Regex use
-
@PeterJones Well, apologies, I saw the thing about the formatting but didn’t think it would be such a big deal. I’ll make sure to be more precise next time.
I for sure had the regex radio button clicked, and have double-checked that here and still not seeing it, using either the carat-and-dollar sign chars or not…
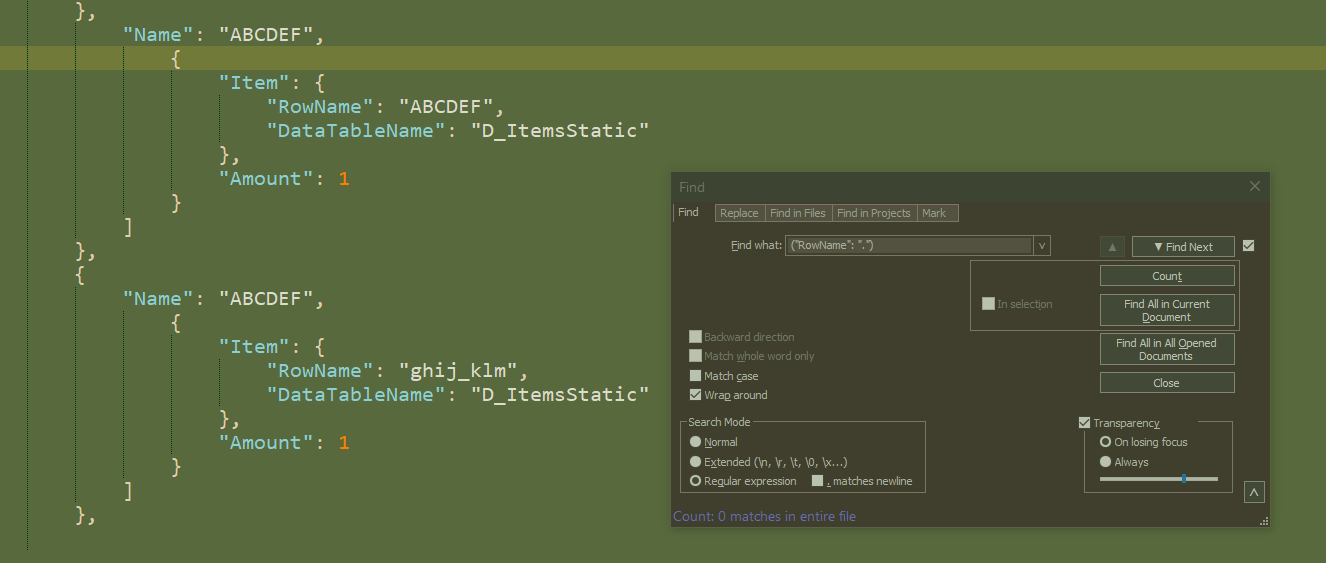
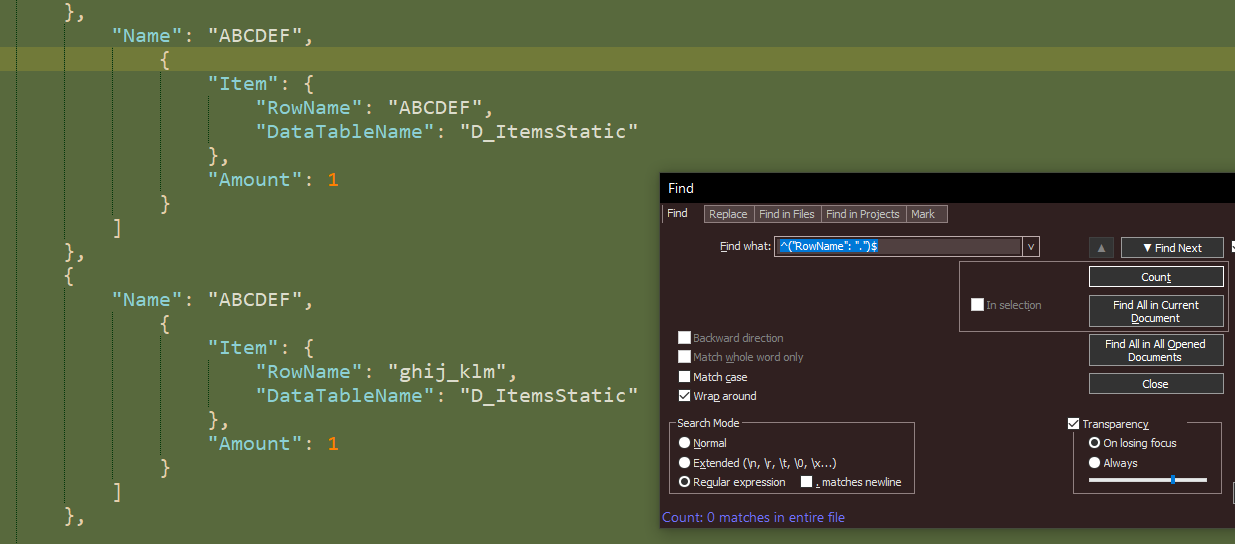
-
@CK-Dexterhaven said in Regex use:
I’ll make sure to be more precise next time.
It’s not just being picky. Regex are highly dependent on the actual data. The sole reason that my first regex didn’t work for you is because you were not precise enough because you had not followed the advice in that FAQ.
If I had made a regex to work on the data that we could see in the forum post, it would have been matching “smart quotes”, not ASCII
"quotes, which would not have worked for your data, based on your followon screenshot. The more times you give us misinformation about your data, the more time we waste helping you solve the wrong problem. This is why the formatting, and the other advice in that template, are of critical importance.In addition to that bad data:
Your screenshot also shows that your data is not at the beginning of the line. Your example data implied that the data was at the beginning of the line. (@Coises already pointed this out to you.) Since it’s not at the beginning of the line, using
^in the regex will not work, because that anchors it to the beginning of the line. If you had used the formatting box and pasted real data into that box, we could have seen that there were leading spaces in your data, and would have told you earlier that the^anchor doesn’t work for your data.Further, the line for your
"RowName": "value",pair has a comma after the end quote, so using the$to anchor it so the end quote must be right next to the end-of-line will not work (because the comma, not the quote mark, is next to the end of line; and maybe there’s even spaces after the comma that we cannot see).Hence, both the
^and$are wrong for your data, but we couldn’t tell that because you didn’t give good example data. The reason I spent the time writing up that FAQ with the template on how to do Search/Replace questions is because when new users of the forum ask their questions like you did, ignoring the advice of the FAQ, it takes multiple times back and forth before we can drag it out of you that the data you showed didn’t actually match the data that you wanted the regex to match, wasting everyone’s time.Further, you originally said “where X or Y is any character string”, which I interpreted to mean “is any single character string”, though @Coises was astute enough to point out that it was probably a bad assumption, too.
new solution
Now that we know better what your data looks like, the correct regular expression is probably:
FIND WHAT =("RowName": "\C+")
Note that there is no more^at the beginning or$at the end, and that it’s using\C+to indicate one or more characters, rather than a single character, between the quotes.I say “probably” because you gave a screenshot rather than pasting real text into the
</>code/plaintext block, so I still cannot copy/paste a real example of your data into my copy of Notepad++; because of that, I can only guess that I’ve properly interpreted the text from your screenshot -
This thread is a really good example on why NO help should be provided until proper procedure is followed. Posters that don’t shouldn’t be allowed to waste people’s time.
-
Hello, @ck-dexterhaven, @coises, @peterjones, @alan-kilborn and All,
@coises, contrary to what you may think, the regex syntax
\Cis a specificPERLfeature, which matches any individual bytes ofUTF-8characters, including the classical line-breaks. But, the N++ build of theBoostregex engine does not allow this feature to be available !As a consequence, with N++, the
\Cregex is always strictly identical to the.regex, whatever the modifiers(?s)or(?-s)are used or not
However, note that, IF this feature has been possible, it could have led to the creation of ill-formed
UTF-8characters, because\Cbreak up characters into individual code units !Luckily, we could have written the following regex, which properly preserves the
UTF-8structure and returns the character itself as group1and the individual bytes of the character, from1to4, as groups2,3,4and5:(?xs) ( (?| (?= [\x{0000}-\x{007F}] ) (\C) ( ) ( ) ( ) | (?= [\x{0080}-\x{07FF}] ) (\C) (\C) ( ) ( ) | (?= [\x{0800}-\x{FFFF}] ) (\C) (\C) (\C) ( ) | (?= [\x{10000}-\x{1FFFFF}] ) (\C) (\C) (\C) (\C) ) )Best Regards,
guy038
P.S. :
If we except the user-oriented Unicode planes
15and16and, as presently, the Unicode planes4to13are NOT used, and, probably, will never be used by the Unicode Consortium, I created a definitive file containing all the possible Unicode characters, whatever these chars are presently assigned or NON-assigned !This file, that I called
Total_Chars.txt, contains a definitive list of325,590possible characters, divided in5zones :-
All the possible characters of the
Plane 0, called BMP ( Basic Multilingual Plane ), i.e.65,536chars, minus the2,048chars of thesurrogatemechanism, minus the32NON-chars, between\x{FDD0}and\x{FDEF}and minus the two NON chars\x{FFFE}and\x{FFFF}. So, a total of65,536 - 2,048 - 32 - 2=63,454chars -
All the possible characters of the
Plane 1, i.e.65,536chars minus the two NON-chars\x{1FFFE}and\x{1FFFF}. So a total of65534chars -
All the possible characters of the
Plane 2, i.e.65,536chars minus the two NON-chars\x{2FFFE}and\x{2FFFF}. So a total of65534chars -
All the possible characters of the
Plane 3, i.e.65,536chars minus the two NON-chars\x{3FFFE}and\x{3FFFF}. So a total of65534chars -
All the possible characters of the
Plane 14, i.e.65,536chars minus the two NON-chars\x{EFFFE}and\x{EFFFF}. So a total of65534chars
And against the
Total_Chars.txtfile, the previous THEORICAL regex would detect325,590characters :(?xs) ( (?| (?= [\x{0000}-\x{007F}] ) (\C) ( ) ( ) ( ) | # 128 1-byte chars in part INSIDE the BMP | (?= [\x{0080}-\x{07FF}] ) (\C) (\C) ( ) ( ) | # 1,920 2-byte chars , in part INSIDE the BMP | 63,454 chars (?= [\x{0800}-\x{FFFF}] ) (\C) (\C) (\C) ( ) | # 61,406 3-byte chars , in part INSIDE the BMP | (?= [\x{10000}-\x{1FFFFF}] ) (\C) (\C) (\C) (\C) # 262,136 4-byte chars , in part OUTSIDE the BMP, with code > \x{FFFF} ( = 4 × 65,534 ) ) -
-
Just wanted to observe that the OP posted a picture using what appears to be the MossyLawn theme. Now that’s good taste.
-
@CK-Dexterhaven For what it is worth, I would have used the following regex in the “Find what” field:
"RowName":\h+\K"\w+",And in the “Replace with” field:
"new_text",Then I would have hit the button “Replace All” (not “Replace”, because of
\K). -
I didn’t notice until now that this post is about performing a regex-replace in JSON.
My JsonTools plugin offers a complete find-replace form for performing find/replace operations in JSON without messing with object keys. It even allows you to restrict your find/replaces to the children of certain keys. The find/replace form isn’t a silver bullet for every problem like this, but it’s pretty effective.
Here’s a screenshot of usage:
BEFORE
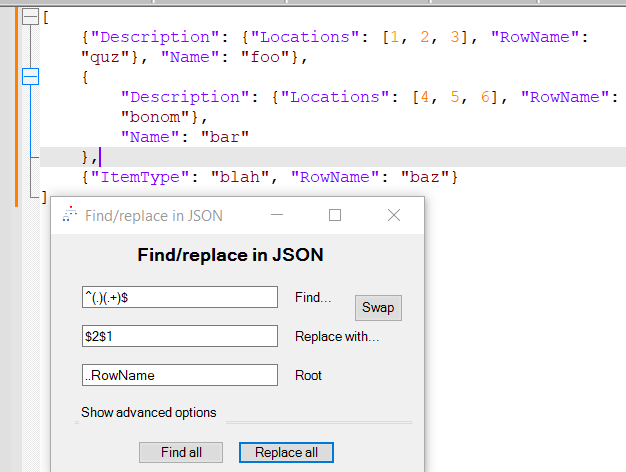
AFTER (moving first char of RowName to end)
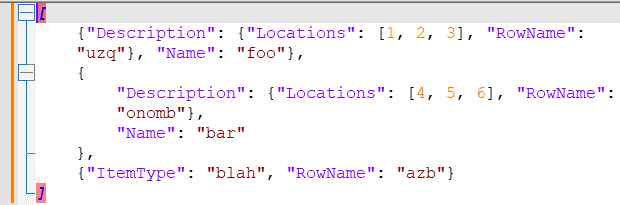
If you read the RemesPath documentation, you can learn how to use the
Rootfield on the find/replace form to restrict which fields can be edited. For example, using[:].Description.RowNameas the root will prevent you from changing the{"ItemType": "blah", "RowName": "baz"}object. -
-
Hello All,
After a holiday in
Brittany( the only French region with a temperate climate !! ) I’m back home.In the last post, @alan-kilborn said :
@guy038 said in Regex use:
This file, that I called Total_Chars.txt, contains a definitive list of 325,590 possible characters
Seems worthy to publish this?
So, I created an archive
Unicode.zip, which you can download from :https://drive.google.com/file/d/1kYtbIGPRLdypY7hNMI-vAJXoE7ilRMOC/view?usp=sharing
It contains all the explanations to handle the
Total_Chars.txtandLastResort-Regular.ttffiles !Best Regards,
guy038
-
Thank you @guy038 though I’m confused as to how we got from a beginner question about regular expressions into all of Unicode in single file. Somewhere in there I see the topic drifted into character encoding as code units and
\Cbut not code points and\X. Your chart was handy as it lists Notepad++ style regexp for surrogate pairs for the blocks in the extended planes. -
Hello, @mkupper and All,
@mkupper, thank you for your appreciation !
First, I would say that the
\Cand\Xsyntaxes are far from noob regex syntaxes !-
The
\Csyntax, as said in my previous post, should detect individual bytes of anUTF-8file but, actually, returns the currentNON-EOFcharacter just like the well-known(?-s).syntax -
The
\Xsyntax matches :-
Any single Non-diacritic character
-
0 or moreassociated diacritic characters, following the Non-diacritic char
-
For instance, the regex
--o\x{0306}\x{0320}\x{0340}--o\x{0318}\x{0346}\x{0305}--would exactly match the 14-chars string--ŏ̠̀--o̘͆̅--and could be replaced by the regex--\X--\X--. Just enlarge the characters to their maximum for good readability ! However, note that the simple 8-chars string--------would also be matched by the--\X--\X--regex !
Secondly, I must admit that talking about Unicode characters, in a general way, made me drift towards my
Total_Chars.txtfile discussion !But, even if we use the previous THEORICAL syntax, against the
Total_Chars.txtfile :(?xs) ( (?| (?= [\x{0000}-\x{007F}] ) (\C) ( ) ( ) ( ) | # 128 1-byte chars in part INSIDE the BMP | (?= [\x{0080}-\x{07FF}] ) (\C) (\C) ( ) ( ) | # 1,920 2-byte chars , in part INSIDE the BMP | 63,454 chars (?= [\x{0800}-\x{FFFF}] ) (\C) (\C) (\C) ( ) | # 61,406 3-byte chars , in part INSIDE the BMP | (?= [\x{10000}-\x{1FFFFF}] ) (\C) (\C) (\C) (\C) # 262,136 4-byte chars , in part OUTSIDE the BMP, with code > \x{FFFF} ( = 4 × 65,534 ) ) )We could NOT find any result for two reasons :
-
The
\Cregex does not work with our presentBoostregex engine ( See above ) -
The characters over
\x{FFFF}are not properly handled by theBoostregex engine
So the last line
(?= [\x{10000}-\x{1FFFFF}] ) (\C) (\C) (\C) (\C), regarding characters outside the BMP, should be changed as(?s).[\x{D800}-\x{DFFF}]Using this regex, against the
Total_Charsfile, in the Find dialog, with theWrap aroundbutton checked, does return262,136characters, when you click on theCountbuttonYou may also convert this regex in a range delimited by two
surrogate pairsas character boundaries-
Open the Mark dialog (
Ctrl + M) -
Untick all box options
-
Enter the regex
\x{D800}\x{DC00}.+\x{DB7F}\x{DFFD}( first char ofPlane 1to last allowed char ofPlane 14) -
Tick the
Purge for each searchandWrap aroundoptions -
Select the
Regular expressionsearch mode -
Click on the
Mark Allbutton (1hit ) -
Click on the
Copy Marked Textbutton -
Open a new file (
Ctrl + N) -
Paste the contents of the clipboard
Again, using the
(?s).[\x{D800}-\x{DFFF}]regex on the entire file or a simpleCtrl + Agives a count of262,136characters for this new file !
Thirdly, I would like to insist on the fact that, both, the
LastResort-Regular.ttffont and theTotal_Charstext file deal only with characters and NOT with the individual bytes of these chars, depending of their current encoding !So, in a sense, it’s not connected to the beginning of my initial post, regarding individual bytes. Sorry for the confusion !
Best Regards,
guy038
-
-
M mkupper referenced this topic on
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login