regexp to match comma(s) end of line
-
I’d slightly modify Ekopalypse’s proposed regex to
(?:\h*,+\h*)+$. It’s the same thing, except it doesn’t consume empty lines. -
@Terry-R 's solution doesn’t require a comma to be present (as needed by the OP).
@Ekopalypse 's solution can have hits that cover multiple lines, including empty lines (not wanted by the OP).
@Mark-Olson 's solution can match “other” horizontal whitespace besides a “space” (not wanted by the OP).
So… I’ll present my own solution for others to shoot holes in. :-)
\x20*,[\x20,]*$ -
@Alan-Kilborn your solution doesn’t match this case:
}", ,, , ,,meanwhile I found out that I would need to ignore (i.e match) these two cases too:
477,UpdateConsortiumControls,function,,,"UpdateConsortiumControls() { 477,UpdateConsortiumControls,function, ,"UpdateConsortiumControls() { (note the commas in the middle) -
@patrickdrd said :
your solution doesn’t match this case:
}", ,, , ,,Yes, it does, for me. But maybe you have some other context (that you haven’t been specific enough about) that causes it not to work.
I found out that I would need to match these two cases too:
You have to learn how to ask good questions.
You have been “around” this forum enough to know that.Formulate a new spec, and if people haven’t tired of this subject (and the “oh yea, need THIS now too along with THAT…”) then maybe you’ll get some responses.
-
@Alan-Kilborn no sir, it matches only the last two commas and I would like all of them,
also my job is “dynamic” , I can’t figure out what is needed beforehand all the times,
if you don’t like that, please don’t answer -
@patrickdrd said in regexp to match comma(s) end of line:
it doesn’t match them all:
In the following posts to the OP stating my solution didn’t work noone seemed to realise (or at least state as such) that it does meet the request. The OP’s image clearly shows that the first match (in light blue) has another character preceding the 2 commas which is NOT a space. A space character can clearly be seen just above at the end of the first line. It is denoted (in regex101.com) as a thick dot hanging mid level on the line. See my amended image showing the differences.
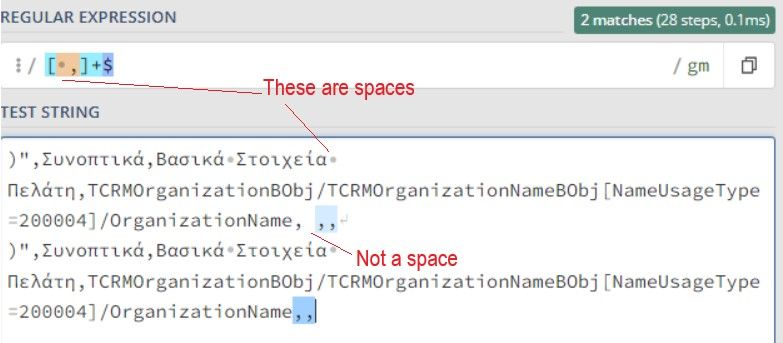
So it must be another “white space” character(s), possibly replace the space in my solution with [[:space:]] as this includes a non-breaking space, amongst others. The only way to determine that would be to investigate it in Notepad++ and find it’s hex value.
@Alan-Kilborn agreed, I didn’t cater for a line ending in just spaces. My amended regex would be
(?-s)(?=.?,)[ ,]+$. But since this would also miss the issue in the OP’s image I would leave that to the OP to first identify the mystery character before substituting (or including) it in the original solution.I also agree with @Alan-Kilborn response to your quick assertions that things don’t work. You have been a member for long enough to have picked up some tools. Use them, thus far it seems you are quick to ask questions but slow to do any actual work yourself.
@patrickdrd, remember, you come to us with the questions, if you don’t do any work in the process, you may quickly find the solutions dry up.
Terry
-
your solution doesn’t match this case:
}", , , ,Yes, it does, for me. But maybe you have some other context
You have
NBSPcharacters in there.
That’s why my solution didn’t work for you.
So I take back my criticism of Mark’s suggested solution, as\hwill actually matchNBSP.
Let’s chalk it up to an OP wanting a solution to a problem/data he really doesn’t understand. :-P -
Hello, @patrickdrd, @terry-r, @ekopalypse, @mark-olson, @alan-kilborn and all,
After some tests, I do think than the @alan-kilborn’s formulation is the best and more simple one to achieve @patrickdrd’s needs,
I did find one myself, which is more complicated (
([\x20,]+)?,+([\x20,]+)?$). So, no need to speak about it !
Thus, @patrickdrd, given the text, below, with all lines beginning with a double-quote character :
================= with SPACE, TABULATION and NO-BREAK SPACE chars ========================= " " " , " , ", ", " , ", ", ", ",, " ,, ",, ", , " ,, ",, ", , " ,, ",, ", , ",,, ",,,,,, " ,,,,,, " ,,,,,, " ,,,,,, " , ,, , ,, " , ,, , ,, ", ,, , ,, ================= with SPACE and TABULATION chars ========================================= " " " , " , ", ", " , ", ", ", ",, " ,, ",, ", , " ,, ",, ", , ",,, ",,,,,, " ,,,,,, " ,,,,,, ",,,,,, " , ,, , ,, " , ,, , ,, ", ,, , ,, ================= with SPACE chars ONLY ================================================== " " " , " , ", ", " , ", ",, " ,, ",, ", , ",,, ",,,,,, " ,,,,,, ",,,,,, " ,,,,,, " , ,, , ,, " , ,, , ,, " ,,, , ,, =========================================================================================== 477,UpdateConsortiumControls,function",,,"UpdateConsortiumControls() { 477,UpdateConsortiumControls,function", ,"UpdateConsortiumControls() { 477,UpdateConsortiumControls,function", ,"UpdateConsortiumControls() { 477,UpdateConsortiumControls,function", ,"UpdateConsortiumControls() { ===========================================================================================Test the three following regexes against this text. And, if your blank characters are :
-
Space chars only, use the initial @alan-kilborn’s solution
"\x20*,[\x20,]*$=>41matches -
Space or tabulation chars, use the @alan-kilborn’s variant
"[\t\x20]*,[\t\x20,]*$=>58matches -
Space, tabulation or no-break space chars, use the @alan-kilborn’s variant
"\h*,[\h,]*$=>67matches
Best Regards,
guy038
-
-
Hi, @patrickdrd and **All,
I think I did not understand properly your statement :
meanwhile I found out that I would need to ignore (i.e match) these two cases too:
So I initially thought that you wanted that the regex ignore these lines. But if, at the contrary, you would like that the regex does match these cases too, then, simply, get rid of the
$regex char at the end of each regex !BR
guy038
-
hello all,
unfortunately my file had a ton of bs in that matter,
these are supoosed to be excel lines proceesed by a plugin and the commas denote the different columns,
so, after experimenting, I got best results with this one:(?:\h*,)+but I think this matches simple commas too, which I don’t want :(
anyway, I’m posting one of my such files to take a look yourselves if and whoever has some time, thanks!
-
@patrickdrd said in regexp to match comma(s) end of line:
That looks like a normal CSV file that I loaded into into Excel without issues. There is one unusual thing about your file which is that it has six sections each with it’s own set of columns.
Line 1: Id,Name,Type,Id,UIField,Comments,Category,SubCategory,XSLT,Length, Line 1288: CategoryName,SubCategoryName,Description ,Image Line 1331: Id,Name,Type,Id,Validation Type,Validation Expression,Validation Message,,,,,,,,,,,, Line 1600: Name,RegEx Line 1618: Id,Name,Type,Id,Event,Interaction Fields,Description,,,,, Line 5417: Id,Name,Type,Id,UIField,Comments,XSLT,Length,EventsSomething that is not clear is exactly what you want to do with the file. The project will by complicated by that it’s a CSV format with the data needing to be within
"quotes"at times. I would use one of the CSV parser plugins as that can deal with the quotes. I don’t know how many of them can recognize that you have six sections each with their own set of columns,.Initially you had asked for
match comma(s) (at least one) in the end of a line with or without spaces between them or before them or after them
I don’t see any space/comma sets at the end of any lines. All seven lines that match \x20,+$ seem to have data in the last column with data where the data ends in a space. There are no lines that match
comma space commaor,+\x20+,+in the example data. That does not mean you could have a file with that data but to mean it means on of your data fields contains just a space. They may be the first, middle, or last field on a line.I also did not see any unusual space characters in the example file other than a few fields contain tab characters and some contain end of line characters. Those are
"quoted"per CSV formatting rules. -
I’m trying to find a way to compare 2 excel files (xlsx), examdiff has a plugin to do so and regexp to exclude bs characters in the end, but i can’t filter them out
-
@patrickdrd said in regexp to match comma(s) end of line:
I’m trying to find a way to compare 2 excel files (xlsx), examdiff has a plugin to do so and regexp to exclude bs characters in the end, but i can’t filter them out
I usually do that directly within Excel. Normally I use the
MATCH()function get the row I want to compare and thenINDEX()to pull the data from a specific column on that row. TheEXACT()function is a case-insensitive compare. More detail that that is far outside the scope of this forum, which focuses on Notepad++.It sounds like you want to use Notepad++ regular expressions to normalize or clean up the data so that other tools such as examdiff don’t get upset at the noise.
Are you trying to detect any changes in your Excel files or are you only interested in the visible text in cells? For example, if I right click and add a comment to an Excel cell are you trying to detect that I made the comment? The reason I asked that is that it’s not clear if a tool such as Notepad++ would be helpful or a hindrance. Your current example CSV contains a wide range of things such as script snippets and what looks like relational database dumps.
-
Hello, @patrickdrd,
In a pevious post, you said :
anyway, I’m posting one of my such files to take a look yourselves if and whoever has some time, thanks!
So, I downloaded your file and, after studying it two days, I’m happy to email you back both the original file and the new one, with my formatting :-))
I succeeded to transform all your data in
9tables, described below :•----------•---------•---------• | Fields | Width | Lines | •----------•---------•---------• | 10 | 9,849 | 466 | | 4 | 146 | 43 | | 19 | 1,565 | 216 | | 2 | 154 | 15 | | 12 | 9,008 | 169 | | 12 | 5,992 | 89 | | 9 | 8,346 | 21 | | 9 | 226 | 39 | | 7 | 381 | 487 | •----------•---------•---------•REMARK : Just one record is still odd. You can get this record by searching the regex
\x{203D}{3}
I also rename this OUTPUT text file as an Lua file, in order to get a general folding, which does not interfere with your file contents !
Finally, I verified that the number of chars (
339,792) is identical between your original filePatrick_BEFORE.txtand the transformed filePatrick_AFTER.lua, with the regex(?![,| \[\]•\x{203D}\r\n-])[\x{0000}-\x{D7FF}\x{E000}-\x{FFFF}], which covers all theBMPUnicode plane, except for the10characters below :, | \x20 [ ] • ‽ \r \n -
I do hope that my work will be benefic to you, in some way !
Best Regards,
guy038
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login