Baffled by \R vs \r\n in Find: expression?
-
Not getting expected results using \R in FIND expression, whereas \r\n appears to work. Why? It was a GUESS to use \r\n instead of \R because of the CR in results of Find 1:?
Find 1: ^(-\h)?([A-Z][A-Za-z0-9 \.,'&#-?!][^:]+)\R(- )?([A-Z][A-Zc0-9 \.,'&#-?!]+):(.*)$ Find 2: ^(-\h)?([A-Z][A-Za-z0-9 \.,'&#-?!][^:]+)\r\n(- )?(.*)\:(.*)$ Rplce: $2, $4:$5 - Gotta go! - TOM: That's fine. - BERNIE: The speed these bikes go. - RENE: Honestly. After Find 1: Gotta go! , TOM: That's fine. After Find 2: Gotta go!, TOM: That's fine.Basic concept is to remove the hyphens an create SINGLE LINE results on the FIRST set of hyphens. Not the SECOND set. The (-\h)? is required in case one or both of the hyphens don’t exist.
Still a noob, if you see improvements in my expressions that would be greatly appreciated.Thanks in advance, Hank
-
@Hank-K ,
After the second FIND/REPLACE, what you actually have is
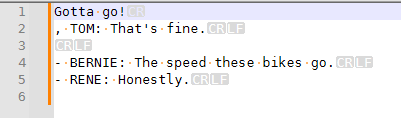
Notice that there’s a CR but not a LF there.That’s because of the
[^:]+. If you have[^:]+\R, then it will greedily match through theCRthrough the class, then\Rwill match just theLF. If you make it non-greedy with[^:]+?, then it won’t steal part of theCRLF.Thus,
^(-\h)?([A-Z][A-Za-z0-9 \.,'&#-?!][^:]+?)\R(- )?(.*)\:(.*)$on your original data gives:
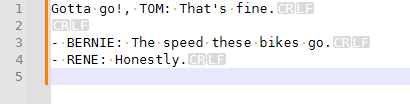
View > Show Symbol > Show End of Line is your friend when debugging newlines not behaving as expected.
-
@PeterJones
I’m still a little fuzzy on the ? or +?I have it in the beginning of my cheat sheet:
. any character (but newline) * previous character or group, repeated 0 or more time + previous character or group, repeated 1 or more time ? previous character or group, repeated 0 or 1 time ^ start of line $ end of lineSo should I always use +? instead of just + by itself?
I did use the Show All Characters on the text b4 using the expression. Didn’t think to use it on the results, an I still would have been puzzled by it.
Thanks Peter for the enlightenment, but it’s. cloudy here today, but only in my head … lol
-
If you haven’t already, you should read the USER MANUAL section on Regular Expressions, as well as the FAQ on same.
But to more specifically address your concerns:
still a little fuzzy on the ? or +?
I have it in the beginning of my cheat sheet?has a dual meaning in regex! :- when it occurs directly after a
*or a+, it means to match minimally (i.e., with as little as possible)…without the?following,*/+will match maximally (with as much as possible) - when it occurs NOT after a
*/+, it means to match what occurs to the left of it zero or one times (this is what you have in your “cheat sheet”)
Note: I say “minimally” here but that is equivalent to saying “non-greedy” or “non-greedily” per Peter. Same for “maximally” being called “greedy” or “greedily”. Sometimes you’ll see “greedy” referred to as “maximum munch” or “maximum munch mode”.
Anyway, quite different meanings for
?(obviously depends upon context of usage).
Thus, your “cheat sheet” needs to be amended with more information!To hammer home the difference between non-greedy and greedy modes, check out this (slightly changed) example from the user manual: "
m.*?oapplied to the textmargin-bottomwill matchmargin-bo, whereasm.*owill matchmargin-botto."The
.*?usage makes processing stop as soon as thefirstois seen; the.*usage keeps “munching” characters until the finalois seen.should I always use +? instead of just + by itself?
There is no “always” rule here… it depends upon what you’re trying to accomplish. Sometimes you’ll want
+and sometimes you’ll want+?.Peter had said:
That’s because of the
[^:]+. If you have[^:]+\R, then it will greedily match through theCRthrough the class, then\Rwill match just theLF. If you make it non-greedy with[^:]+?, then it won’t steal part of the CRLF.Here, it’s even trickier!
The regex processing wants to please you. It wants to give you a match. So, at certain points, it will “compromise” in order to give you what you want (a match). Because
\Rcan be thought of as\ror\nindividually, in your[^:]+\R, the processing sees that it can make you happy (with a match), by considering the last matching character of[^:]+as\rand letting the\Rmatch only the\n. This doesn’t make you happy, though. :-)
I did use the Show All Characters on the text b4 using the expression. Didn’t think to use it on the results, an I still would have been puzzled by it.
So what you want to see, after you’ve transformed text with a replacement, is consistent line-endings. For your case, you want to see CRLF at the end of every line. If you see only CR or only LF, then your regex is bad and you have likely corrupted your file. “Corruption” is a strong word, it is going to depend on what you are doing with your file next, i.e., are you feeding it into another program that will barf if the line-endings aren’t correct…?).
- when it occurs directly after a
-
I’ve run across that “Corruption” previously, kind of why I started using \R instead of \r\n. I have read the manual some is very clear, but some of it still very cloudy. I come to here to clear up cloudiness… you guys are my weathermen.
While I have your attention is there a better way to this:
[A-Zc0-9 \.,'&#-?!] Regarding this part " \.,'&#-?!" using: \\p{L} Experimented with it but no joy on my end? -
@Hank-K said in Baffled by \R vs \r\n in Find: expression?:
is there a better way to this
Sorry, but I’m not sure what you’re asking here.
Maybe someone else will understand the question.Are you asking for a regex that matches
\\p{L}?? -
@Alan-Kilborn
Looking to simplify/shorten my expression by not having list all the:,.;:"'#&!-?<>characters?
Basically grab a text string with any combination of punctuation characters?
examples:
I... I'm a walking stick. Oh, never mind. Slapstick! Get it? Dot, you're flying! What are you doing here?. Long-dormant embers? -
@Hank-K said in Baffled by \R vs \r\n in Find: expression?:
Basically grab a text string with any combination of punctuation characters?
Maybe
[[:punct:]]+meets the need?
See HERE in the user manual (you really should read the Regular Expression section). -
@Hank-K ,
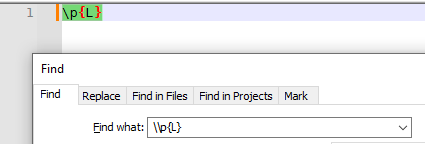
\\p{L}First, I don’t know if you intended to list two backslash or whether you were not sure if the forum would mess it up, but as described in the User Manual’s Regex character-property section, the
\p☒and\p{NAME}syntax only requires a single backslash.\\p{L}matches a literal backslash (because\\is interpreted where the first backslash escapes the second), followed by a literalp, followed by a literal capital-L-in-braces:
Because you used the braces, I assume you were trying to access the named character property (
\p{NAME}syntax). For those, if you scroll just above that section in the manual, to the table in the character classes, the “full name” column there are the named properties that\p{NAME}understands, and the “short” column are the single-character shorthands that can be used with\p☒.Note that there is no “long name” (or short) using only the capital L. However, I just ran some experiments, and confirmed that all the combinations
\pl,\pL,\p{l}, and\p{L}refer to the “short name”l, which matches lower case letters (or any letters if your search is not case sensitive).If you are trying to match punctuation, you need to use
\p{punct}to use the punctuation property, or the[[:punct:]]named character class, either of which are essentially equivalent to the manual character class[!"#$%&'()*+,\-./:;<=>?@\[\\\]^_{\|}~]– but I don’t know if that will match more punctuation than you intended.[A-Zc0-9 \.,'&#-?!]That’s rather weird, by the way. All English uppercase, lowercase c (but no other lowercase, unless your match is insensitive, in which case all lowercase will also match), the digits, space, period, comma, single-quote, ampersand, all characters from
#through?(which includes dollar, percent, ampersand, most of the other punctuation, and the digits) and the exclamation point. That repeats a lot of the characters. If you want-to be the literal hyphen in a character class, it needs to be either the first or last character (as explained in one of the earliest points in the character-class section of the manual).If you’re really trying to match “just basic ASCII characters”, I would say
[\x20-\x7E]– which, since it excludes the control characters, will skip tab and newline, but match anything else in non-accented US-English. But that’s rather US-centric. It’s not impossible, even in US caption files, for there to be foreign words, or English-plus-accents (résumé/resumé/resume,coöperate, and the like). And with how permissive yours is, are you really trying to say “I want to match anything except newlines and other vertical spaces”? Because if so,\Vmight be what you really want. Or, for that matter,.when. matches newlineis not checkmarked (since I doubt your caption file has any of the fancy vertical spaces that aren’t CRLF newline characters). -
@PeterJones
Thanks for the GREAT explanation, will read manual again and experiment.
You and Alan have a GREAT DAY !!
Cheers, Hank
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login