Some more options for search & replace dialog
-
Hi,
as a Scintilla based text editor with excellent detection of:- comment
- preprocessor (C/C++)
- strings
- style & code (HTML)
- backtick strings (JavaScript)
- … (dependent on current syntax highlighting)
which is NOT expressive by Regular Expressions.
It would be very nice when searching can be restricted to that sub-types of the text.
This selection (default: all) is typically done with a listbox with checkmark items, as seen in installation programs.
It would help refactoring programs by renaming e.g. variables not touching strings, and vice versa. -
I can see why people would want it… but my guess is that would be highly difficult to implement. If you were to do an official feature request (no, a post in this forum is not a feature request, as explained in our FAQ), it is my guess that it would be rejected outright, or at best silently ignored – so, in my opinion, don’t get your hopes up, if you do put in a feature request. (For one, the regex engine is completely separate from the syntax highlighter, so I am not sure how feasible it would be for notepad++ to limit the range on regex searches to only be within certain chunks of text.)
Also, I am not sure that “Notepad++ & Plugin Development” is really the best place for this post (or any of your other recent ones), unless you are planning to be the one to implement some of these requests, and had specific questions. As the “Read This First”, pinned near the top of “Notepad++ & Plugin Development”, says,
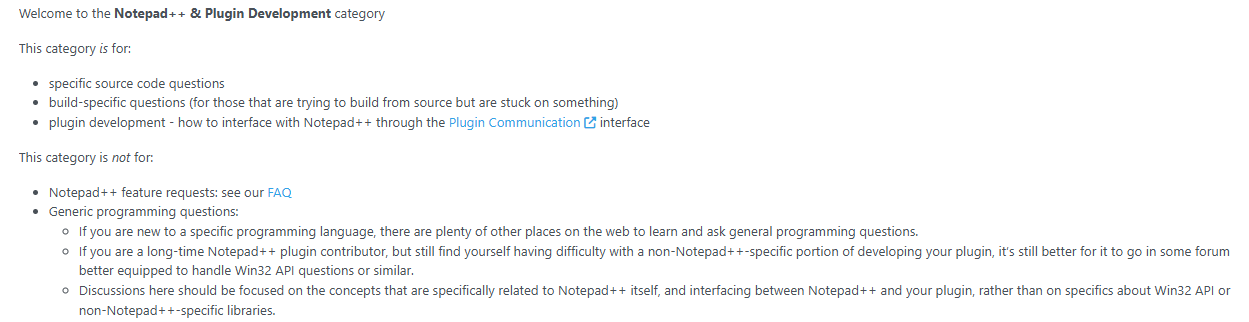
That is, it’s for technical questions about specific sections of source code, or questions or difficulties involved in the build process when trying to build a copy of Notepad++ that you are editing. It’s not for generic “I would like it if Notepad++ did XYZ”, which is what your posts seem to me to be.
-
Just eyeballing the documentation, my guess is that the way to search each region with a certain style could be found in this part of the Scintilla docs.
-
@Mark-Olson said in Some more options for search & replace dialog:
Just eyeballing the documentation, my guess is that the way to search each region with a certain style could be found in this part of the Scintilla docs .
Having done some more serious combing through the Scintilla docs, I am reconsidering that guess. I see no way to give Scintilla a style name and iterate through the regions of the document with that style.
I know for a fact that you can iterate through all the regions in a document with a given indicator, and I use this extensively in JsonTools, so I kinda figured that there would be some similar API for styles. Unfortunately, I can’t find such an API. I’m almost certainly missing something, so I’m hoping that someone who’s more well-versed in lexers could help here.
This seems like a really interesting problem, and I might cook something up in Python or C# if someone could point me in the right direction.
-
@Mark-Olson said in Some more options for search & replace dialog:
This seems like a really interesting problem, and I might cook something up in Python or C# if someone could point me in the right direction.
You could iterate through every single character in the document, calling SCI_GETSTYLEINDEXAT, and then every time the style changes, you can search the previous start-to-end if it matches the style of interest. And that’s fine for a small document (such as in the test suite of Lexilla, which I used as inspiration for my simplistic PythonScript implementation in “
styleDebugger.py”).But for a document of any size, having to iterate through the entire file and then searching only the matching sub-segments that have the right style would likely not be overly efficient. I could imagine a plugin providing its own search-and-replace using such, but IMO, it’s not well-suited to incorporating into the main Notepad++ search facility.
And with that idea, my initial assessment of “highly difficult to implement” may have been overstatement; “may be difficult to implement efficiently” is my new assessment. And doing it from PythonScript probably wouldn’t be performant enough for real-world files – but could be used as a proof of concept with smaller files
The more I think about it as a plugin (in C#, if you’re writing it), the more doable I think it would be for you. (Especially if you also read back the SCI_NAMEOFSTYLE for the active styler, so that your UI would allow you to choose which style to limit the search-replace to a named style, rather than making the user know which style number it is)
Other technical hurdles:
- not all stylers define their names, so some styles would just have to be numbers
- many stylers switch back to styleID 0 for spaces and newlines, but some have a different styleID for the same, and either way, every space or newline would interrupt your algorithm for determining a stretch
- there are probably other styles than the default/blank/newline style for a given styler which should also be skipped-over for the range tracking, and getting something useful enough that it would allow things like “only search inside the attributes and values in the open HTML/XML tag” or “only search in non-comment C++ code” – ie, the restrictions that would make it practical – might be hard to figure out without knowledge of each language
- there are probably a lot of edge cases and other confusions that I haven’t enumerated yet.
(and since this is now spitballing ideas for the implementation in a plugin, rather than just a feature request, it’s now more on-topic for this Category)
-
@Mark-Olson
@PeterJones said in Some more options for search & replace dialog:But for a document of any size, having to iterate through the entire file and then searching only the matching sub-segments that have the right style would likely not be overly efficient. I could imagine a plugin providing its own search-and-replace using such, but IMO, it’s not well-suited to incorporating into the main Notepad++ search facility.
If the file isn’t too large, you could use SCI_GETSTYLEDTEXTFULL to get a copy of the interleaved text and style bytes.
If you embed Boost::Regex directly (rather than using Scintilla’s search — search in Columns++ does this) you could then write iterators that would allow you to scan through that buffer taking the style bytes into account.
-
What you are looking for needs something like an LSP server or something that can build a syntax tree from your code and then search through it.
If the language you are using has an LSP server, you could use the NppLspClient, available here, to use the LSP Rename function to rename variables, for example, or the LSP Find references function to search for them.
Just for your information, I will provide a new version later today with some bug fixes and Npp >8.7.6 compatibility. -
@Coises
Thank you for explaining what SCI_GETSTYLEDTEXTFULL does. I looked at that method, but I couldn’t figure out how it was supposed to help. Now I do, and I think that should be sufficient to build a simple C# plugin or PythonScript script that can do something like what the OP was asking for.@Coises I assume that the text portion of the StyledTextFull buffer is UTF8-encoded (if you discard the style bytes), right?
I agree with @Ekopalypse that a language server is the real best option here, but obviously you have to install NppLSPClient and language servers for all the languages you want to use, and this just seems like a relatively “lean” option.
-
@Mark-Olson said in Some more options for search & replace dialog:
I assume that the text portion of the StyledTextFull buffer is UTF8-encoded (if you discard the style bytes), right?
Not necessarily. I looked at the Scintilla code a bit; there are, internally, two buffers, one containing the text and one containing the style bytes. While there is an API to access the text buffer directly (which I use), there is nothing I can find that does the same for the style bytes. Instead, SCI_GETSTYLEDTEXTFULL steps through both buffers simultaneously, copying first the text byte and then the style byte to the output buffer supplied in the call. (Unless I have misread the code — which is possible, since I didn’t spend a lot of time looking at it — though the documentation for SCI_GETSTYLEDTEXTFULL says it interleaves text characters and style bytes, it actually interleaves text bytes and style bytes.)
The text could be ANSI or UTF-8 — you have to check SCI_GETCODEPAGE, which in Notepad++ will be either zero (system default code page, aka “ANSI”) or CP_UTF8.
I had temporarily forgotten that you won’t be working in C++. I doubt that it is practical (maybe not even possible) to write a Boost::Regex iterator in “managed” code. It would probably make more sense to reverse what Scintilla does and split the returned value into a text buffer and a style buffer. Then you could scan the style bytes to determine what ranges to search, and either use whatever regex facilities are available in C# to scan the text, or just ignore the text bytes and use Scintilla find and replace to scan the ranges you identified from the style buffer.
Given the way Scintilla stores styles (as bytes that correspond one-for-one with the text — unlike indicators, which the documentation says “are stored in a format similar to run length encoding which is efficient in both speed and storage for sparse information”), there is probably no way much faster than scanning byte for byte — it’s just a trade-off between speed (getting it all with one Scintilla call) and memory (getting it byte by byte, so you don’t have to make large copies).
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login