Need guidance - Autocompletion plugin
-
@Akash-R said in Need guidance - Autocompletion plugin:
Adding entries in SQL.xml will good but wont be good enough
Why not?
I mean, 500*100=50000 is a huge number of autocomplete terms, but if the database structure is constant (no new tables, no new fields), you would just have to go through the effort of generating the SQL.xml once, then it would always be available.
I just took a fresh SQL.xml, and added
<KeyWord name="fah.asset_id" /> <KeyWord name="fav.asset_id" /> <KeyWord name="fav.asset_number" /> <KeyWord name="fb.asset_id" /> <KeyWord name="fb.cost" />(in the correct case-ignoring alphabetical order), then restarted Notepad++ and started a new SQL file:
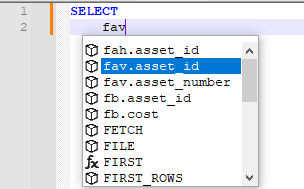
Or, if that list is too long for you, use Settings > Preferences > Auto-Completion > Make auto-completion list brief, which once you’ve typed
favit will narrow it just to tokens that start withfav: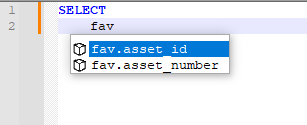
I again admit that won’t be sufficient if your database structure varies over time, because it couldn’t get live updates from your db. And I’ve never tried adding thousands of keywords, so at some point, it might over-extend some maximum array/memory size. But it might be worth a try for you – even if it’s just picking some of the most-frequently used tables and their most frequently used fields, so that you’re down in the few hundred to maybe 1000 added entries, instead of 50k entries.
@Ekopalypse , as someone who knows more about LSP than I do, do you happen to know if there are database LSP servers that would provide the necessary backend, so that the OP could use your LSP client (or that other one that someone else was working on back when you were talking more about LSP) for N++ (even if it’s not ready for prime time)?
-
I’d just like to chime in that this is more or less exactly what an object-relational mapper (ORM) is for.
You don’t need a special IDE for SQL databases when you have perfectly good IDEs with autocompletion and the works for programming languages, and you can just define a class that represents the table with attributes for its columns. Then the IDE’s autocompletion can take over from there.
But if you’re not using an ORM, the easiest way to achieve what PeterJones is describing would be to build a simple SQL DDL parser. You feed the parser your table definitions, the parser extracts column names for each table and generates an autocompletion XML file for that table. Even better, you could look for foreign key definitions to auto-suggest potential JOIN partners for a column.
-
@PeterJones said in Need guidance - Autocompletion plugin:
Why not?
For one thing, in the example:
SELECT fav.asset_id, fav.asset_number, fb.cost, fah.asset_type FROM fa_additions_v fav, fa_book fb, fa_asset_history fah WHERE fav.asset_id = fb.asset_id AND fav.asset_id = fah.asset_id AND fb.ineffective_date IS NULLfav, fb and fah are names local to the SELECT command. Someone else could write:
SELECT additions.asset_id, additions.asset_number, book.cost, history.asset_type FROM fa_additions_v additions, fa_book book, fa_asset_history history WHERE additions.asset_id = book.asset_id AND additions.asset_id = history.asset_id AND book.ineffective_date IS NULLand it would mean the same thing and should be auto-completed the same way. You can’t do that without doing a fairly deep parse of the meaning of SQL statements.
(Oh, and yes, I was the one who suggested autocomplete in the first place. I was wrong.)
-
@Akash-R,
if I understand your functional requirements, we’re taking about fetching live data from a RDBMS on a local or remote network. Assuming the plugin will be in C#, you would need, at minimum:-
a database driver library for the particular RDBMS. This will have to be compatible with .NET Framework 4.0, the same target as the .NET plugin template. A proof-of-concept could start with a hard-coded connection to something like a LocalDB instance or even a SQLite file, using a modern library like EF Core. “Back-porting” to .NET Framework could be a roadblock, however . . .
-
a socket API for TCP communication with the RDBMS, like the built-in System.Net.Sockets. If the RDBMS will always be on the same PC as Notepad++, you could maybe get by with pipes instead.
Once all the infrastructure is in place, the plugin is just a message loop that sends SQL queries on keyboard events (like
SCN_CHARADDED, as mentioned earlier), then populates the autocomplete list with whatever the server sends back. -
-
I said:
“Back-porting” to .NET Framework could be a roadblock, however . . .
Well, the CsvQuery plugin claims it can “use SQL Server as [a] backend”, so nothing’s impossible.
-
@Coises said in Need guidance - Autocompletion plugin:
and it would mean the same thing and should be auto-completed the same way.
Interesting. I am not an SQL user, so that didn’t jump out at me.
But that says, if I start with my cursor at the
|SELECT fav|You wouldn’t be able to know what I was asking for, and so would have no way to auto-complete the
fav. But if I had the following, and moved my cursor to the|,SELECT fav| FROM fa_additions_v fav, fa_book fb, fa_asset_history fahthen you would expect it to be able to auto-complete on the
favnow? Even though there isn’t a full, syntatically-valid SELECT statement yet?And is that really the order people are writing their SELECT statements?
I think that would be a really difficult problem to solve – being able to figure out when it should and shouldn’t try to contact the database, based on partial SELECT statements or similar. shudder Glad it’s not me who is trying to implement such a beast.
-
@rdipardo
I use .NET Framework 4.8 in my plugins. So the infrastructure can be a bit more modern than what’s in 4.0. The main issue from my perspective is not compatibility with Notepad++, it’s using a version of .NET Framework that’s preinstalled on most Windows 10 PC’s.Also, it doesn’t seem like you’d need to contact the database that often. Since this is an autocomplete plugin, the autocomplete list will just reflect the database schema, which presumably doesn’t change that often. Since the autocomplete lists can be pre-fetched, the person making the plugin wouldn’t need to worry about heavily optimizing for speed in their database connection.
-
No, I have no experience with sql language servers. I found this one, but it’s archived.
Just a small example of what can be done. A “real” service would of course have to address all the problems already mentioned.
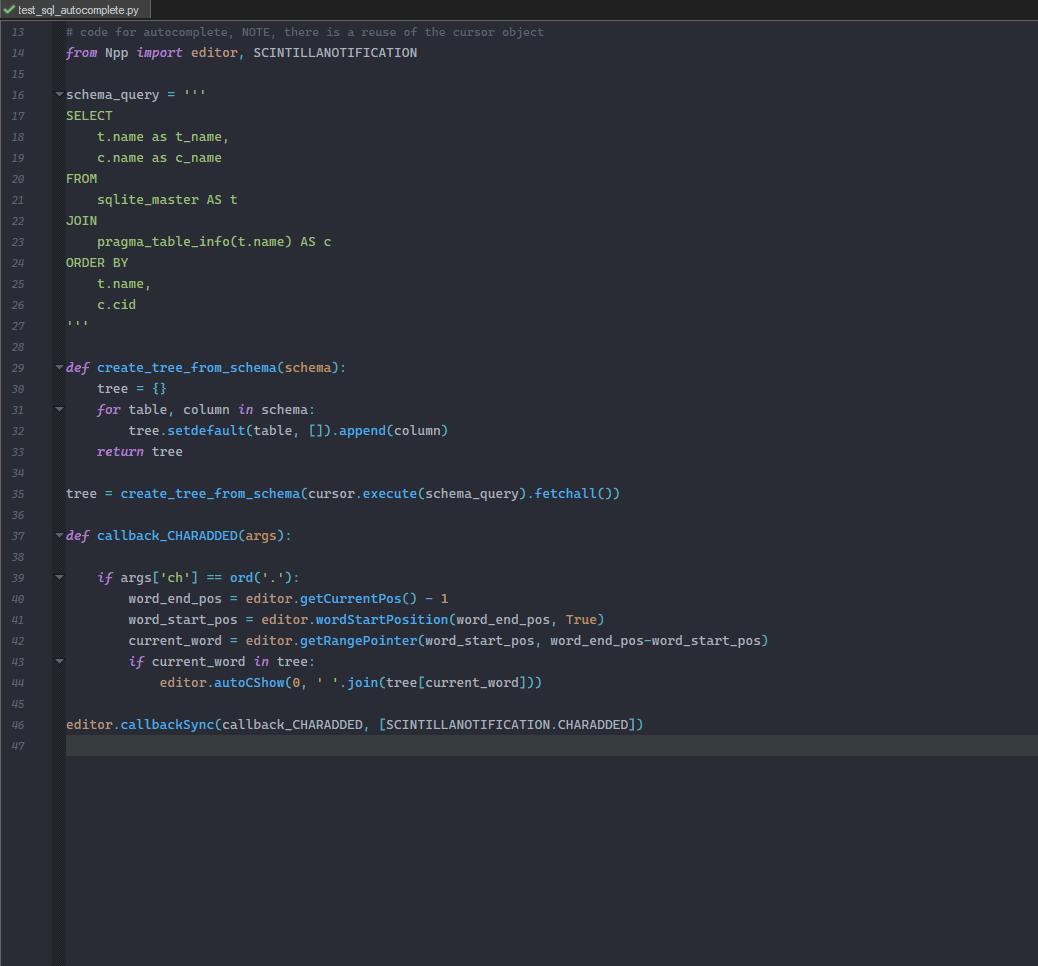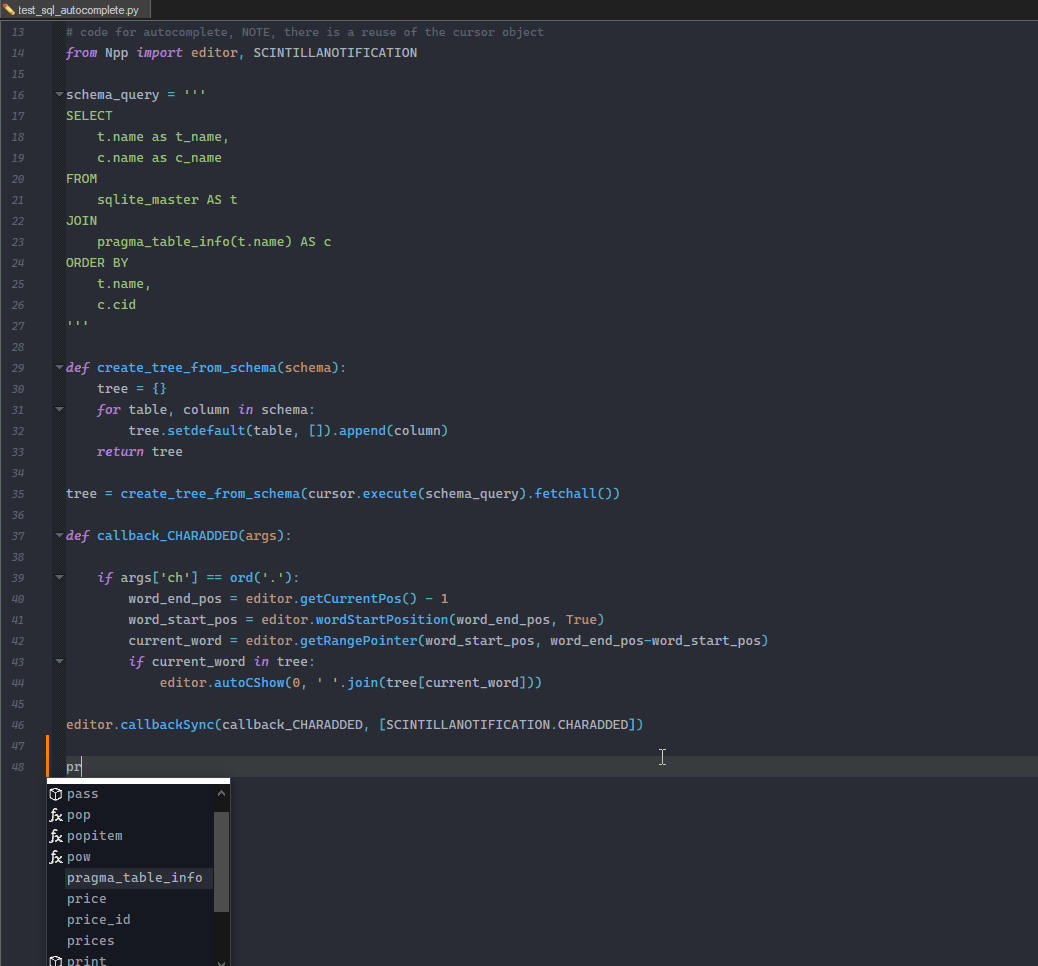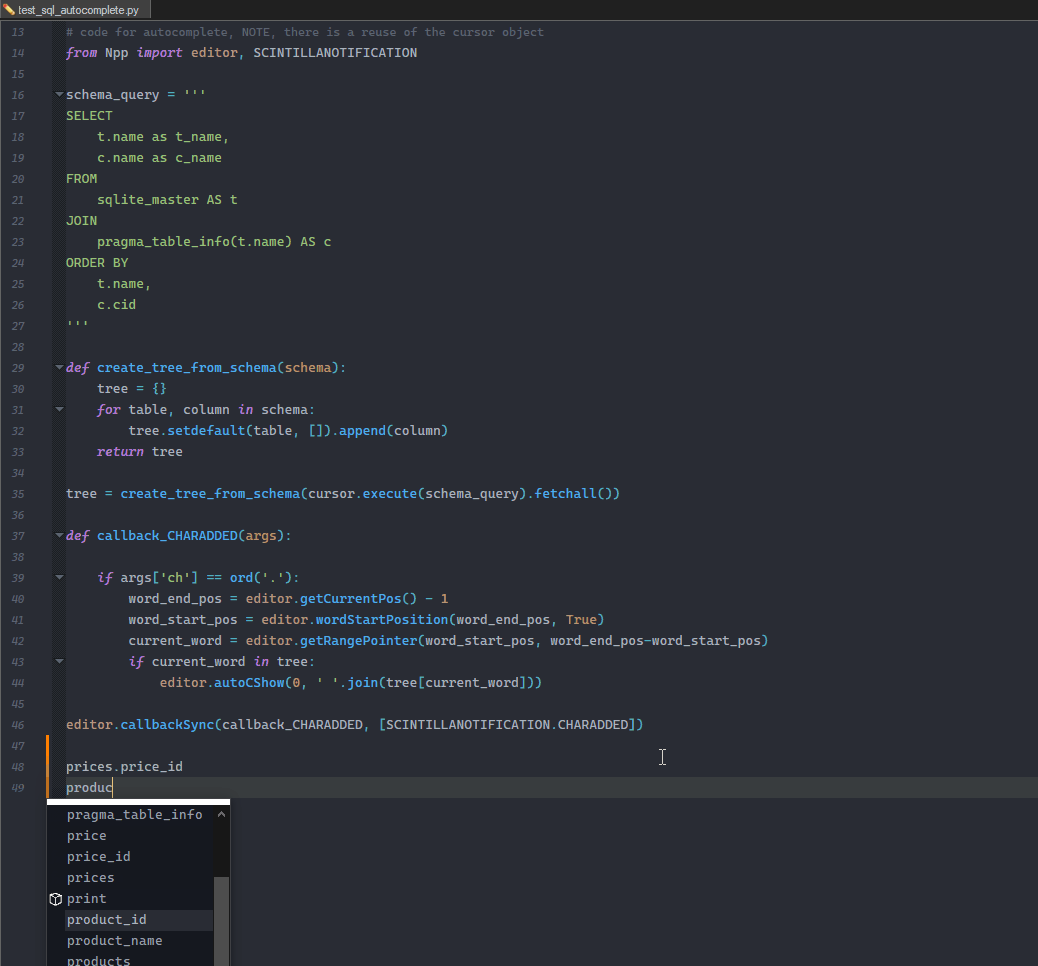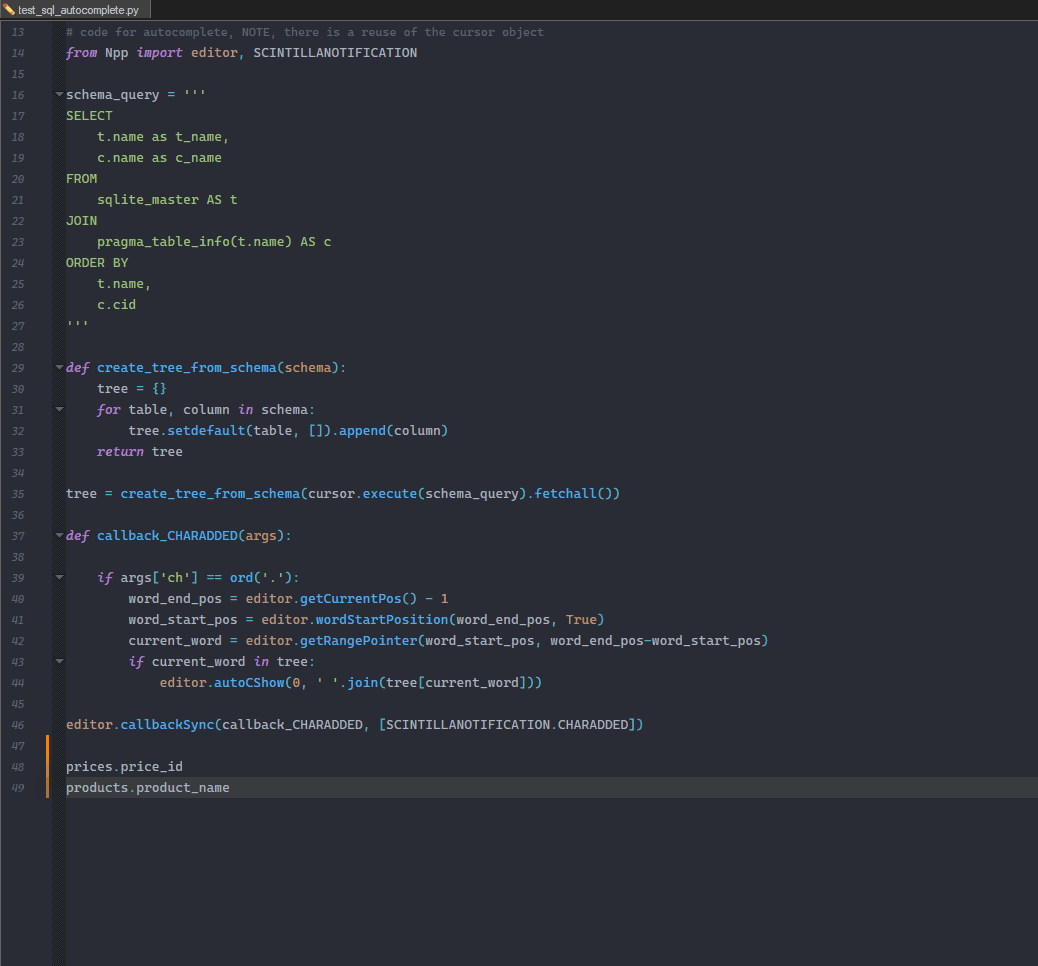
the missing part of the sqlite db
# create the test database import sqlite3 conn = sqlite3.connect(':memory:') cursor = conn.cursor() cursor.execute('CREATE TABLE products ([product_id] INTEGER PRIMARY KEY, [product_name] TEXT)') cursor.execute('CREATE TABLE prices ([price_id] INTEGER PRIMARY KEY, [price] INTEGER)') conn.commit() cursor.execute('INSERT INTO products (product_id, product_name) VALUES (1,"Banana"), (2,"Aspargus")') cursor.execute('INSERT INTO prices (price_id, price) VALUES (1,10), (2,20)') conn.commit() -
Just a small example of what can be done.
Bravo!
I touched it up a bit just to illustrate how user input can be bound to a prepared statement; that way completions will reflect any live changes from DDL queries that DROP, CREATE or ALTER tables.
import sqlite3 from Npp import editor, SCINTILLANOTIFICATION DB = None SCHEMA_QUERY = ''' SELECT t.name as t_name, c.name as c_name FROM sqlite_master AS t JOIN pragma_table_info(t.name) AS c WHERE /* provide a placeholder for user input */ t.name LIKE ? ORDER BY t.name, c.cid ; ''' def scaffold_db(): # pass the `check_same_thread` arg to avoid an exception: # 'sqlite3.ProgrammingError: SQLite objects created in a thread can only be used in that same thread.' # https://stackoverflow.com/a/48234567 conn = sqlite3.connect(':memory:', check_same_thread=False) cursor = conn.cursor() cursor.execute('CREATE TABLE products ([product_id] INTEGER PRIMARY KEY, [product_name] TEXT)') cursor.execute('CREATE TABLE prices ([price_id] INTEGER PRIMARY KEY, [price] INTEGER)') conn.commit() cursor.execute('INSERT INTO products (product_id, product_name) VALUES (1,"Banana"), (2,"Aspargus")') cursor.execute('INSERT INTO prices (price_id, price) VALUES (1,10), (2,20)') conn.commit() return cursor def create_tree_from_schema(schema): tree = {} for table, column in schema: tree.setdefault(table, []).append(column) return tree def callback_CHARADDED(args): if args['ch'] == ord('.'): word_end_pos = editor.getCurrentPos() - 1 word_start_pos = editor.wordStartPosition(word_end_pos, True) current_word = editor.getRangePointer(word_start_pos, word_end_pos - word_start_pos) # bind the input to the prepared statement's LIKE clause; # note the trailing comma -- the string will be "exploded" into chars without it statement = DB.execute(SCHEMA_QUERY, ('%s%%' % current_word,)) tree = create_tree_from_schema(statement.fetchall()) if current_word in tree: editor.autoCShow(0, ' '.join(tree[current_word])) if __name__ == '__main__': if DB is None: DB = scaffold_db() editor.callback(callback_CHARADDED, [SCINTILLANOTIFICATION.CHARADDED]) -
Since a Python-based solution seems to be coming together, the script will need to be able to connect to an Oracle database in order to be of practical use to the OP.
That presumably means copy-pasting all the code here (first Oracle Python DB API implementer I’ve found, no idea if it’s good; I don’t use Oracle) into the directory containing the script.
Not a single line of code below has been executed. It is basically pseudocode until proven otherwise.
The plugin would probably want to do something like
from Npp import notepad import oracledb # the connection package AUTH_DICT = {"password": None, "other_stuff": None, "more_other_stuff": None} CONNECTION = None # this is a persistent connection to the Database def sign_into_database(): global AUTH_DICT, CONNECTION # check if you've already successfully logged in if not any(v is None for v in AUTH_DICT.values()): return for auth_type in AUTH_DICT: result = notepad.prompt("Enter your database {0}".format(auth_type), "Enter login credentials to sign into database") if result is None: # user cancel return AUTH_DICT[auth_type] = result # try to sign into the database # read the documentation for the Oracle connector to # find out how to do this at https://python-oracledb.readthedocs.io/en/latest/user_guide/connection_handling.html try: CONNECTION = oracledb.connect(*AUTH_DICT) except: # or maybe you need to do something extra and an exception wouldn't be raised? CONNECTION = None notepad.prompt("Login failed with credentials {0}".format(AUTH_DICT), "Login to database failed") for auth_type in AUTH_DICT: AUTH_DICT[auth_type] = None return notepad.prompt("Login successful!", "Login successful")Looking again in rdipardo’s script above, the
CONNECTIONobject would probably be in place of theDBobject he used, and this function would probably be in place of scaffold_db, and this function could be called multiple times to allow the user multiple attempts.Like I said, it’s pseudocode at present.
-

I have a project that may interest you jn-npp-scripts. He rudely responds some functionality you mentioned. The main language of this project is Javascript.The project was built on the basis of another project ( jn-npp-plugin ).
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login