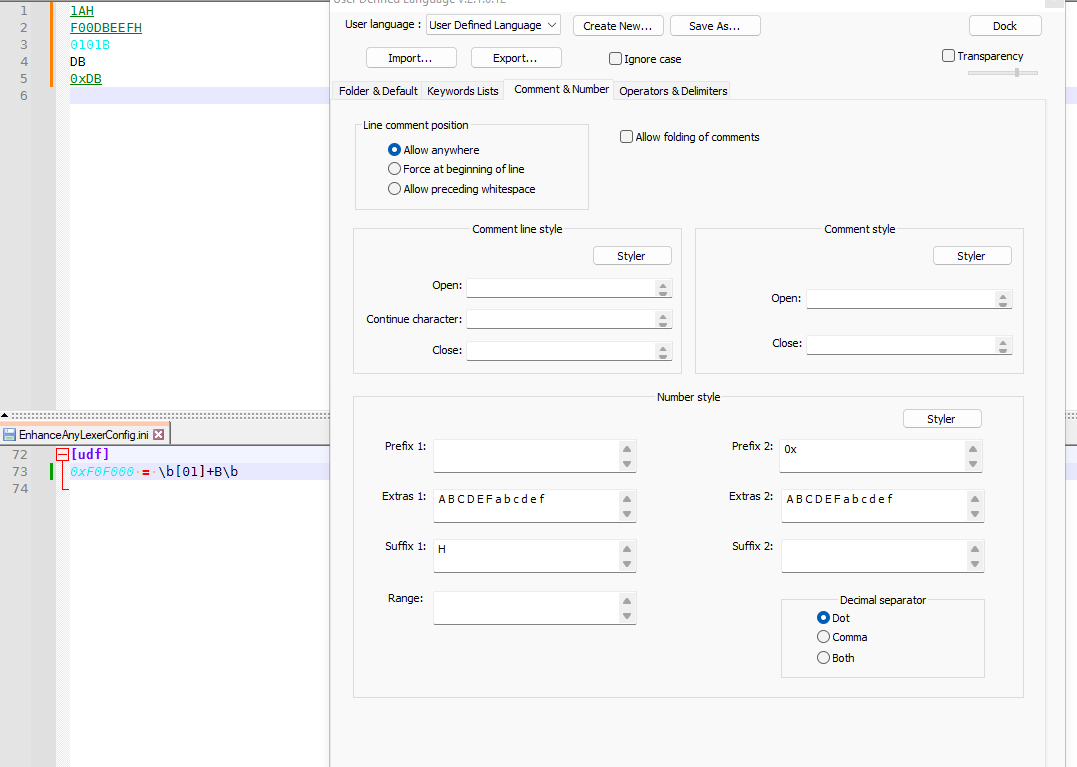
Bfrom Suffix 2. Then use the EnhanceAnyLexer plugin to define a regex that will match binary numbers only. For example,\b[01]+B\b. In my example screenshot, I am using the UDL called “User Defined”, which gets a name of[udf]in EnhanceAnyLexer, so my config looks like the following to make binary cyan.[udf] 0xF0F000 = \b[01]+B\b(you can pick any 0xBBGGRR hex as the foreground color, not just cyan; sorry, you cannot change the background using EnhanceAnyLexer.)
If you need
0101Bto match but not0101b, then the regex could be\b[01]+(?-i)B\b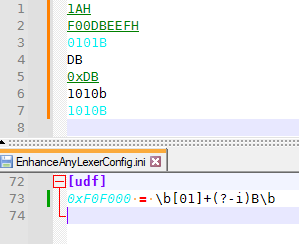
Note: When you use Plugins > EnhanceAnyLexer > Enhance current language (when the active file is in your current language), then it will automatically fill in the right
[name here]for the language. -
I’ve seen @PeterJones 's response to you, while I was trying to study the issue better, and since I recently discovered I read Ivan’s directions wrong, when doing my UDL, I figured you may have also, and I was trying things when I was ready to post and I saw @PeterJones response. I think there is a simpler way.
As far as I know, all ASM Hex representations is done with a
0xprefix, so if you want to keep Hex in and use Binary with a suffix, you need to define the numbers you’re going to use in thePrefix 1box and define the prefix1 0. Then when you put in theSuffix 2boxb Byour numbers will work properly. To keep using hex, you need to put in thePrefix 2box0x. This is because as Ivan notes, decimal digits are supported automatically…but that’s PLAIN digits. Not prefixed or suffixed…that’s why above I have prefixed the numbers0and1respectively, because they will be followed by a suffix ofborB. Below is a screenshot I made while I was messing with this. Good luck. Now I have to go put my normal UDL back to normal. :) Incidentally, if you’ll notice, thePrefix 2now also allowsbandBto work as well, before the0and1.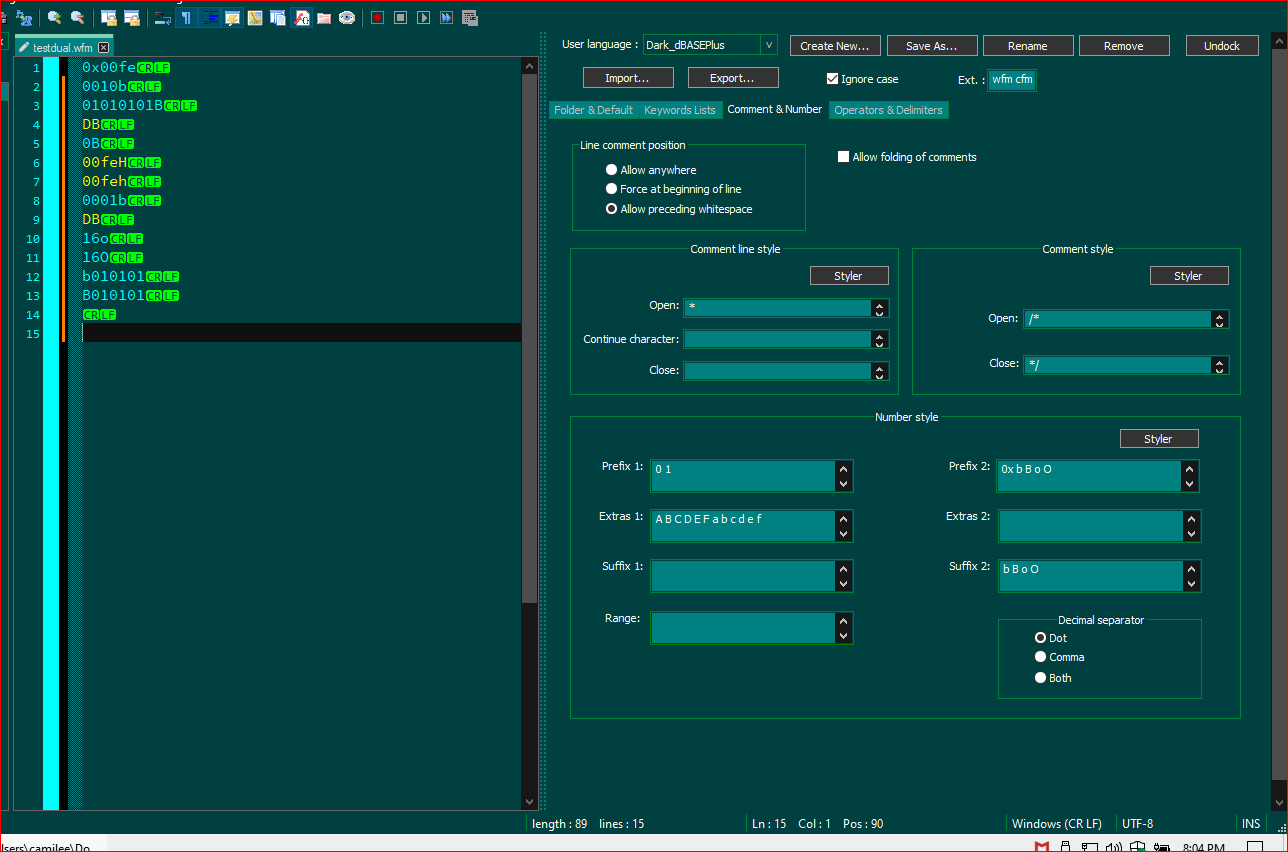
-
@Lycan-Thrope
In addition, the following screenshot, is about the only way I could get the three Hex representations options to work. If I tried any other options for Binary, I couldn’t get one or the other to work, so I guess it comes down to the option of choosing which one works for you and forego the other. For instance, in my UDL, all numbers are color coded, period, in the dBASE Plus IDE. Whether I use the binary or decimal, they color properly without needing representation differently. Hex numbers, on the other hand, need the0xprefix in the IDE, so as well, does my UDL have to do the same. So I won’t have a problem not being able to represent binary numbers as the language knows, based on context, if it’s binary0110in the code, or regular decimals, but hex ,needs to be ‘signed’ if you will. That’s why I made the assumption that you don’t need to worry about hex as it gets represented as other than binary…but after doing some research I see some assemblers indeed, don’t use the0xprefix, and prefer the suffixH. So, I guess if you want to use both, you will have to use @PeterJones suggestion.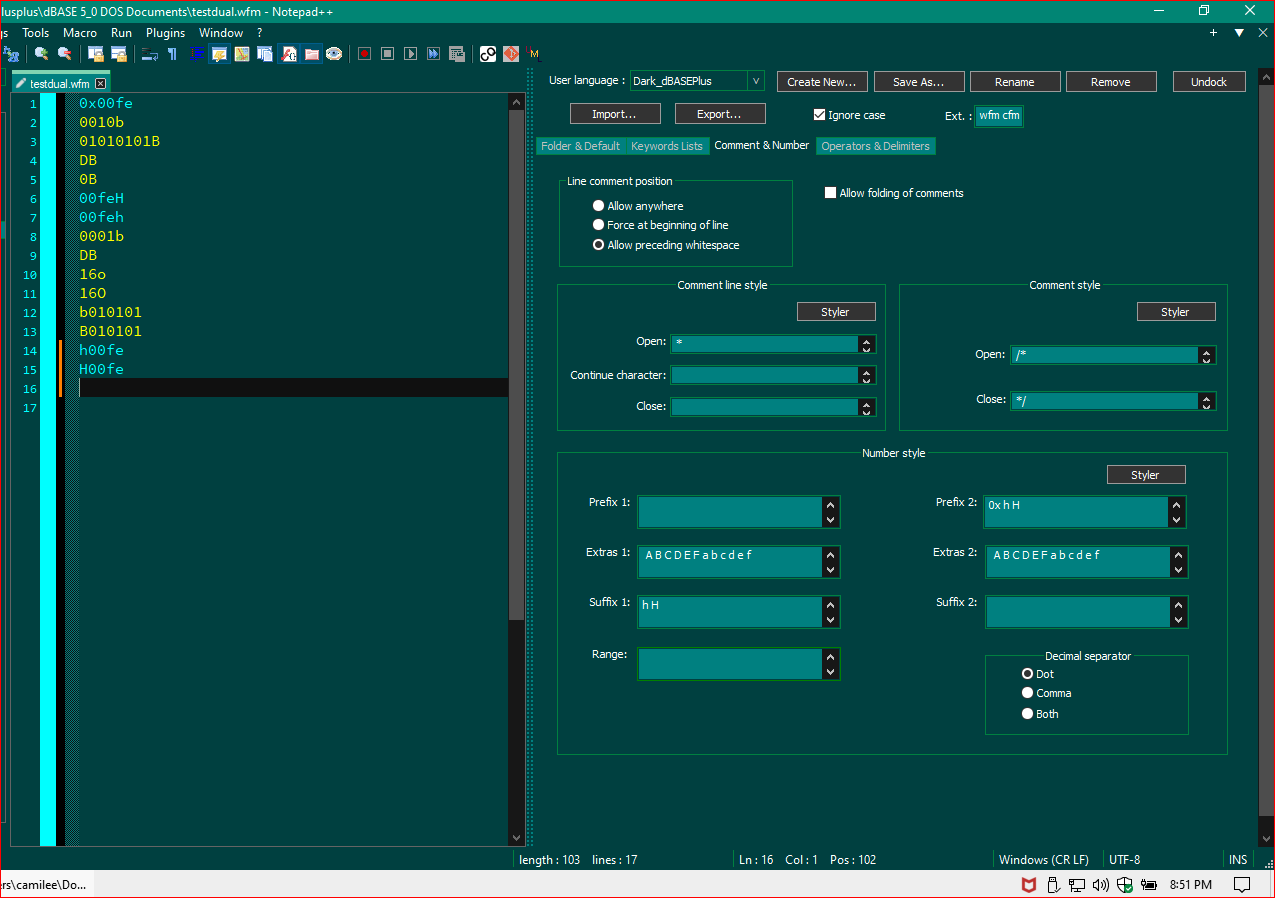
-
Truly, thank you both a lot for your effort to help!
@PeterJones said in UDL Number Suffix 2 not working when character also in Extras 2:
The problem is that when parsing, the UDL engine sees that B is in the Extras 2 list, and cannot recognize that you intended it to be a suffix in this instance. It’s one of the quirks / limitations of the UDL system. And unfortunately, the UDL system seems to be an aspect that the developer thinks is “good enough”, so bug reports and feature requests tend to go unanswered in the official issues tracker.
Yeah, I’ve heard that UDL “is already perfect the way it is”. Too bad.
@PeterJones said in UDL Number Suffix 2 not working when character also in Extras 2:
My recommendation: remove the B from Suffix 2. Then use the EnhanceAnyLexer plugin to define a regex that will match binary numbers only. For example, \b[01]+B\b. In my example screenshot, I am using the UDL called “User Defined”, which gets a name of [udf] in EnhanceAnyLexer, so my config looks like the following to make binary cyan.
[udf]
0xF0F000 = \b[01]+B\b(you can pick any 0xBBGGRR hex as the foreground color, not just cyan; sorry, you cannot change the background using EnhanceAnyLexer.)
If you need 0101B to match but not 0101b, then the regex could be \b[01]+(?-i)B\b
Note: When you use Plugins > EnhanceAnyLexer > Enhance current language (when the active file is in your current language), then it will automatically fill in the right [name here] for the language.
This is pretty much exactly what I need, thank you so so much!
EnhanceAnyLexer seems like a very powerful tool. Just out of curiousity, is there some kind of documentation on this?
I’ve also managed to extend it a little and move away from the notepad++ UDL number definitions to have all numbers work with EnhanceAnyLexer, but for some reason wasn’t able to make $nnn work:
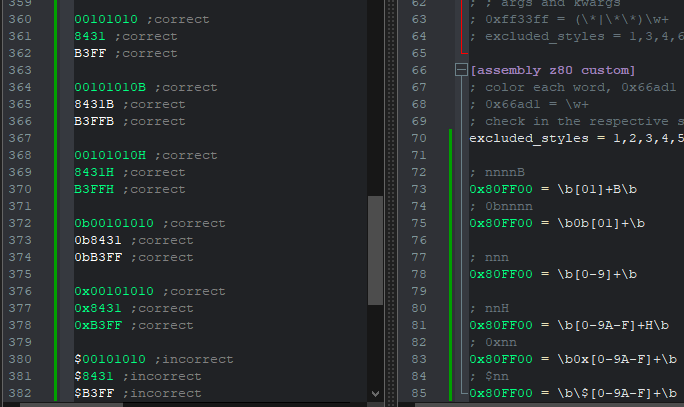
Another “problem” I found: numbers also get highlighted in the comments. Which is fine if it’s not possible to fix, I can very much live with this and am just curious how a fix would look like if it’s possible:
@Lycan-Thrope said in UDL Number Suffix 2 not working when character also in Extras 2:
As far as I know, all ASM Hex representations is done with a 0x prefix, so if you want to keep Hex in and use Binary with a suffix, you need to define the numbers you’re going to use in the Prefix 1 box and define the prefix 1 0. Then when you put in the Suffix 2 box b B your numbers will work properly. To keep using hex, you need to put in thePrefix 2 box 0x. This is because as Ivan notes, decimal digits are supported automatically…but that’s PLAIN digits. Not prefixed or suffixed…that’s why above I have prefixed the numbers 0 and 1 respectively, because they will be followed by a suffix of b or B. Below is a screenshot I made while I was messing with this. Good luck. Now I have to go put my normal UDL back to normal. :) Incidentally, if you’ll notice, the Prefix 2 now also allows b and B to work as well, before the 0 and 1.
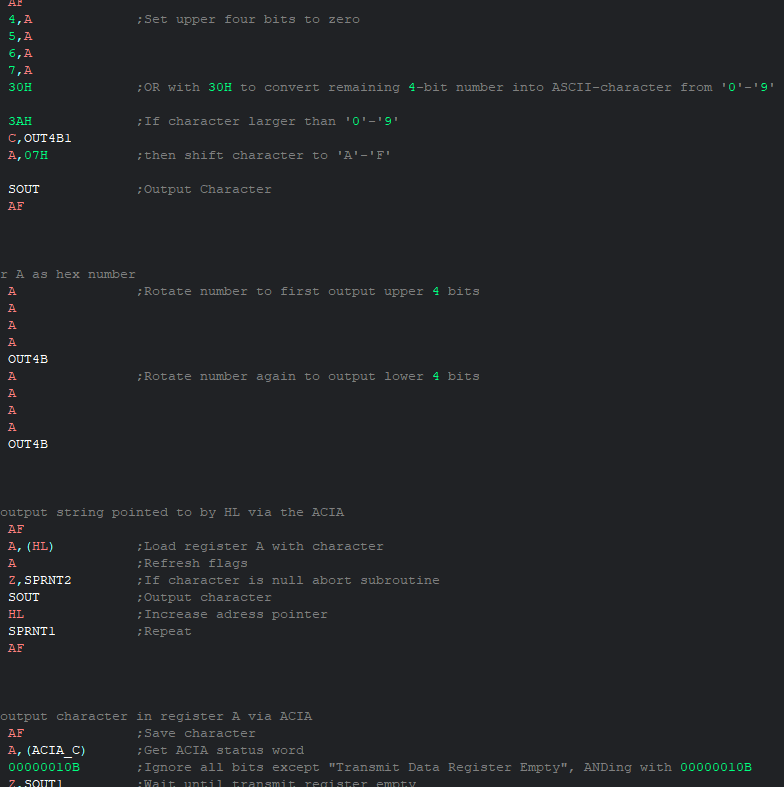
This would certainly be a possible workaround, but I prefer to use both nnH and nnnnB. Although I am thinking of just using 0x and 0b, since most people use this notation. Up until now I also was unsure which number representation the assembler I use recognizes, and it’s actually a lot more versatile than I though:

Thus I’ve also implemented 0x, 0b and (hopefully) $ into my language, since these notations are quite common as well. -
@Maggi-9295 said in UDL Number Suffix 2 not working when character also in Extras 2:
is there some kind of documentation on this
The
EnhanceAnyLexerConfig.iniis rather self-documenting, with all those builtin comments. The github page is here, but I think the ini has better documentation than the README.$nnn
try
0x80FF00 = (?<=\b|^)\$[0-9A-F]+\bI found: numbers also get highlighted in the comments. Which is fine if it’s not possible to fix,
Possible, but harder. You would have to come up with a regex that would exclude any of the “as number” markers that have a ; anywhere on the line before.
^[^;]*?\Kfollowed by the rest of the regex might work. You would have to play to see what works with you. From what I remember, the EnhanceAnyLexer plugin uses the same regex engine as Notepad++ does, so the Useful References below may help you find additional syntaxes. (But you are doing pretty well so far)-—
Useful References
- Notepad++ Online User Manual: Searching/Regex
- FAQ: Where to find other regular expressions (regex) documentation
.
-
@Maggi-9295 said in UDL Number Suffix 2 not working when character also in Extras 2:
This would certainly be a possible workaround, but I prefer to use both nnH and nnnnB. Although I am thinking of just using 0x and 0b, since most people use this notation. Up until now I also was unsure which number representation the assembler I use recognizes, and it’s actually a lot more versatile than I though:
Thus I’ve also implemented 0x, 0b and (hopefully) $ into my language, since these notations are quite common as well.
Yes, I saw that when I did a search on Z80 Assembly, and figured if worse came to worse, you could use the
%Character if need be, BUT…that gets used a lot for Modulo, I think…so was going to discount that…and I did read that yours seems to prefer H, but as I mentioned, that causes a problem for using Binary then. Figured that binary is more concerned with jumps and addresses in binary and the hex/binary screen I showed you, if you’re able to use0xwould be the best situation all around…that’s why I was playing around trying to find out WHY theb Byou were using wasn’t working…when I had a moment of clarity and punched in the digits in that first box and watched as the text started highlighting itself. :)I have to agree though, the binary, being
0and1representations, shouldn’t need to be specially entered since the0xin the second box, and the alphabetic upper and lower case in the 3rd box gets recognized with digits without having to enter them in the 1st box…is kind of inconsistent. That is about the only thing I would think needs to be fixed if someone was to start looking into fixing it…unless…for some reason the parsing can’t be done that way or some such. I need to find out where in the codebase the UDL stuff is…unless it’s really in the Scintilla/Lexilla stuff? Sigh…wishing I had more time and was younger again and could burn the candle from all 4 ends. :) -
@PeterJones said in UDL Number Suffix 2 not working when character also in Extras 2:
The EnhanceAnyLexerConfig.ini is rather self-documenting, with all those builtin comments. The github page is here, but I think the ini has better documentation than the README.
Yeah, turns out the Regex documentation is pretty much what I am looking for, it’s really quite comprehensive and takes some time to get used to in my opinion :)
https://npp-user-manual.org/docs/searching/@PeterJones said in UDL Number Suffix 2 not working when character also in Extras 2:
try
0x80FF00 = (?<=\b|^)$[0-9A-F]+\bThis seems to partially work, causes some other problems however, a number is only recognized if at the start of the line or within a word:
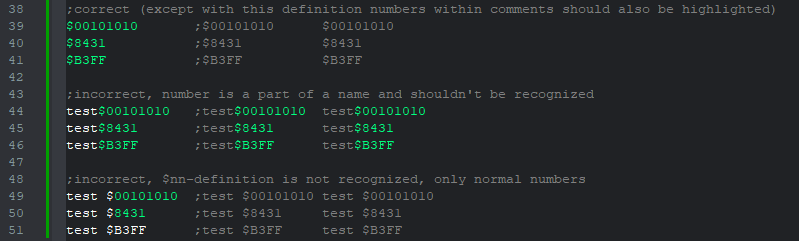
I am still slightly confused by what the following statement says:
(?<=\b|^)According to the documentation “?<=” stands for “true if the lookbehind expression matches”, but I can’t quite figure out what “lookbehind” means. The expression within the text after either a new word or new line (“\b|^”)?
Why doesn’t just \b work? What makes “$” different from “0x” or “0b”?
My guess would be that a “$” character isn’t considered a character that’s a part of a word, but I don’t know I’d change that…@PeterJones said in UDL Number Suffix 2 not working when character also in Extras 2:
Possible, but harder. You would have to come up with a regex that would exclude any of the “as number” markers that have a ; anywhere on the line before. ^[^;]*?\K followed by the rest of the regex might work. You would have to play to see what works with you. From what I remember, the EnhanceAnyLexer plugin uses the same regex engine as Notepad++ does, so the Useful References below may help you find additional syntaxes. (But you are doing pretty well so far)
Thanks! This does work with the prefixes “0x”, “0b” and suffixes “H” and “B”, not with the prefix “$” however, but I guess that’s because of the other statement/problem. But I’ll try to get it to recognize correct before trying to exclude it from being recognized in the comments, so that’s a problem for later, would be stupid to tackle both problems at once.
I also managed to understand this expression, once you know what is what it’s not that hard. “\K” is quite useful in this case!I do have another challenge however, what if I only want numbers within comments to be highlighted? I think it would be neat to make them a slightly brighter gray than the comments itself. (Just playing around a little at this point :P)
I’d have to start looking at the start of a line until I find (any number of) “;”, and only highlight numbers following the “;”.
Start searching at a new line with “^”, skip every character that’s not a semicolon (with “[^;]*?”) until at least one semicolon is being found (with “;+?”), again skip all other characters (with “.*?”) until a number is being found and highlight it:0xC0C0C0 = ^[^;]*?;+?.*?\K\b[0-9A-F]+H\bHowever, this only hightlights the first number after the “;”. How can I highlight every number, not just the first?

I guess I could also just highlight every number in gray first and “overwrite” the numbers in front of a comment in a different color, but that’d be quite lazy XD@Lycan-Thrope said in UDL Number Suffix 2 not working when character also in Extras 2:
Yes, I saw that when I did a search on Z80 Assembly, and figured if worse came to worse, you could use the % Character if need be, BUT…that gets used a lot for Modulo, I think…so was going to discount that…
Another problem with using % or & is, that it is being recognized as a operator, would be highlighted in a different color and thus a number wouldn’t be recognized as well :/
I guess you could use EnhanceAnyLexer to iron these issues out as well, but that’s a thing for later on :P@Lycan-Thrope said in UDL Number Suffix 2 not working when character also in Extras 2:
I have to agree though, the binary, being 0 and 1 representations, shouldn’t need to be specially entered since the 0x in the second box, and the alphabetic upper and lower case in the 3rd box gets recognized with digits without having to enter them in the 1st box…is kind of inconsistent. That is about the only thing I would think needs to be fixed if someone was to start looking into fixing it…unless…for some reason the parsing can’t be done that way or some such. I need to find out where in the codebase the UDL stuff is…unless it’s really in the Scintilla/Lexilla stuff? Sigh…wishing I had more time and was younger again and could burn the candle from all 4 ends. :)
Well, here we are :P
Sadly it sounds like not much we can change (unless we’d try to fix this ourselves, but that’d be FAR beyond my knowledgeand motivation and energyto do)
And I’m quite happy with EnhanceAnyLexer at the moment as well, so I’ll just stick to this :P -
@Maggi-9295 said in UDL Number Suffix 2 not working when character also in Extras 2:
Just out of curiousity, is there some kind of documentation on this?
I like the idea of having the configuration file and the help system in one place, and I hope the explanation is understandable. If this is not the case, let me know how I can improve it.
-
@Ekopalypse said in UDL Number Suffix 2 not working when character also in Extras 2:
@Maggi-9295 said in UDL Number Suffix 2 not working when character also in Extras 2:
Just out of curiousity, is there some kind of documentation on this?
I like the idea of having the configuration file and the help system in one place, and I hope the explanation is understandable. If this is not the case, let me know how I can improve it.
I think it’s alright, no worries! I just wasn’t aware it uses the Notepad++ regex syntax and was searching which syntax it uses in the first place, but that’s just me not reading properly :P
The Notepad++ documentation on searching is already more than comprehensive enough, so I think that should cover pretty much everything (once you got used to it, that is :P)
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login