Unicode 'ÿ' , problem converting to Hex 'FF'
-
If NULs are involved, I would kick the problem over to VSCode, which does not have such issues with NULs.
-
@Mark-Olson said :
I would kick the problem over to VSCode, which does not have such issues with NULs
There really is nothing intrinsically wrong with a text editor supporting NULs in documents, and, if VSCode indeed supports this, then bully for it. It was designed in “modern times”.
Notepad++ is bound by a 20+ year old legacy, when null characters were (only) used to terminate C-strings. They are still used as C-string terminators, just not in such a “willy nilly” application as the “olden days”, when the coders were aghast at the possibility of a null character in a document (and thus made compromises based upon this).
I think Notepad++ will get better with this as time continues to march on, but it is going to be slow in happening. Best thing to do is not to do anything in Notepad++ with files that need/have these characters.
-
@Mark-Olson said in Unicode 'ÿ' , problem converting to Hex 'FF':
If NULs are involved, I would kick the problem over to VSCode, which does not have such issues with NULs.
Notepad++ and Scintilla support NULs within text files. The problems are in the details such as plugins. As Windows does not support NULs within text strings you can’t copy/paste strings containing NULs to or from any editor.
-
@mkupper said in Unicode 'ÿ' , problem converting to Hex 'FF':
Notepad++ and Scintilla support NULs within text files.
Not fully (as I was trying to say in my previous post).
Anytime some text data is pulled into a C-string for processing, NUL bytes in that data is going to cause a problem, because it will look like the end-of-text right at the NUL byte, instead of the full length.
There are MANY examples of this in the Notepad++ source.
A very recent example (yesterday) of a user-reported problem of this nature is HERE. -
@Alan-Kilborn said in Unicode 'ÿ' , problem converting to Hex 'FF':
Not fully (as I was trying to say in my previous post).
Anytime some text data is pulled into a C-string for processing, NUL bytes in that data is going to cause a problem, because it will look like the end-of-text right at the NUL byte, instead of the full length.
There are MANY examples of this in the Notepad++ source.
A very recent example (yesterday) of a user-reported problem of this nature is HERE .Thank you - I see that one is a big issue. I did some testing.
- The convert case functions are ok.
- Splitting and joining lines are ok.
Besides sorting, these Notepad++ operations have issues:
- The reverse and randomize line order functions truncate the selection at the NUL.
- Remove Duplicate lines does nothing if there are no duplicates before a NUL… If there are duplicate lines before line(s) with NULs then the file or selection gets truncated at the first NUL and then the dupe-removal happens. I guess the initial scan for dupes is truncated at the NULL and it decides to do nothing. If there are dupes then those are removed and the NUL truncated buffer is written back to Scintilla.
I discovered that the Edit / Line Operations / Paste Special / copy and paste binary content work for text data containing NULs. That’s useful to keep in mind testing this sort of stuff.
-
Hi, @lancemarchetti, @mark-olson, @alan-kilborn, @rdipardo and All,
In my previous post, I said :
- Firstly, the important thing to note is that any character over the BMP, so with code char
> x{FFFF}, is strictly forbidden in files encoded with theUCS-2 BE BOMor theUCS-2 LE BOMencoding !
This assumption is true but, in a N++ point of vue, is not accurate anymore because, since the
v8.0version of N++, these encodings have been improved to the two new encodingsUTF-16 BE BOMandUTF-16 LE BOMAnd, indeed, these new encodings do support characters over the
BMP! Note that all the characters over theBMPare encoded with their surrogate representation, containing two16-bytescode units. For instance the Unicode char\x{1F4A6}is, therefore, encoded with its surrogate representation\x{D83D}\x{DCA6}
It’s important to point out that, within N++, you CANNOT search the character
\x{1F4A6}itself but you can search it via its surrogate representation which is\x{D83D}\x{DCA6}BTW, if someone is interessed, I created a macro which does the translation
\x{[#]#####}to its corresponding surrogate pair\x{####}\x{####}, for any character over theBMP, between\x{10000}and\x{10FFFF}, of the current selection !
So, as an example :
- For a file containing ONLY the over
BMPchar SPLASHING SWEAT SYMBOL :💦, of Unicode valueU + 1F4A6, theUTF-16 BE BOMencoded file would contain the bytes :
FE FF D8 3D DC A6( So, theBOMand the char, with the MSB byte first, and then, the LSB byte )- For a file containing ONLY the over
BMPchar “SPLASHING SWEAT SYMBOL” :💦, of Unicode valueU + 1F4A6, theUTF-16 LE BOMencoded file would contain the bytes :
FF FE 3D D8 A6 DC( So theBOMand the char, with the LSB byte first, and then, the MSB byte )Best Regards,
guy038
- Firstly, the important thing to note is that any character over the BMP, so with code char
-
@mkupper said in Unicode 'ÿ' , problem converting to Hex 'FF':
these Notepad++ operations have issues
The list is endless (well, it IS finite, but perhaps doesn’t seem like it). :-)
HERE is another interesting one. -
@guy038 said in Unicode 'ÿ' , problem converting to Hex 'FF':
if someone is interessed, I created a macro which does the translation
I suppose the interest might be small, but why not post the macro?
-
@PeterJones Thanks Peter. I will try my best to figure it out. I’m currently 55 and have zero programming background, but find computers and binary fascinating.
Just to recap, I will try to keep this a short and as comprehensive as possible.
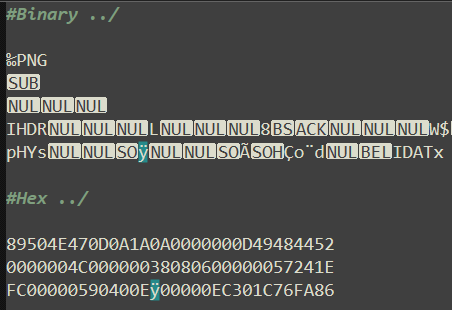
Example Of The ASCII to HEX Issue I am Currently Experiencing in NP++:Encoding=UTF-8
StringDataType=Image/Binary
TotalBytes=10UseCase: The manual editing of the dimensions sector in the image binary allows for the creation of CTF challenges. Manual BOM manipulation allows for forced cropping and the concealment of color-data in the rest of the image. It can also be used to create pixelated patterns for unraveling. Notepad++ has met all these requirements for me so far. So I am pretty impressed at what I can get away with in various image formats.
THIS EXAMPLE :
Binary: GIF89a NUL NUL
ASCII -> Hex: GIF89a20002000
Bytes: 1-6 , Header
Bytes: 7-10 , Dimensions
The above ASCII to Hex conversion is 100% correct and was performed using the ASCII->Hex converter Ver4.3 by Don Ho which utilizes NppConverter.dll
However this converter does not convert ‘ÿ’ to ‘FF’ for some reason. I therefore requested help on the Notepad++ forum and a py script was suggested to help with the ‘ÿ’ to ‘FF’ issue. The script worked successfully, but unfortunately landed up converting NUL bytes ‘00’ to spaces ‘20’.This is not helpful due to the fact that a space in ASCII is represented by the value ‘32’ (Hex ‘20’).
So when it comes to image dimensions as in the GIF example above 20 00 20 00 , indicates a 32x32 pixel image.
NOTE: Using a space ‘20’ to replace a NUL ‘00’ will still result in a 32x32 Gif image,HOWEVER, doing this to the dimension sector of a Jpeg will result in a 32x32px becoming a 8244x8224px image! Because the Big-Endian byte order of the 4-byte dimension block in Jpeg will translate 20202020 as 8244x8244 instead of 32x32 as in the case with GIF.
This is why I need the script to correctly translate NUL bytes to ‘00’ and NOT ‘20’, otherwise it will create outrageous dimensions in formats like Jpeg, Webp and PNG.
If NppConverter.dll is actually doing it right, then why can we not replicate it in Python?Thanks once again.
Lance Marchetti

-
@Mark-Olson I did not know that about VSCode, thanks, Ill look into it. Mark.
-
Hello, @alan_kilborn and All,
So, here is the contents of this macro :
<Macro name="Surrogates Pairs in Selection" Ctrl="no" Alt="no" Shift="no" Key="0"> <Action type="3" message="1700" wParam="0" lParam="0" sParam="" /> <Action type="3" message="1601" wParam="0" lParam="0" sParam="(?-i)\\x\{(10|[[:xdigit:]])[[:xdigit:]]{4}" /> <Action type="3" message="1625" wParam="0" lParam="2" sParam="" /> <Action type="3" message="1602" wParam="0" lParam="0" sParam="$0\x1F" /> <Action type="3" message="1702" wParam="0" lParam="640" sParam="" /> <Action type="3" message="1701" wParam="0" lParam="1609" sParam="" /> <Action type="3" message="1700" wParam="0" lParam="0" sParam="" /> <Action type="3" message="1601" wParam="0" lParam="0" sParam="(?i)(?:(1)|(2)|(3)|(4)|(5)|(6)|(7)|(8)|(9)|(A)|(B)|(C)|(D)|(E)|(F)|(10))(?=[[:xdigit:]]{4}\x1F\})|(?:(0)|(1)|(2)|(3)|(4)|(5)|(6)|(7)|(8)|(9)|(A)|(B)|(C)|(D)|(E)|(F))(?=[[:xdigit:]]{0,3}\x1F\})" /> <Action type="3" message="1625" wParam="0" lParam="2" sParam="" /> <Action type="3" message="1602" wParam="0" lParam="0" sParam="(?{1}0000)(?{2}0001)(?{3}0010)(?{4}0011)(?{5}0100)(?{6}0101)(?{7}0110)(?{8}0111)(?{9}1000)(?{10}1001)(?{11}1010)(?{12}1011)(?{13}1100)(?{14}1101)(?{15}1110)(?{16}1111)(?{17}0000)(?{18}0001)(?{19}0010)(?{20}0011)(?{21}0100)(?{22}0101)(?{23}0110)(?{24}0111)(?{25}1000)(?{26}1001)(?{27}1010)(?{28}1011)(?{29}1100)(?{30}1101)(?{31}1110)(?{32}1111)" /> <Action type="3" message="1702" wParam="0" lParam="640" sParam="" /> <Action type="3" message="1701" wParam="0" lParam="1609" sParam="" /> <Action type="3" message="1700" wParam="0" lParam="0" sParam="" /> <Action type="3" message="1601" wParam="0" lParam="0" sParam="([01]{10})([01]{10})(?=\x1F)" /> <Action type="3" message="1625" wParam="0" lParam="2" sParam="" /> <Action type="3" message="1602" wParam="0" lParam="0" sParam="110110\1\x1F}\\x{110111\2" /> <Action type="3" message="1702" wParam="0" lParam="640" sParam="" /> <Action type="3" message="1701" wParam="0" lParam="1609" sParam="" /> <Action type="3" message="1700" wParam="0" lParam="0" sParam="" /> <Action type="3" message="1601" wParam="0" lParam="0" sParam="(?:(0000)|(0001)|(0010)|(0011)|(0100)|(0101)|(0110)|(0111)|(1000)|(1001)|(1010)|(1011)|(1100)|(1101)|(1110)|(1111))(?=[[:xdigit:]]*\x1F\})|\x1F" /> <Action type="3" message="1625" wParam="0" lParam="2" sParam="" /> <Action type="3" message="1602" wParam="0" lParam="0" sParam="(?{1}0)(?{2}1)(?{3}2)(?{4}3)(?{5}4)(?{6}5)(?{7}6)(?{8}7)(?{9}8)(?{10}9)(?11A)(?12B)(?13C)(?14D)(?15E)(?16F)" /> <Action type="3" message="1702" wParam="0" lParam="640" sParam="" /> <Action type="3" message="1701" wParam="0" lParam="1609" sParam="" /> </Macro>
How this macro works :
-
You select a true Unicode value of a character over the
BMP:\x{#####}or\x{######}, with5or6hexadecimal digits -
You run the macro
-
You get its surrogate pair :
\x{####}\x{####}
Note that your normal selection can encompass several
\x{#####}syntaxes in one go. For example, after selection of the text, below and execution of the macro :\x{10000} is the FIRST char over the BMP This SECOND char \x{14A9B} is concerned by this macro, too A THIRD char \x{14A9D}, very closed to the PREVIOUS one A FOURTH example, at the VERY END of the UNICODE range = \x{10FFFF}This text will be changed as :
\x{D800}\x{DC00} is the FIRST char over the BMP This SECOND char \x{D812}\x{DE9B} is concerned by this macro, too A THIRD char \x{D812}\x{DE9D}, very closed to the PREVIOUS one A FOURTH example, at the VERY END of the UNICODE range = \x{DBFF}\x{DFFF}
Now, Alan, I will concede that, for a single char, this macro is not very useful as you can, instead, just select this character over the `BMP, open the search dialog and search for all occurrences of this specific character !
But, let’s suppose you would scan your files for those containing, let’s say, the Unicode Emoticons range of chars, which lays between the
\x{1F600}and the\x{1F64F}characters. Refer to :http://www.unicode.org/charts/PDF/U1F600.pdf
And which is reported, below :
😀 \x{1F600} = \x{D83D}\x{DE00}
😁 \x{1F601} = \x{D83D}\x{DE01}
😂 \x{1F602} = \x{D83D}\x{DE02}
😃 \x{1F603} = \x{D83D}\x{DE03}
😄 \x{1F604} = \x{D83D}\x{DE04}
😅 \x{1F605} = \x{D83D}\x{DE05}
😆 \x{1F606} = \x{D83D}\x{DE06}
😇 \x{1F607} = \x{D83D}\x{DE07}
😈 \x{1F608} = \x{D83D}\x{DE08}
😉 \x{1F609} = \x{D83D}\x{DE09}
😊 \x{1F60A} = \x{D83D}\x{DE0A}
😋 \x{1F60B} = \x{D83D}\x{DE0B}
😌 \x{1F60C} = \x{D83D}\x{DE0C}
😍 \x{1F60D} = \x{D83D}\x{DE0D}
😎 \x{1F60E} = \x{D83D}\x{DE0E}
😏 \x{1F60F} = \x{D83D}\x{DE0F}
😐 \x{1F610} = \x{D83D}\x{DE10}
😑 \x{1F611} = \x{D83D}\x{DE11}
😒 \x{1F612} = \x{D83D}\x{DE12}
😓 \x{1F613} = \x{D83D}\x{DE13}
😔 \x{1F614} = \x{D83D}\x{DE14}
😕 \x{1F615} = \x{D83D}\x{DE15}
😖 \x{1F616} = \x{D83D}\x{DE16}
😗 \x{1F617} = \x{D83D}\x{DE17}
😘 \x{1F618} = \x{D83D}\x{DE18}
😙 \x{1F619} = \x{D83D}\x{DE19}
😚 \x{1F61A} = \x{D83D}\x{DE1A}
😛 \x{1F61B} = \x{D83D}\x{DE1B}
😜 \x{1F61C} = \x{D83D}\x{DE1C}
😝 \x{1F61D} = \x{D83D}\x{DE1D}
😞 \x{1F61E} = \x{D83D}\x{DE1E}
😟 \x{1F61F} = \x{D83D}\x{DE1F}
😠 \x{1F620} = \x{D83D}\x{DE20}
😡 \x{1F621} = \x{D83D}\x{DE21}
😢 \x{1F622} = \x{D83D}\x{DE22}
😣 \x{1F623} = \x{D83D}\x{DE23}
😤 \x{1F624} = \x{D83D}\x{DE24}
😥 \x{1F625} = \x{D83D}\x{DE25}
😦 \x{1F626} = \x{D83D}\x{DE26}
😧 \x{1F627} = \x{D83D}\x{DE27}
😨 \x{1F628} = \x{D83D}\x{DE28}
😩 \x{1F629} = \x{D83D}\x{DE29}
😪 \x{1F62A} = \x{D83D}\x{DE2A}
😫 \x{1F62B} = \x{D83D}\x{DE2B}
😬 \x{1F62C} = \x{D83D}\x{DE2C}
😭 \x{1F62D} = \x{D83D}\x{DE2D}
😮 \x{1F62E} = \x{D83D}\x{DE2E}
😯 \x{1F62F} = \x{D83D}\x{DE2F}
😰 \x{1F630} = \x{D83D}\x{DE30}
😱 \x{1F631} = \x{D83D}\x{DE31}
😲 \x{1F632} = \x{D83D}\x{DE32}
😳 \x{1F633} = \x{D83D}\x{DE33}
😴 \x{1F634} = \x{D83D}\x{DE34}
😵 \x{1F635} = \x{D83D}\x{DE35}
😶 \x{1F636} = \x{D83D}\x{DE36}
😷 \x{1F637} = \x{D83D}\x{DE37}
😸 \x{1F638} = \x{D83D}\x{DE38}
😹 \x{1F639} = \x{D83D}\x{DE39}
😺 \x{1F63A} = \x{D83D}\x{DE3A}
😻 \x{1F63B} = \x{D83D}\x{DE3B}
😼 \x{1F63C} = \x{D83D}\x{DE3C}
😽 \x{1F63D} = \x{D83D}\x{DE3D}
😾 \x{1F63E} = \x{D83D}\x{DE3E}
😿 \x{1F63F} = \x{D83D}\x{DE3F}
🙀 \x{1F640} = \x{D83D}\x{DE40}
🙁 \x{1F641} = \x{D83D}\x{DE41}
🙂 \x{1F642} = \x{D83D}\x{DE42}
🙃 \x{1F643} = \x{D83D}\x{DE43}
🙄 \x{1F644} = \x{D83D}\x{DE44}
🙅 \x{1F645} = \x{D83D}\x{DE45}
🙆 \x{1F646} = \x{D83D}\x{DE46}
🙇 \x{1F647} = \x{D83D}\x{DE47}
🙈 \x{1F648} = \x{D83D}\x{DE48}
🙉 \x{1F649} = \x{D83D}\x{DE49}
🙊 \x{1F64A} = \x{D83D}\x{DE4A}
🙋 \x{1F64B} = \x{D83D}\x{DE4B}
🙌 \x{1F64C} = \x{D83D}\x{DE4C}
🙍 \x{1F64D} = \x{D83D}\x{DE4D}
🙎 \x{1F64E} = \x{D83D}\x{DE4E}
🙏 \x{1F64F} = \x{D83D}\x{DE4F}In this case, knowing the first and last
surrogatevalues of the Emoticons range, which are\x{D83D}\x{DE00}and\x{D83D}\x{DE4F}, it’s easier to get the right regex to search for, which is\x{D83D}[\x{DE00}-\x{DE4F}]!
And, indeed :
-
Open a new tab
-
Paste the
80characters of the Emoticons range, with their associated value, above, in this new tab -
Open the Mark dialog (
Ctrl + M) -
Tick the
Wrap aroundbox and select theRegular expressionmode -
Enter the regex
\x{D83D}[\x{DE00}-\x{DE4F}]in the Search zone -
Click on the
Mark Allbutton
=> The
80characters, of this Unicode range, should be marked in red-orange, all at once !Best Regards,
guy038
-
-
@guy038 Wow - Thanks for this macro!
-
@LanceMarchetti said in Unicode 'ÿ' , problem converting to Hex 'FF':
“
NOTE: Using a space ‘20’ to replace a NUL ‘00’ will still result in a 32x32 Gif image,”
Correction: I just noticed that the GIF file format repeats the image dimension block later on in the binary, just before the image data begins.
So I tried using Hex 20 20 20 20 in the second dimension sector as well. The result was INDEED a 8224x8224 image!
Changing it back to 20 00 20 00 resulted in a 32x32 image.Just wanted to set that straight. Thanks.
-
I was surprised that no one had suggested submitting a bug report to the Converter Plugin repo’s issue list regarding the
ÿportion, because even though most of your request is abusing a text editor to edit a non-text file, Notepad++'s Converter Plugin should be able to handle convertingÿin a valid ANSI file (win1252 or ISO-8859-1 or similar codepage).But when I went looking through open and closed issues, I found it’s actually already been reported multiple times – most recently, in #11… and #11 even came with a fix in PR#16, which was rejected because Don didn’t have the Steps to Reproduce.
Based on this conversation, I was able to come up with a minimal Steps to Reproduce, and asked Don to re-open that issue, and hopefully he will then see whether the fix #16 will work, or will come up with one that will.
The right answer to your full query is “Notepad++ is not a binary-file editor, so you need to accept hacky suggestions”. But
ÿshould be able to be handled by the Converter plugin, so I poked theÿissue. -
I didn’t look super closely at it (due to limited interest), but I’d guess this line/block is the cause of the problem:
At least it seems suspicious. 0xFF can look a lot like -1. :-)
-
@Alan-Kilborn said in Unicode 'ÿ' , problem converting to Hex 'FF':
At least it seems suspicious. 0xFF can look a lot like -1. :-)
Given that PR#16 changed the
getCharreturn value, which is what that -1 is comparing against, I’d say you’re probably right. -
@PeterJones said in Unicode 'ÿ' , problem converting to Hex 'FF':
Given that PR#16 changed the getChar return value, which is what that -1 is comparing against, I’d say you’re probably right.
I didn’t look beyond the current code.
-
@PeterJones Thanks Peter. Appreciated. I also emailed Don last week on the ÿ issue. But have not heard back yet. So I’m grateful that you clubbed in to hopefully get it sorted.
I’m not a programmer as stated before, so i think you Guys are obviously on the right track with ‘-1’ because Mistral AI identified it also as such.
/chat.mistral.ai/chat/ec2b9a74-2da7-4bda-bfb3-e2b8681c435f/
I see that the provided code snippet is part of the Ascii to Hex plugin for Notepad++. Based on my analysis, the issue likely arises from the fact that the ‘ÿ’ character (Alt+0255) corresponds to the unsigned char value 255, which is interpreted as a negative value (-1) when stored in a signed char. The code then treats this negative value as an error and refuses to convert the whole block of highlighted text.
To fix this issue, you can modify the code to use unsigned characters instead of signed characters. Here’s an updated version of the relevant part of the code:
void ascii2hex(bool insertSpace, bool isMaj, size_t nbCharPerLine) { // ... (previous code remains unchanged) unsigned char *pDestText = new unsigned char[textLen*(inc+eolNbChar)+1]; // ... (previous code remains unchanged) const char *format = ""; int val = static_cast<unsigned char>(selText.getChar(i)); if (val == -1) { delete [] pDestText; return; } // ... (remaining code) }By changing the
pDestTexttype tounsigned charand casting the result ofselText.getChar(i)tounsigned char, the code should now properly handle the ‘ÿ’ character and convert it to ‘FF’ in hexadecimal. -
@LanceMarchetti said in Unicode 'ÿ' , problem converting to Hex 'FF':
int val = static_cast<unsigned char>(selText.getChar(i));I’m afraid this type cast will corrupt data if any character ordinal is greater than
0xFF, e.g.ġ. See, for example:selText.getCharalready returns anint, which is 32-bits wide, so more than enough for any ASCII or Unicode ordinal.The real issue is the declaration of
SelectedString::_straschar *, which limits every representable “byte” to a maximum ordinal value of0x7F. It should be the genericTCHAR *type, which becomeswchar_t *when the_UNICODEcompile-time definition is set (as it always has been ever since Notepad++ became a Unicode application about 17 years ago). Awchar_tis 16 bits, which would accommodate “extended” 8-bit ASCII as well as the East Asian double-byte character sets that remain popular with some users. -
Re: Unicode 'ÿ' – problem converting to Hex 'FF'
Wow, I can’t believe it’s been 2 years since I ran into this issue…anyway I finally figured out a working fix.
To fix the signed integer anomaly, we apply a bitwise AND mask (& 0xFF). This converts Scintilla’s negative integers back into true unsigned byte values (0 to 255) before string formatting. The entire conversion happens entirely in memory and replaces the target range in a single, atomic undo action.
How to Use:
Open a binary file, highlight the bytes you want to convert, then run the script. All ÿ and NUL bytes will successfully be converted.Cheers :)
# -*- coding: utf-8 -*- # Notepad++ PythonScript: Convert selected bytes to hex, skip 0xFF (ÿ) and 0x00 (NUL). Substite with FF and 00 on second pass. from Npp import * def main(): editor.beginUndoAction() try: start = editor.getSelectionStart() end = editor.getSelectionEnd() if start == end: return hex_parts = [] for pos in range(start, end): raw_b = editor.getCharAt(pos) b = raw_b & 0xFF # Keep the unsigned 0-255 byte conversion if b == 0xFF: # Direct conversion: No more placeholder strings needed! hex_parts.append("FF") else: # Flawless 2-digit Hex formatting for NUL (00) and other bytes hex_parts.append("%02X" % b) # Write the finalized, pure hex block directly to the document editor.setTargetStart(start) editor.setTargetEnd(end) editor.replaceTarget(''.join(hex_parts)) finally: editor.endUndoAction() if __name__ == '__main__': main()
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login