Select/Export certain text that appears above a different set of certain text - Two separate find queries
-
Good morning all,
I have a large text file that contains thousands of elements of data. Each element contains different data but is structured the same way in the file. Some of these elements have a piece of text that indicates it is an element I want to make a note of.For example, my simplified file looks like this:
Product Name="name1" textfield1="randomtext" etc... { ...lots of random text ... randomtext { text="randomtext.TRIGGER':=1" } ... ... } Product Name="name2" textfield1="randomtext" etc... { ...lots of random text ... ... ... ... } Product Name="name3" textfield1="randomtext" etc... { ...lots of random text ... ... ... ... } Product Name="name4" textfield1="randomtext" etc... { ...lots of random text ... randomtext { text="randomtext.TRIGGER':=1" } ... ... } Product Name="name5" textfield1="randomtext" etc... { ...lots of random text ... ... ... ... } Product Name="name6" textfield1="randomtext" etc... { ...lots of random text ... randomtext { text="randomtext.TRIGGER':=1" } ... ... }If I was doing this manually, I would search for the text: “.TRIGGER’:=1”. Then I would perform another search, searching backwards, for the text “PRODUCT NAME=”. I would then see that the first instance is “name1” and I would copy that name to a new file.
I found a thread where an expression almost sorta does what I’m hoping to do.
(I’m not allowed to post links but the topic url is: /21308/how-to-find-and-select-all-words-between-select-words/7)
Specifically the comment by guy038 where the Mark dialog is used alongside the purge option.Using the expression (?s)(?<=Product Name=)(.+?)(?=.TRIGGER’:=1)
This highlights the first element from “name1” through to the .TRIGGER text. Excellent! Even though all I want is “name1”, just having this larger section highlighted means I can easily extract all the "nameX"s in a separate file. Unfortunately, it highlights from “name2” all the way through to the next instance of .TRIGGER which doesn’t occur until element “name4”.What I’d really like to do is somehow extract JUST the “nameX” of whatever element the .TRIGGER text is located within, but I don’t know if it’s possible to be so nuanced with this type of search. Alternatively, selecting all the text between the Product Name and the .TRIGGER is fine and I can work with this larger amount of data if I could somehow only extract JUST the elements that have this .TRIGGER within it.
Not to belabor the point, but if possible, I’d like to have somehow been able to select the following element’s names: “name1”, “name4”, and “name6”.
-–
moderator linkified link for you -
(?s)(?<=Product Name=)(.+?)(?=.TRIGGER':=1)That comes close. You can limit the
.from(.+?)to only match a character if it isn’t the first character in the nextProduct Namelike this:(?s)(?<=Product Name=)((?:(?!=Product Name).)+?)(?=.TRIGGER':=1)If you really just want the name though, and not the rest, then put the stuff after the name in a lookahead instead of part of the match, and use another
(?:(?!=Product name).)token in between the quotes:(?s)(?<=Product Name=")(?:(?!Product Name).)*?(?="((?:(?!Product Name).)+?)(?=.TRIGGER':=1))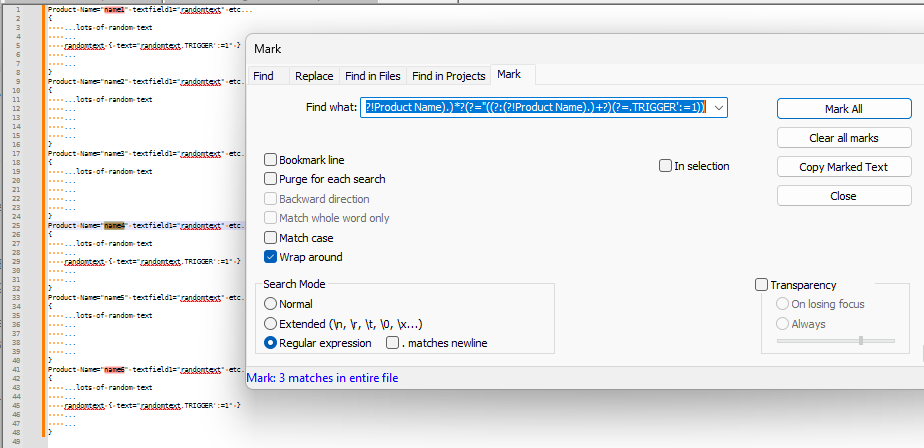
If you want the quotes as part of the match, then move them out of the parentheses:
(?s)(?<=Product Name=)"(?:(?!Product Name).)*?"(?=((?:(?!Product Name).)+?)(?=.TRIGGER':=1))BTW: thank you for putting your example text in the
</>plain-text/code box, and showing the regex you already tried.-—
Useful References
-
@PeterJones said in Select/Export certain text that appears above a different set of certain text - Two separate find queries:
(?s)(?<=Product Name=“)(?:(?!Product Name).)*?(?=”((?:(?!Product Name).)+?)(?=.TRIGGER’:=1))
This works beautifully! Thank you for such a clean method of extraction. Unfortunately, I think I might be running into a memory or overload issue?
I applied the expression to my large file and it is able to mark a handful of element names at which point the Mark utility generates the following error: “Find: Invalid Regular Expression”.
I thought at first that something in the element data was throwing the search off but I eventually pared the file down to where it only contained one element. This element did NOT have the “TRIGGER” pattern in it. When I ran the regex against it I received the error mentioned above. So I cut out about half of the interior data of this element and ran the regex again. I had a successful mark in which it reported that there were “Mark: 0 matches in entire file”. I then began pasting the interior data back in, running the Mark utility each time. I got to a point where adding 5 lines of data, regardless of what that data is, caused the Mark utility to fail.
So, if I have an element which is 1071 lines and 25,617 length the expression will evaluate properly. Adding 5 lines of text bringing the file to 1075 lines and 25,724 length, the expression fails. Those 5 lines of text are not the problem as I even copy/pasted data that was originally in the 1071 file and used that as my extra data and the expression still failed.
Is this a problem I can resolve by using a more powerful computer or is there some sort of maximum dataset size that I’m running into?
-
Can you show a screenshot of the complete Find window when it gives you the error?
-
@Alan-Kilborn
Here is the screenshot of the Mark utility showing the error in the bottom status area: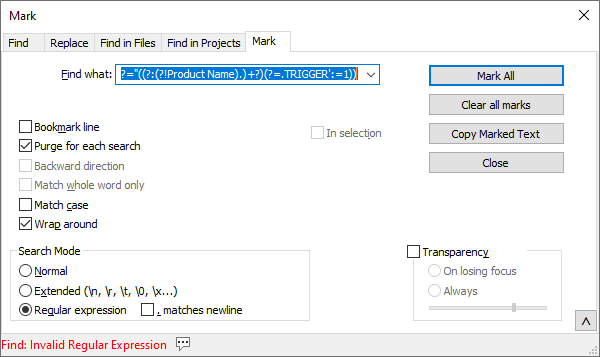
-
Yea…so point the mouse at the little speech bubble with the
...in it, and see what it says when a popup appears. The regular expression isn’t necessarily “invalid”, but more than likely is that the engine ran out of memory, or detected that complexity was increasing such that it would… -
This is tricky to reproduce but here’s how you can see the same behavior. Create a blank text file with the following text:
Product Name="name1" Style="name/type" Cat="name/type" { }Within the curly braces, paste the following text:
Attribute Name="name/type" { Val { Val=20 } Val_Mod=T Def_Val=F }If you paste this 314 times, you’ll have a total file size of 1887 lines and the expression will work properly. However, if you paste it one more time, giving you 315 elements with a total line count of 1892, the expression will fail.
I’ve noted it’s not necessarily the file line size or the total number of characters. If the Attribute subelement has more complicated data within it, I’ll end up with less than 314 elements before the expression fails.
-
@Alan-Kilborn said in Select/Export certain text that appears above a different set of certain text - Two separate find queries:
Yea…so point the mouse at the little speech bubble with the
...in it, and see what it says when a popup appears.Wow, I had tried clicking on that speech bubble earlier and nothing happened. I clearly didn’t have the patience to just hover my mouse for a fraction of a second. Sorry about that!
Here’s the full error message:
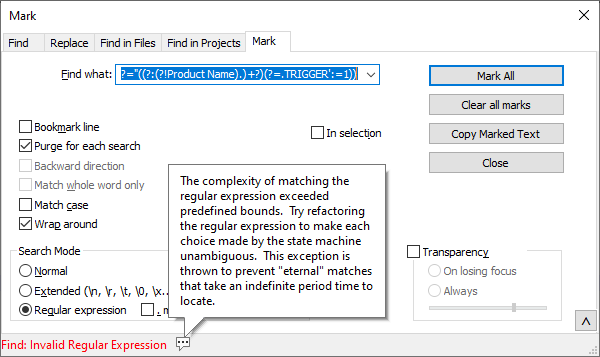
-
I think it all makes sense now.
Pretty much your only choice is to work on your expression to make it so such a condition isn’t entered.
That may or may not be possible. -
My suggestion: If every
Product Name ... { }ends with a}by itself on a line, change the instances of(?:(?!Product Name).)in the expression into(?:(?!^}).), which will stop each section with}at the beginning of a line, instead of stopping at the next Product Name. If there’s actually whitespace before the}, then use(?:(?!^\h*}).). As long as the number of characters fromProduct Nameto}isn’t ever too huge, it should be able to handle the complexity. (If you have a megabyte of data within each record, that probably won’t work; but a few dozen lines shouldn’t be a problem, and probably not even a problem on a few hundred lines) -
@StormyCalories said in Select/Export certain text that appears above a different set of certain text - Two separate find queries:
Is this a problem I can resolve by using a more powerful computer or is there some sort of maximum dataset size that I’m running into?
No promises (I’m at the edge of my knowledge), but this might work:
(?s)(?<=Product Name=")\w++(?=.*?(\.TRIGGER':=1|Product Name=(*THEN)(*FAIL))) -
@PeterJones said in Select/Export certain text that appears above a different set of certain text - Two separate find queries:
As long as the number of characters from Product Name to } isn’t ever too huge, it should be able to handle the complexity. (If you have a megabyte of data within each record, that probably won’t work; but a few dozen lines shouldn’t be a problem, and probably not even a problem on a few hundred lines)
I see. That might be my biggest problem then. Each element can have upwards of 15,000 lines and half a million characters. Does this large of potential datasets scratch the whole idea of parsing the file with Notepad++?
edit: I should add, the full file I’m working against can be about a half gig. Obviously, I have no problem splitting the file into multiple different smaller pieces, but the data within will still be very large and complex elements.
-
@Coises said in Select/Export certain text that appears above a different set of certain text - Two separate find queries:
No promises (I’m at the edge of my knowledge), but this might work:
(?s)(?<=Product Name=")\w++(?=.*?(.TRIGGER’:=1|Product Name=(*THEN)(*FAIL)))
This actually seemed to solve the problem of having too much data within the element. I was able to successfully run this expression even on a file that had failed on the original expression in this thread. It’s still not working on the full file that I have and I’m still trying to track down why that might be. I’ve been able to see that if there are 10’s of thousands of lines of elements between two positive elements, it seems to fail. I’m attempting to figure out how much it can parse before breaking.
edit: This seems to break whenever the total file line size is greater than 165k lines or so.
-
@StormyCalories said in Select/Export certain text that appears above a different set of certain text - Two separate find queries:
I’ve been able to see that if there are 10’s of thousands of lines of elements between two positive elements, it seems to fail. I’m attempting to figure out how much it can parse before breaking.
Perhaps you could first use something like:
Find what :
(?-s)^.*?(\R|(\.TRIGGER':=1|Product Name=)(*THEN)(*FAIL))
Replace with : (leave empty)on a copy of your file to remove all the lines that don’t affect the search.
-
That is a really intriguing idea. So simple and I would never have considered it.
I shall report back. Thank you!
-
@StormyCalories said in Select/Export certain text that appears above a different set of certain text - Two separate find queries:
That is a really intriguing idea. So simple and I would never have considered it.
Perhaps even better:
Find what :
^.*?((Product Name=|\.TRIGGER':=1)|\R|\z)
Replace with :$2 -
@Coises
Well it took 35 minutes for my PC to chug through with the search/replace but after it finally finished, all the expressions by everyone above works against the data.Thank all of you so much!
-
Hello, @stormycalories, @peterjones, @alan-kilborn, @Coises and all,
Yeah, interesting topic !
First, I would simplified the @peterjones’s regex :
- SEARCH
(?s)(?<=Product Name=")(?:(?!Product Name).)*?(?="((?:(?!Product Name).)+?)(?=.TRIGGER':=1))
As :
- SEARCH
(?xs) (?<= Product[ ]Name=" ) \w+ (?= " ( (?! Product[ ]Name ). )+? \. TRIGGER':=1 .+? \} )
Because the whole regex would search for some
wordchars only, instead of standard chars
Now, @coises, your use of backtracking control verbs, in the below regex, is quite clever !
- SEARCH
(?s)(?<=Product Name=")\w++(?=.*?(\.TRIGGER':=1|Product Name=(*THEN)(*FAIL)))
I personally get used to follow this method :
https://www.rexegg.com/backtracking-control-verbs.html#skipfail
As it is said, the generic regex
<.....(*SKIP)(*FAIL)|.....>syntax just means<What we DON'T want | What we DO want>!In this example, this end up to :
- SEARCH
(?xs) (?<= Product[ ]Name=" ) \w+ (?= .*? ( Product[ ]Name= (*SKIP) (*FAIL) | \. TRIGGER':=1 ) )
In the same way, @coises, I would change your regex S/R, which deletes any line which does NOT contain the
Product NameNOR the.TRIGGER':=1strings :-
SEARCH
(?-s)^.*?(\R|(\.TRIGGER':=1|Product Name=)(*THEN)(*FAIL)) -
REPLACE
Leave EMPTY
by this one :
-
SEARCH
(?x-is) ^ .* (?: Product[ ]Name= | \.TRIGGER':=1 ) (*SKIP) (*F) | ^ .* \R -
REPLACE
Leave EMPTY
Which could be expressed as :
-
IF, from beginning of current line, it is followed, further on, by, either, the
Product Name=or the.TRIGGER':=1strings, we DO NOT want to delete the currrent line -
ELSE, we DO want to delete the current line
Finally, I admit that your final try, for the same purpose :
-
SEARCH
(?-s)^.*?((Product Name=|\.TRIGGER':=1)|\R|\z) -
REPLACE
$2
seems the best one !
I also thought of this equivalent syntax :
-
SEARCH
(?x-s) ^ (?! .* (?: Product[ ]Name= | \. TRIGGER':=1 ) ) .* \R -
REPLACE
Leave EMPTY
Where the search comes from
(?x-s) ^ (?! (?: .* Product[ ]Name= | .* \. TRIGGER':=1 ) ) .* \R
Note that the regex part :
(?! (?: .* Product[ ]Name= | .* \. TRIGGER':=1 ) ) ------------------ ----------------- A BMeans, in a logical way :
NOT ( ( .* Product Name= OR .* .TRIGGER':=1 ) ) ---------------- --------------- A Bwhich, in turn, can be expressed as :
NOT ( .* Product Name= ) AND NOT ( .* .TRIGGER':=1 ) ---------------- --------------- A BThus, meaning :
Consider all the current line and its
EOLchars, which do NOT contain theProduct Name=NOR the.TRIGGER':=1strings, and delete it !Best Regards,
guy038
- SEARCH
-
@guy038 said in Select/Export certain text that appears above a different set of certain text - Two separate find queries:
https://www.rexegg.com/backtracking-control-verbs.html#skipfail
That entire page is very useful. Thanks!
I was reading the Boost regex documentation to which Notepad++ documentation links and experimenting, trying to figure out what those terse descriptions meant. I was sure there should be a way to reduce the matching complexity with verbs, but I didn’t really know how they work.
(*SKIP)(*FAIL) is clearly the better choice for this case.
-
Hello, @coises and All,
You may, also, refer to this topic, that I wrote after that a new version of the
Boostregex library comes out and was available within Notepad++ :BR
guy038
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login