Match consecutive lines that start with the same word
-
I’m learning Regex after being inspired by Alan Kilborn who massively helped me out a couple of weeks ago with my first query.
I am now trying to highlight header rows which are not followed by a data row so I can remove these from the data set.
These all start with the same 3 letters (in this example AAA) and I want to highlight the rows where they are not followed by a data row which all have a consistent first 3 letters (in this example BBB).
So, in this data I want to highlight and retain rows 1,2,6-11 and exclude 3-5 as these are not connected to a data row. The number of consecutive AAA rows can vary but I always need the last one before a BBB row.
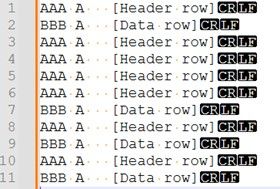
I have spent a lot of time Googling this and the closest I can find is:
(?s)(\w+)\s+\w+\r\n(\1\s+\w+(?:\r\n)?)+I found this on stackoverview, unfortunately I can’t post the link as I’m a newbie.
I’m struggling to edit this to work with my data set. Any help is much appreciated!
-
Hi @Ross-Brown
Keep up the good work learning regular expressions!
This is a task where lookahead and lookbehind can be useful, because you want to check whether the next line has some text, without moving forward to that line.
I came up with the regular expression
(?-s)^(TEXT_TO_MATCH)(.*)(\R|\z)(?=\1)to solve your problem, assuming you want to keep only lines that start withTEXT_TO_MATCHand that are not followed by another line that starts withTEXT_TO_MATCH.This regular expression does the following:
^(TEXT_TO_MATCH)attempts to findTEXT_TO_MATCHat the beginning of a line, then stores it as the first capture group(.*)consumes the rest of the line (since(?-s)was specified at the start of the regex) and stores it as the second capture group(\R|\z)(?=\1)stores the line ending (CRLF,CR, orLF) as the third capture group, but then fails the match if it sees that the next line does not start with the first capture group.
For example, let’s say you wanted to clear lines (remove their text but leave them empty) if they start with AAA or BBB followed by a normal space character and the next line has the same beginning.
Then you would replace
TEXT_TO_MATCHin our original regex with(?:AAA|BBB)\x20, since that matches AAA or BBB followed by a normal space character, and we get the regex(?-s)^((?:AAA|BBB)\x20)(.*)(\R|\z)(?=\1)We can test this out on this example:
AAA A [Header row 1] BBB B [Data row 1] AAA A [Header row 2] AAA A [Header row 3] AAA A [Header row 4] AAA A [Header row 5] BBB B [Data row 2] AAA A [Header row 6] BBB B [Data row 3] AAA A [Header row 7] BBB B [Data row 4] BBB B [Data row 5] AAA A [Header row 8]If we replace
(?-s)^((?:AAA|BBB)\x20)(.*)(\R|\z)(?=\1)with${3}, we clear everything except the line ending from each matched line, and get:AAA A [Header row 1] BBB B [Data row 1] AAA A [Header row 5] BBB B [Data row 2] AAA A [Header row 6] BBB B [Data row 3] AAA A [Header row 7] BBB B [Data row 5] AAA A [Header row 8]I hope that helped!
-
unfortunately I can’t post the link as I’m a newbie.
Asking questions in a way that makes it easy for us to help you would probably earn more upvotes. (But since this was enough for Mark to figure out what you wanted, I gave another upvote.)
But in the future, it would make it a lot easier for us to help you if you would give us your example data as text using the
</>button when you are creating your post, so we can copy/paste, rather than making us try to type the same thing we see in a screenshot. That way it ends up in the code box with the “copy code” button, like in Mark’s reply.(I had started an answer that was similar to Mark’s, but he posted before I got very far, so I stopped that part of my reply, and didn’t include any specifics for your situation; he explained it better than I was doing.)
-—
Useful References
-
@Mark-Olson Thanks Mark
It works perfectly and you have provided a really clear explanation. I was going to bookmark and remove the rows but your additional code was a bonus. I can follow the logic (helped by your clear explanation) it’s the groups I am getting stuck on. I will do some more research in this area. Thanks again! -
@PeterJones Thanks Peter
Noted and thanks for the helpful links.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login