Is there any way to convert code points to unicode
-
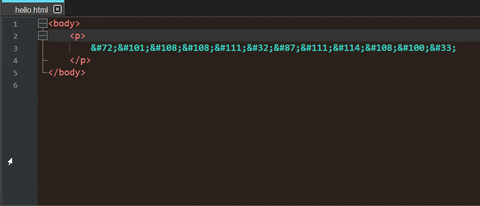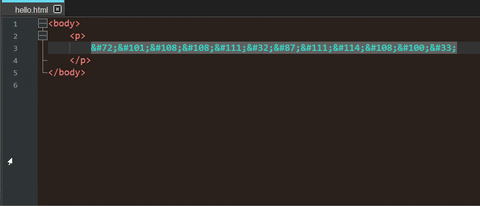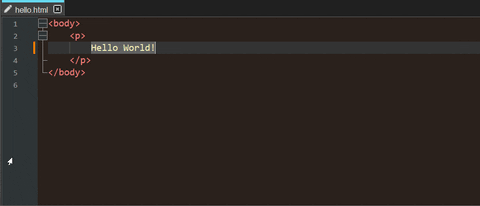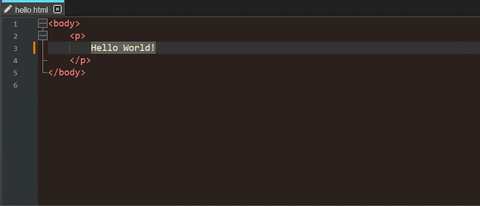
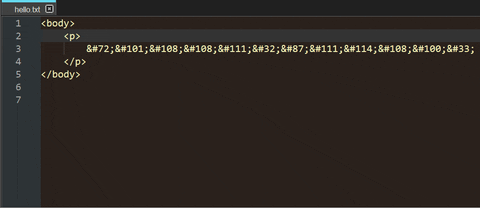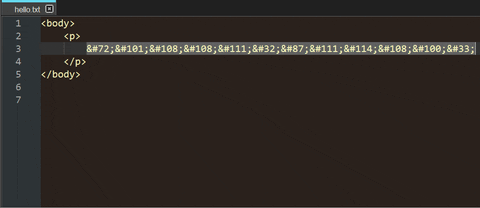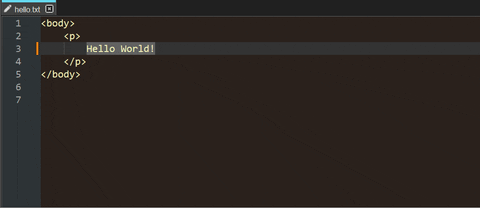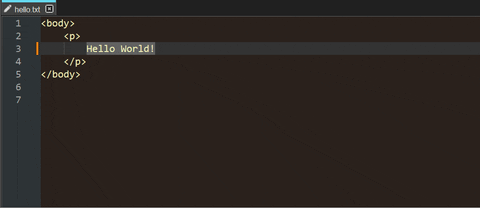
You could create an HTML file that includes your code points as HTML entity numbers (i.e. you have to replace
\by&#at first). For example:<body> <p> Hello World! </p> </body>Opening the resulting file in a web browser makes it possible to copy the plain text.
-
i want to convert it to “Hello World!”
As suggested above, you can encode the text as numeric entities, then convert them right in Notepad++ with the HTML Tag plugin (*1):
Your file doesn’t even have to be a recognized markup language (*2):
(*1) In the GIFs I call the “Select tag contents only” command, then "Decode selected (HTML) entities.
(*2) Exception: most named entities (e.g.
©) are unrecognized by the XML 1.0 specification; the plugin falls back to numeric entities in those cases. -
@rdipardo Huge thanks that’s what i need
-
@User-000 If you don’t mind using the PythonScript plugin, then here is a simple script. You select with the mouse the string
72\101\...\33and run the script below. It will insert the extended ASCII characters just before the selection.#72\101\108\108\111\32\87\155\114\108\100\33 import struct # Python 2 from Npp import * s = editor.getSelText().split('\\') ins_pos = editor.getSelectionStart() out = '' for char in s: out+=struct.pack('B', int(char)).decode('cp850') editor.insertText(ins_pos, out )The test string in the comment will become
#Hello Wørld!72\101\108\108\111\32\87\155\114\108\100\33after selecting it and running this script. -
Hello, @user-000, @alan-kilborn, @dinkumoil, @rdipardo, @paul-wormer and All,
From this python 3 file, I was able to extract the parts regarding the
Text to AsciiandAscii to Textconversions and adapt it as aPython 2.7N++ script, Pheeew !However, my script below is certainly very weak as :
-
Results need to be read in the Python
consoleonly -
Results with accentuated characters are weird, although correct ?
So, I really need some insights from
Python’s gurus, in our forum, to improve a bit that script !# Converts a String to ASCII Code Integers def asc(text): return ''.join([str(ord(i)).zfill(3) for i in text]) # Converts ASCII Code Integers to a String def txt(ascii): ascii = str(ascii) if len(ascii) % 3 != 0: ascii = ascii.zfill(len(ascii) + (3 - (len(ascii) % 3))) return ''.join(chr(int(ascii[i - 2] + ascii[i - 1] + ascii[i])) for i in range(len(ascii) - 1, 0, -3))[::-1] # Main Function def main(): while True: option = notepad.prompt('Enter T for Ascii to Text conversion\nEnter A for Text to Ascii conversion\n','','') if option not in ['T', 'A', '']: continue if option == '': break if option == 'T': answer = notepad.prompt('Enter ASCII values of 3 DECIMAL digits : ','','') print(txt(answer)) if option == 'A': answer = notepad.prompt('Enter an ASCII TEXT string: ','','') print(asc(answer)) main()Best Regards,
guy038
P.S. :
- I saw this article, on the Net, related to
Powershell:
In
PowerShell 6and later, the-replaceoperator also accepts a script block that performs the replacement. The script block runs once for every match.<String> -replace <regular-expression>, {<Script-block>}Within the script block, use the
$_automatic variable to access the input text being replaced and other useful information. This variable’s class type is System.Text.RegularExpressions.Match.The following example replaces each sequence of three digits with the equivalent character. The script block runs for each set of three digits that needs to be replaced.
Input :
"072101108108111" -replace "\d{3}", {return [char][int]$_.Value}Output :
HelloTo know your PS version, open the PS console, type
$PSVersionTableand looks for the PSVersion value
- I also found these two
JavaScriptprograms, onStack Overflowwhich could be of some interest :
var StringTools = { stringToNumbersArray: function(data){ return data.split('').map(function(c){return c.charCodeAt(0);}); }, numbersArrayToString: function(arr){ return arr.map(function(n){return String.fromCharCode(n)}).join(''); } } StringTools.stringToNumbersArray("Hello"); // => [72, 101, 108, 108, 111] StringTools.numbersArrayToString([72, 101, 108, 108, 111]) // => "Hello"And :
function convertToNumber(str){ var number = ""; for (var i=0; i<str.length; i++){ charCode = ('000' + str[i].charCodeAt(0)).substr(-3); number += charCode; } return number; } alert(convertToNumber("SO does my homework")); //console.log is better function convertToString(numbers){ origString = ""; numbers = numbers.match(/.{3}/g); for(var i=0; i < numbers.length; i++){ origString += String.fromCharCode(numbers[i]); } return origString; } alert(convertToString("083079032100111101115032109121032104111109101119111114107")); //console.log is better -
-
@guy038 said in Is there any way to convert code points to unicode:
Results with accentuated characters are weird, although correct ?
The Python function call
chr(n)returns the character with Unicode code pointn. The block of Unicode code points 0x80-0x9F (128-159) is assigned to control characters, not to (accented) letters. In the block 0x80-0xFF (128-255) Unicode coincides with ISO/IEC 8859-1 (aka Latin-1).I introduced, for the fun of it, the Danish character
øin theHello wørld!example above. In the CP850 encoding (aka extended ASCII) used, the characterøhas code point 155. Hence, this code point correspond in Latin-1 to a (non-printable) control character.So, when you use the function
chryou have to make sure that you stick to Latin-1. I don’t know if this explains the weirdness of your accented characters, but in any case different encodings can cause confusion and are a point of concern. -
Replacing cp850 with
mbcs, the configured ANSI code page of the current Windows setup is used. -
I’d replace
struct.pack('B', int(char))withstruct.pack('h', int(char))and add a call toout = out.replace('\x00', '')at the end.'h'allows you to handle any number less than 65536, which conveniently includes the entire Basic Multilingual Plane and thus allows you to use'utf-16'as the encoding.Putting it all together:
import re import struct from Npp import * ins_pos = editor.getSelectionStart() selected_text = editor.getSelText() nums = [int(n) for n in re.findall('\d+', selected_text)] decoded = [struct.pack('h', n).decode('cp850') for n in nums] replacement = ''.join(decoded).replace('\x00', '') editor.insertText(ins_pos, replacement) -
@Mark-Olson Why do you deem it necessary to remove
\x00? Where would it come from? -
@Paul-Wormer I believe I have the answer to my own question: in the 2 byte packing, indicated by
pack('h', n), 2 trailing zeroes are added for numbers below 256. They show up as\x00, also afterdecode('cp850'). IMHO, it would probably have been clearer (also for future use) if Mark Olson had gone the 2-byte way consistently and had writtendecode('utf_16')in his Python snippet instead ofdecode('cp850'). There also would have been no need to remove\x00then. The OP asked about 7-bit ASCII anyway and for this all codings are equal. -
I would even go so far as to say that the given example is good for seeing where the problem lies with encodings, since it fits several, it could be ascii, cp1252, utf8… be.
-
@dinkumoil said:
You could create an HTML file that includes your code points as HTML entity numbers
…and…
@rdipardo said:
you can encode the text as numeric entities, then convert them right in Notepad++ with the HTML Tag plugin
…and that’s all fine, but the OP ( @User-000 ) had a title on this posting of “Is there any way to convert code points to unicode”, so I found it curious that no example was provided that actually had some fun and uses any “fancy” unicode characters. (Of course, OP didn’t do this in his sample data, either…).
I didn’t try with the HTML Tag plugin, but I did try the “HTML file” approach with some “fancy” character data:
<body> <p> Hello World!▼💙 </p> </body>and indeed it worked just fine to show the fancy-ness for characters U+25BC and U+1F499; here shown in Chrome:
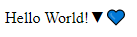
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login