Sélectionner le texte marqué / Select marked Text
-
@Denis-Adra said in Sélectionner le texte marqué / Select marked Text:
I thought that “paste to replace marked lines” would replace all the lines with my changes to the text I marked but it just adds my clipboard below the cursor. I don’t know if it’s a bad translation or if I misunderstood the feature but it’s not what I’m looking for.
Do you have any lines bookmarked? Because that’s an action in the Bookmark submenu of the Search menu.
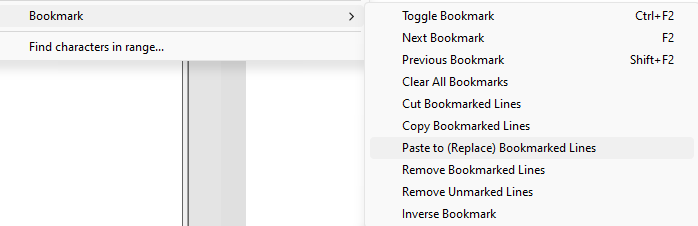
If I have
clipboardin my clipboard, and start with lines 2,3,and 5 bookmarked,
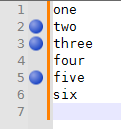
If then do Search > Bookmark > Paste to (Replace) Bookmarked Lines, it will properly replace each of the bookmarked lines with
clipboard.
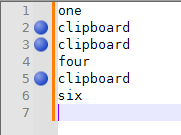
To get the bookmarks as the result of your search, you need to use the Mark tab of the dialog (or Search > Mark), and make sure
Bookmark Lineis checkmarked. Then after inputting your search string, Mark All to perform the search and make your bookmarks.
-
@PeterJones Hi, thanks for the answer.
So yes, it works but the problem is that it copies all the lines in each place marked.

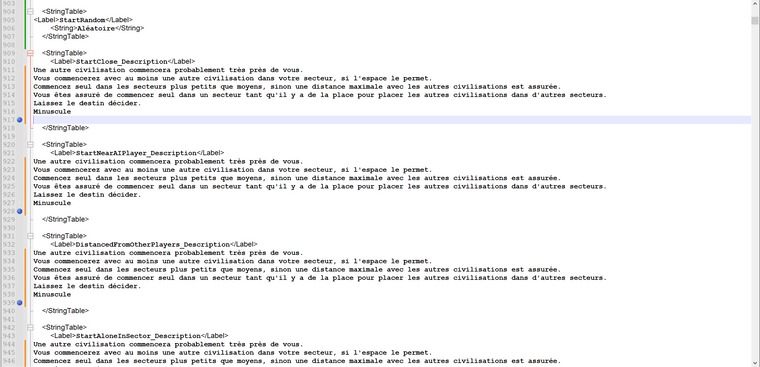
What I would like is to be able to copy the text that I have extracted and translated to the right line without having to do it manually line by line as I’v done since now.

For example by indicating that at each line break in my clipboard, another marker takes the copy. I don’t know if I’m making myself clear.
Otherwise, as I said, if there is a possibility to select all the StringTable and Label tags, then hide them all at once to let only the String tags be displayed, that would help me even more.
I could then replace all the string tags in the original file with the string tags in my translated file. Because I have also extracted the tags so I will only have to delete what is displayed in the original file, paste what I have in the translated file to the original and then display the hidden tags again. But I don’t know if that’s how it works.
On the other hand, I’ve edited by hand all the translations made with my tool and save the changes directly to the tool so that it doesn’t get “wrong” anymore. So redoing the whole translation is not a problem either as long as only the String tags are displayed.
I don’t know if I’m being clear, sorry.
-
You say you are working on a very large file, extracted the strings that need to be altered and now want to replace the original lines with the new version.
If I’m correct in my understanding I think the following would work for you:
- Number each line in the file by using the Edit, Column Editor, Number to insert (make sure leading zeros is selected).
- Use your “mark” regex to select the lines you wish to edit, then cut them from that file, and paste them into another tab. (Note cut, not copy).
- Edit those lines, then select them all and paste (anywhere) into the original file (generally after last line).
- Sort the lines using Edit, Line Operations, Sort Lines As Integers Ascending.
- Remove the leading line number.
The only issue is, that you may have already gone past step #1 and don’t want to have to redo the edits. If that is the case it might be possible to work with that. It does complicate matters but not impossible to overcome.
The lines which have been edited would need lines numbers added (in the same manner as step #1 above, except make all these lines odd numbers, so increase by 2.
For the lines as they originally appeared in the original file, after doing step #1 and #2, insert into a new tab, then reapply line numbers as step #1, but starting with 2 and also increasing by 2, so all even numbers.
Then combine these lines with the edited versions and sort by line number (as per step #4). This places the original line together with it’s edited version. I’ll leave it up to you to combine those 2 lines so that you keep the original line number but with the edited text.
Lastly you would complete steps #3 (just the pasting into original file part), and steps #4 and #5.
Hopefully you understand english well enough to go through all these ideas.
Terry
-
@Terry-R Hi, thanks a lot, it works very well.
The only problem now is that I don’t know how to remove the numbering :P.
I went back to the top of the document to delete the first issue but the rest remains. I opened the panel with ALT+C and delete the initial number but that doesn’t work either.
-
As long as the numbers are all in the same first few columns you can select by using the ctrl and alt keys along with the left mouse button. You will need to sweep over all the lines for those columns, then hit delete.
You could also use a regex, but as I haven’t seen any examples I can’t guarantee a possible regex might not capture unwanted numbers behind the line number. For example
^\d{4}will capture numbers as long as 4 (or more, but only capture 4 of them) at the start of a line.Terry
-
Hello, @denis-adra, @terry-r, @peterjones and All,
@denis-adra, the problem is to know how you organized your data !
You said that you extracted all the date between the two tags
<String>and</String>, thanks to the regex :(?s-i)(?<=<String>).+?(?=</String>)Note que your regex should not give the expected results and that the correct version is, actually :
(?-si)(?<=<String>).+?(?=</String>)
Now, I presume that you already did all these steps :
-
Select the Mark tab (
Ctrl + M) -
Type, in Find what zone, the regex
(?-si)(?<=<String>).+?(?=</String>) -
Uncheck ALL the options
-
Only Check the
Purge for each searchancWrap aroundoptions -
Click on the
Mark Allbutton -
Click on the
Copy Mark Text -
Open a new file (
Ctrl + N) -
Paste the clipboard contents (
Ctrl + V) -
Save this new file
Your file should look, as below :
Ship Name Big Ship ... ... ...The file format to aim for could be, for instance, this :
Ship Name : Nom du vaisseau Big Ship : Grand vaisseau ... ... ...It would contain, both, the English words to be translated and the translated French words, on the same line !
On the other hand, could you tell us the number, even approximative, of lines of your file, needing translation ?
My idea is to add this file, containing the English words and their French translation, at the end of your original file, separated with a line of, let’s say, some equal signs, resulting in :
<String>Ship Name</String> <Label>BIGSHIP</Label> <String>Big Ship</String> =============================== Ship Name : Nom du vaisseau Big Ship : Grand vaisseauThen, with that S/R, in regex mode, within your original : file :
SEARCH
(?x-is) (?<= <String> ) ( .+? ) (?= </String> (?s: .+ =+ .* ) (?-s: ^ \1 \x20 : \x20 ( .+ ) ) ) | (?s) ^ =+ .+REPLACE
\2With the
Wrap aroundoption checked and after a click on theReplace Allbutton, you end up with the expected text, below :<String>Nom du vaisseau</String> <Label>BIGSHIP</Label> <String>Grand vaisseau</String>See you later
Best Regards
guy038
P.S. : I will explain how these regular expressions work later !
Hello, @denis-adra, @terry-r, @peterjones et Tous,
@denis-adra, le problème est de savoir comment tu as organisé tes données !
Tu as dit que tu as extrait toutes les données entre les deux tags
<String>et</String>, grâce à la regex :(?s-i)(?<=<String>).+?(?=</String>)Note que ta regex ne doit pas donner les résultats escomptés et que la version correcte est, en fait :
(?-si)(?<=<String>).+?(?=</String>)
Maintenant, je suppose que tu as déjà réalisé toutes ces étapes :
-
Sélectionner l’onglet Marquer (
Ctrl + M) -
Saisir, dans la zone Recherche, la regex
(?-si)(?<=<String>).+?(?=</String>) -
Décocher TOUTES les options
-
Cocher uniquement les cases
Purger à chaque foisetBoucler -
Cliquer sur le bouton
Rechercher Tout( ouMarquer Tout? ) -
Cliquer sur le bouton
Copier le texte marqué -
Ouvrir un nouveau fichier (
Ctrl + N) -
Recopier le contenu du presse-papiers (
Ctrl + V) -
Sauvegarder ce nouveau fichier
Ton fichier doit, à présent, se présenter comme ci-dessous
Ship Name Big Ship ... ... ...Le format de fichier, vers lequel on doit tendre, serait, par exemple, celui-ci :
Ship Name : Nom du vaisseau Big Ship : Grand vaisseau ... ... ...Il contiendrait en effet, à la fois, les mots à traduire et les mots traduits, sur une même ligne !
D’autre part, peux-tu nous dire le nombre, même approximatif, de lignes de ton fichier, nécessitant traduction ?
Mon idée est d’ajouter ce fichier, contenant les mots anglais et leur traduction française, à la fin de ton fichier d’origine, séparé par une ligne de, disons, quelques signes
egal, ce qui donne :<String>Ship Name</String> <Label>BIGSHIP</Label> <String>Big Ship</String> =============================== Ship Name : Nom du vaisseau Big Ship : Grand vaisseauPuis, avec le recherche/remplacement suivante, en mode regex, dans ton fichier d’origine :
SEARCH
(?x-is) (?<= <String> ) ( .+? ) (?= </String> (?s: .+ =+ .* ) (?-s: ^ \1 \x20 : \x20 ( .+ ) ) ) | (?s) ^ =+ .+REPLACE
\2Avec l’option
Boucleret après appui sur le boutonRemplacer Tout, tu aboutis au texte escompté, ci-dessous :<String>Nom du vaisseau</String> <Label>BIGSHIP</Label> <String>Grand vaisseau</String>A+
Amitiés
guy038
P.S. : Je t’expliquerai le fonctionnement de ces expressions régulières, par la suite !
-
-
@Terry-R Je te réponds déjà toi. Ensuite je répond dans un autre commentaire à @guy038
Here is my structure:
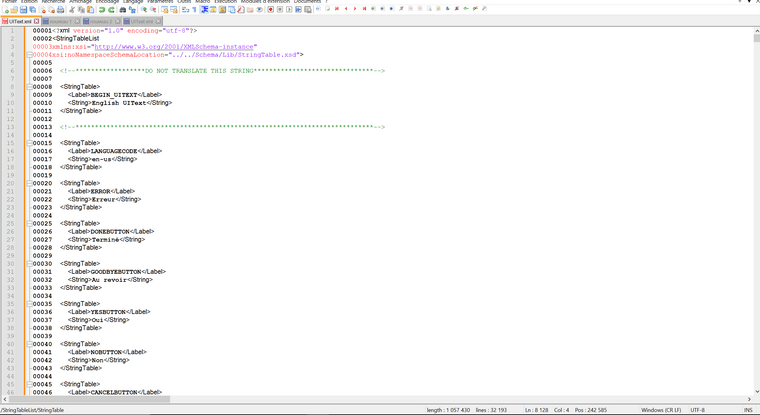
My zegex search works very well
Here is the result.
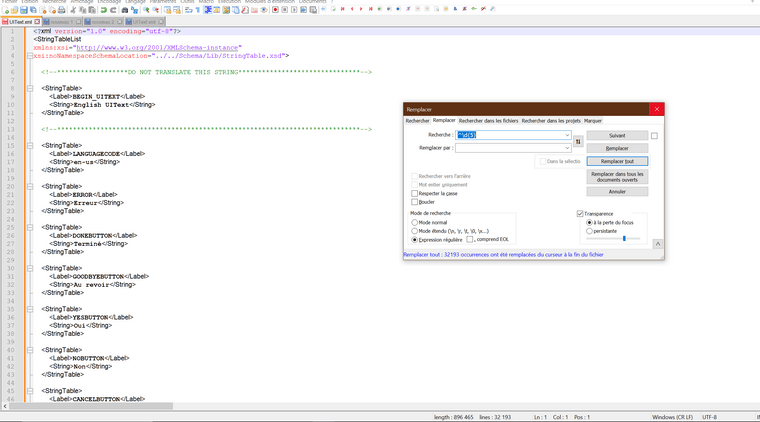
The only problem I have is that I can’t validate the XML with XML Tool now.
I reloaded a version of the file just before the numerotation to check if I had not broken something myself with my manual modifications but no, the check to verify the sytax went well.
Here when I replace everything by : leave the field empty with the search function ^\d{5} and then check the syntax, it doesn’t validate me and throws me on the 1st line but I can’t see where it can come from.
If we compare with the unmodified original file we realize that it is exactly the same:


In the same way, when I ask to XML Tool to look for the following error, it does not find any and remains blocked on the first line.
-
@Denis-Adra said in Sélectionner le texte marqué / Select marked Text:
it doesn’t validate me and throws me on the 1st line but I can’t see where it can come from.
Is it possible a line (somewhere in the file) still contains a number at the start of the line? You could attempt to “count” by using a similar regex
^\dand see if it returns something other than 0.Alternatively I could suggest this approach, and it’s quite drastic. On copies of the before and after files, remove all the text which you changed, essentially
>[^<]+and replace with>. This will remove all text which is different and leaves what I might call a blank template file. Then open both of those blank files and use the compare plugin (ComparePlus) and see if it can detect any other changes in the files.I note you suggested you were comparing, but a visual compare isn’t good enough as maybe a “hidden” character remains, or when trying to view the whole file a character out of place will be hard to notice.
Terry
-
@guy038 Hi, Thanks for your answer
So to start with, know that the formula I use to mark the text between the String tags is yours. :P It comes from a post from 2021 where someone was trying to do more or less the same thing but on other tags. I got the formure as it is and adapted it by changing just the tags I was interested in.
However, I tried the formula you suggest in the previous post and it works too. I was lucky that the one I used allowed me to do what I wanted.
As for your process, surprisingly, I understand it. I see what you are trying to do. This file being finished (well it will be when I will have succeeded in having the synthaxe validated) I will try your procedure on the next file.
Concerning this file, the original (not translated) contains exactly 866 420 characters for 32193 lines.
My translated file contains 896 465 characters for 32193 lines.
The exact number of lines to translate is 6703. All lines have been translated. Many of them thanks to a tool (correcting the errors manually) the rest were translated entirely manually
-
Hi, @denis-adra, @terry-r, @peterjones and All,
Ah… OK, Of course, your real data is not exactly what I initially thought of. Thus, my previous regex, for a correct translation, will have to be improved !
So, @denis-adra, if you don’t mind, could you show us :
-
Some sections, of your
XMLoriginal file, needing translation ( let’s say about50), which stands as the INPUT text -
The corresponding text that you would like to get as OUTPUT text
Therefore, and this is important, when you write your post, on our forum, click on the
</>icon, to place the texts, to be submitted, in code form !Thanks for your cooperation !
See you later,
guy038
Ah…, BTW, I’m French !
Hi, @denis-adra, @terry-r, @peterjones and Tous,
Ah… OK, Bien sur, tes données réelles ne sont pas exactement comme je le pensais initiallement. Par conséquent, mon expression régulière précédente, pour une traduction correcte, devra être améliorée !
@denis-adra, si tu n’y vois pas d’inconvénient, pourrais-tu nous montrer :
-
Quelques sections, de ton fichier
XMLd’origine, nécessitant traduction ( disons environ50), représentant le texte en ENTREE -
Le texte correspondant que tu aimerais obtenir en SORTIE
Pour cela, et c’est important, lorsque tu rédiges ton message, sur notre forum, clique sur l’icône
</>pour placer les textes à soumettre sous forme de code !Merci de ta coopération !
A+,
guy038
Ah…, à propos, je suis français !
-
-
@guy038 Hi,
can you explain me the way you want to proceed to add at the bottom of my file the translated and untranslated words? I would like to try this method.
The problem is that in order to try Terry’s method and check that I could paste all the changes in the right place, I translated a part of the file with the Deepl application (a part of the numbered part, cut and pasted on a new tab). I just noticed that the application translated me from <String> to <Chaine> even <Chaine> despite the rule I put in the glossary of <String>=<String>. It also doubled or even tripled me some </String> That’s what causes my failure in checking the synthaxis. Identifying it is one thing, the other concern being that even with the “replace” function I can’t find all the duplicates. I solved the problem of the <Strings> but not the one of the double-triple </String>.
By the way. the regex formula you suggest does not select me in all String tags. It leaves some of them empty. Some whose first character that follows the Tag is a parenthesis for example. On the other hand your old formula that I use, it selects me well all the texts in the String tags
Here Some Input text : ```
Host: Password: Number of Sectors: Max Humans: Game Mode: Map: Civilization Player Intelligence Restore Session Disconnected Your connection has failed. Please verify that Steam is running and you are in online mode to play. Your connection is pending or failed. Check to see if there is a browser window in the background with the Epic Account Portal waiting for a response. Metaverse is currently unavailable. Please try again later. Scroll through the Metaverse to see your stats. Mod Manager is currently unavailable. Please try again later. Access our Mod Metaverse. Mod update(s) available. Messages(s) available. Return to the main menu. Browse mods available online. Manage installed mods. Browse previous list of mods. Browse next list of mods. Reports this mod. Moderators will be notified and action may or may not be taken based on their evaluation. Upvote mod. Downvote mod. Download mod to your local machine. Return to Workshop. Your connection has failed. Please verify that GOG Galaxy is running and you are online to play. Refresh Start Ready Ready? Claim? Only the host can add AI players. Other players can claim this Civilization to play as them. To play as this Civilization, claim them for yourself. Convert Ready Human Players Added AI Players Pending Human Players Available AI Players Unclaimed Human Players Unclaimed AI Players Drop Waiting Add Player Ping Movie VolumeOUTPUT
Hôte : Mot de passe : Nombre de secteurs : Nombre maximum d'humains : Mode de jeu : Carte : Civilisation Joueur Intelligence Restaurer la session Déconnecté Votre connexion a échoué. Veuillez vérifier que Steam fonctionne et que vous êtes en mode en ligne pour jouer. Votre connexion est en attente ou a échoué. Vérifiez qu'il n'y a pas de fenêtre de navigateur en arrière-plan avec le portail de compte Epic en attente d'une réponse. Metaverse est actuellement indisponible. Veuillez réessayer plus tard. Parcourez le Metaverse pour voir vos statistiques. Mod Manager est actuellement indisponible. Veuillez réessayer plus tard. Accédez à notre Mod Metaverse. Mise(s) à jour disponible(s). Messages disponibles. Retournez au menu principal. Parcourir les mods disponibles en ligne. Gérer les mods installés. Parcourir la liste précédente de mods. Parcourir la liste suivante de mods. Signalez ce mod. Les modérateurs en seront informés et des mesures pourront être prises ou non en fonction de leur évaluation. Upvote mod. Downvote mod. Télécharger le mod sur votre machine locale. Retourner à l'atelier. Votre connexion a échoué. Veuillez vérifier que GOG Galaxy fonctionne et que vous êtes en ligne pour jouer. Rafraîchir Démarrer Prêt Prêt ? Réclamer ? Seul l'hôte peut ajouter des joueurs IA. Les autres joueurs peuvent revendiquer cette civilisation pour l'incarner. Pour incarner cette civilisation, revendiquez-la pour vous-même. Convertir Joueurs humains prêts Joueurs IA ajoutés Joueurs humains en attente Joueurs IA disponibles Joueurs humains non réclamés Joueurs IA non réclamés Déposés En attente Ajouter Joueur Ping Volume du film@guy038 said in Sélectionner le texte marqué / Select marked Text:
Ah…, à propos, je suis français !
I had guessed :p
-
Finally! It works !
I did most of the work with this file and I would never have succeeded without your help. @Terry-R @guy038 @PeterJones Thank you so much.
I still have some work to do of course and a lot of checking to do. I’m still looking for new ideas that could help me speed up the process and … I’m waiting to see the procedure of the method you propose, it interests me a lot!
I can’t visualize how I can “automate” the entry of the word to translate + the translated word.
Maybe by numbering? A file with the words to be translated, another file with the translated words that all have the same numbering that I would have created beforehand in the file to be translated? Well, I really don’t know how it works but I must admit that it’s quite exciting all these little formulas.
-
Hi, @denis-adra, @terry-r, @peterjones and All,
I think that you misunderstood me, regarding the INPUT and OUTPUT text !
Of course, I didn’t think about the simple lists of words to be translated and the translated words themselves !
So, I’m going to try to guess what you want !
You have two distinct INPUT files :
- A first
XMLfile :
<STring Table> <Label>SartClose_Description</Label> <String>An other civilization will likely start close to you.</String> </String Table> <STring Table> <Label>StartNearAIPlayer_Description</Label> <String>You will start with at least one other civilization in your sector, space permitting.</String> </String Table> <STring Table> <Label>DistanceFromOtherPlayer_Description</Label> <String>Start alone in sectors smaller than medium, otherwise a maximum distance from other civilisation ensured.</String> </String Table>- A second text file, containing, only, the French translations :
Une autre civilisation commencera probablement très près de vous. Vous commencerez avec au moins une civilisation dans votre secteur, si l'espace le permet. Commencez seul dans les secteurs plus petits que moyens, sinon une distance maximum avec les autres civilisations est assurée.And you would like to get the following OUTPUT file :
<STring Table> <Label>SartClose_Description</Label> <String>Une autre civilisation commencera probablement très près de vous.</String> </String Table> <STring Table> <Label>StartNearAIPlayer_Description</Label> <String>Vous commencerez avec au moins une civilisation dans votre secteur, si l'espace le permet.</String> </String Table> <STring Table> <Label>DistanceFromOtherPlayer_Description</Label> <String>Commencez seul dans les secteurs plus petits que moyens, sinon une distance maximum avec les autres civilisations est assurée.</String> </String Table>Do you agree with my analyze ?
-
In case of a positive answer, see, further on, about a possible solution !
-
In case of a negative answer, try to explain me which files are concerned !
If you agree, my method implies to install, first, the
BetterMultiSelectionPluginIndeed, this plugin will allow us to place the French translations on the right lines of your
XMLfile !Now, in the second file, containing the French translations ONLY, one per line :
-
Perform the following regex S/R :
-
SEARCH
(\R) -
REPLACE
\1\1\1\1\1
-
So, we get this text :
Une autre civilisation commencera probablement très près de vous. Vous commencerez avec au moins une civilisation dans votre secteur, si l'espace le permet. Commencez seul dans les secteurs plus petits que moyens, sinon une distance maximum avec les autres civilisations est assurée.- Then, add two empty lines at the beginning of this text and delete the last emoty lines, in order to get the following text :
Une autre civilisation commencera probablement très près de vous. Vous commencerez avec au moins une civilisation dans votre secteur, si l'espace le permet. Commencez seul dans les secteurs plus petits que moyens, sinon une distance maximum avec les autres civilisations est assurée.-
Now, do a rectangular selection of this text, with
Alt+Shift, including the first two empty lines ( Important ) till the last lineCommencez seul ... -
Click on the
Endkey for a complete selection -
Copy this text with the
Ctrl + Cshortcut
Note that, with real data, you may wait up to a minute to see all the text selected !
-
Select your first
XMLfile -
Move the cursor right before the first
<String Table>of your list -
Press
Ctrl + V
Again, with real data, you may wait for more than a minute !
Regarding our example, you should get this temporary text :
<String Table> <Label>SartClose_Description</Label> Une autre civilisation commencera probablement très près de vous. <String>An other civilization will likely start close to you.</String> </String Table> <String Table> <Label>StartNearAIPlayer_Description</Label> Vous commencerez avec au moins une civilisation dans votre secteur, si l'espace le permet. <String>You will start with at least one other civilization in your sector, space permitting.</String> </String Table> <String Table> <Label>DistanceFromOtherPlayer_Description</Label> Commencez seul dans les secteurs plus petits que moyens, sinon une distance maximum avec les autres civilisations est assurée. <String>Start alone in sectors smaller than medium, otherwise a maximum distance from other civilisation ensured.</String> </String Table>
Finally, with that last regex S/R :
SEARCH
(?x-is) ^ ( [^< \r\n] .+ \. ) ( \x20+ <String> ) .+ ( </String> )REPLACE
\2\1\3We get our expected OUTPUT text :
<String Table> <Label>SartClose_Description</Label> <String>Une autre civilisation commencera probablement très près de vous.</String> </String Table> <String Table> <Label>StartNearAIPlayer_Description</Label> <String>Vous commencerez avec au moins une civilisation dans votre secteur, si l'espace le permet.</String> </String Table> <String Table> <Label>DistanceFromOtherPlayer_Description</Label> <String>Commencez seul dans les secteurs plus petits que moyens, sinon une distance maximum avec les autres civilisations est assurée.</String> </String Table>Best Regards,
guy038
P.S. : I did a real test with a list of
6,750French translations and the same number of sections in a dummyXMLfile and everything went OK !
Je pense que tu m’a mal compris en ce qui concerne le texte ENTREE et le texte de SORTIE !
Bien entendu, je ne pensais pas aux simples listes de mots à traduire et de mots traduits !
Aussi, je vais essayer de deviner ce que tu désires :
Tu as donc deux fichiers d’ENTREE distincts :
- Un premier fichier
XML:
<String Table> <Label>SartClose_Description</Label> <String>An other civilization will likely start close to you.</String> </String Table> <String Table> <Label>StartNearAIPlayer_Description</Label> <String>You will start with at least one other civilization in your sector, space permitting.</String> </String Table> <String Table> <Label>DistanceFromOtherPlayer_Description</Label> <String>Start alone in sectors smaller than medium, otherwise a maximum distance from other civilisation ensured.</String> </String Table>- Un 2ème fichier texte, contenant, uniquement, les traductions françaises :
Une autre civilisation commencera probablement très près de vous. Vous commencerez avec au moins une civilisation dans votre secteur, si l'espace le permet. Commencez seul dans les secteurs plus petits que moyens, sinon une distance maximum avec les autres civilisations est assurée.Et tu voudrais obtenir le seul fichier de SORTIE suivant :
<String Table> <Label>SartClose_Description</Label> <String>Une autre civilisation commencera probablement très près de vous.</String> </String Table> <String Table> <Label>StartNearAIPlayer_Description</Label> <String>Vous commencerez avec au moins une civilisation dans votre secteur, si l'espace le permet.</String> </String Table> <String Table> <Label>DistanceFromOtherPlayer_Description</Label> <String>Commencez seul dans les secteurs plus petits que moyens, sinon une distance maximum avec les autres civilisations est assurée.</String> </String Table>Es-tu d’accord avec mon analyse ?
-
En cas de réponse positive, regarde, ci-après, une solution possible !
-
En cas de réponse négative, essaye de m’expliquer, quels sont les fichiers impliqués !
Si tu es d’accord, ma méthode implique d’installer, en premier, le plugin
BetterMultiSelectionVraiment, ce plugin nous permettra de placer les traductions françaises sur les bonnes lignes de ton fichier
XML!Maintenant, dans le second fichier, contenant les traductions françaises UNIQUEMENT, une par ligne :
-
Execute la regex S/R suivante :
-
SEARCH
(\R) -
REPLACE
\1\1\1\1\1
-
Nous obtenons donc ce text :
Une autre civilisation commencera probablement très près de vous. Vous commencerez avec au moins une civilisation dans votre secteur, si l'espace le permet. Commencez seul dans les secteurs plus petits que moyens, sinon une distance maximum avec les autres civilisations est assurée.- A présent, ajoute deux lignes vides au début de ce texte et supprime les dernières lignes vides, de façon à obtenir le texte suivant :
Une autre civilisation commencera probablement très près de vous. Vous commencerez avec au moins une civilisation dans votre secteur, si l'espace le permet. Commencez seul dans les secteurs plus petits que moyens, sinon une distance maximum avec les autres civilisations est assurée.-
Maintenant, effectue une sélection rectangulaire de ce texte, avec
Alt+Shift, incluant les deux premières lignes vides ( Important ) jusqu’à la dernière ligneCommencez seul ... -
Clique sur la touche
Fin, pour une sélection complète -
Copie ce texte avec le raccourci
Ctrl + C
Note qu’avec des données réelles, tu peux attendre jusqu’à une minute pour voir tout le texte sélectionné !
-
Sélectionne ton premier fichier
XML -
Place le curseur juste devant le premier
<String Table>de ta liste -
Appuie sur
Ctrl + V
De nouveau, avec des données réelles, tu peux attendre plus d’une minute !
Concernant notre exemple, tu devrais obtenir ce texte temporaire :
<String Table> <Label>SartClose_Description</Label> Une autre civilisation commencera probablement très près de vous. <String>An other civilization will likely start close to you.</String> </String Table> <String Table> <Label>StartNearAIPlayer_Description</Label> Vous commencerez avec au moins une civilisation dans votre secteur, si l'espace le permet. <String>You will start with at least one other civilization in your sector, space permitting.</String> </String Table> <String Table> <Label>DistanceFromOtherPlayer_Description</Label> Commencez seul dans les secteurs plus petits que moyens, sinon une distance maximum avec les autres civilisations est assurée. <String>Start alone in sectors smaller than medium, otherwise a maximum distance from other civilisation ensured.</String> </String Table>
Finalement, avec cette dernière regex S/R :
SEARCH
(?x-is) ^ ( [^< \r\n] .+ \. ) ( \x20+ <String> ) .+ ( </String> )REPLACE
\2\1\3Nous obtenons notre texte de SORTIE escompté :
<STring Table> <Label>SartClose_Description</Label> <String>Une autre civilisation commencera probablement très près de vous.</String> </String Table> <STring Table> <Label>StartNearAIPlayer_Description</Label> <String>Vous commencerez avec au moins une civilisation dans votre secteur, si l'espace le permet.</String> </String Table> <STring Table> <Label>DistanceFromOtherPlayer_Description</Label> <String>Commencez seul dans les secteurs plus petits que moyens, sinon une distance maximum avec les autres civilisations est assurée.</String> </String Table>Amitiés
guy038
P.S. : j’ai fait un test réel avec une liste de
6,750tranductions françaises et le même nombre de sections dans un fichierXMLbidon et tout est OK ! - A first
-
@denis-adra and All,
Just note the general process of fusion, between the two files, allowed by the
BetterMultiSelectionplugin :Main XML file, BEFORE TRANSLATIONS file Main XML file, AFTER <String Table> EMPTY line <String Table> <Label>SartClose_Description</Label> EMPTY line <Label>SartClose_Description</Label> <String>This is a test.> C'est un test. C'est un test. <String>This is a test.</String> </String Table> EMPTY line </String Table> + EMPTY line = <String Table> EMPTY line <String Table> <Label>StartNearAIPlayer_Description</Label> EMPTY line <Label>StartNearAIPlayer_Description</Label> <String>Easy to do.</String> Facile à faire Facile à Faire <String>Easy to do.</String> </String Table> EMPTY line </String Table> EMPTY line ...Of course, this suppose an exact match between the two files, with the same repeated template !
BR
guy038
Note le processus général de fusion, entre les deux fichiers, permis par le plugin
BetterMultiSelectionFichier XML principal, AVANT Fichier des TRADUCTIONS Fichier XML principal, APRÈS <String Table> EMPTY line <String Table> <Label>SartClose_Description</Label> EMPTY line <Label>SartClose_Description</Label> <String>This is a test.> C'est un test. C'est un test. <String>This is a test.</String> </String Table> EMPTY line </String Table> + EMPTY line = <String Table> EMPTY line <String Table> <Label>StartNearAIPlayer_Description</Label> EMPTY line <Label>StartNearAIPlayer_Description</Label> <String>Easy to do.</String> Facile à faire Facile à Faire <String>Easy to do.</String> </String Table> EMPTY line </String Table> EMPTY line ...Bien sur, cela suppose une exacte correspondance, entre les deux fichiers, avec le même motif répété !
Bien à toi,
guy038
-
Hey hi @guy038 , I’m coming back to you
It’s been a busy day between yesterday and today.
Thanks for the new information. The method you propose is very interesting. Longer and a little more complicated than @Terry-R 's but in the end safer because it is true that when you finalize, there are no mistakes left. Where it can often remain with a numbering system that by dint of being cut and pasted and even sometimes unexpectedly taken in the selection that will pass to the translation, it happens that it gets mixed with the paragraphs. In the end, the time I save with the numbering system, I often lose later to detect and correct the mistakes. Note, this is entirely my fault because I could have or should have made a selection in columns.
In order not to let your help and efforts go to waste, I used your method on the 10 or so small files I had left and it works very well. Many thanks to you!
A huge thank you also to @Terry-R , because his method arrived quite quickly. At a time when I was more than tired of editing a 400k file by hand and wanted to give up more than once!
Finally, thank you all for all this advice @guy038 @Terry-R @PeterJones . As I said before, I am not an expert in notepad++ at all. I’ve done a degree in computer science 15 years ago, but I’m not at all specialized in programming and I’m doing totally different things today. I found all these little tips very interesting and I’m sure they will be very useful in the future. Thanks again to both of you!
I’ve completely finished the translation, for the rest I’ll only have to touch up the fonts and make corrections that I would have noticed in game.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login