Regex for mixed A/L characters in words
-
Hi,
is there some kind of regex for finding words in text that have both uppercase and lowercase characters like - “WhAt HappENs herE”?
I like to find and normalize it to - “What happens here”. -
How “smart” does it need to be, and what are the edge cases that need to be handled?
Does it need one capital per line? one per “sentence”? How exactly do you define the end of a “sentence”? What about names? Do you need to be able to distinguish end-of-sentence from end-of-abbreviation?
Hello. I am Col. Mustard. I slayed Prof. Plum in the Convervatory with the Lead Pipe. The mortician, Dr. Bob, lives on Capital Dr. in Big City. Can question marks end sentences? Don't forget exclamation points! We are quite curious which of these exceptions should be handled, and which shouldn't be, and how you expect to tell the difference between the abbreviations and the end of the sentence.In other words, you have to define all the rules you need the regex to apply to, otherwise we won’t be able to generate a regex that will make you happy.
If you’re on 32-bit, I believe the TextFX plugin probably has the case-conversion you’re looking for. But it’s been a long time since I’ve had that plugin installed, so I couldn’t tell you how, exactly.
Maybe even the builtin
Edit > Convert Case To > Sentence Casewould do what you want. It turns my example paragraph into:Hello. I am col. Mustard. I slayed prof. Plum in the convervatory with the lead pipe. The mortician, dr. Bob, lives on capital dr. In big city. Can question marks end sentences? Don't forget exclamation points! We are quite curious which of these exceptions should be handled, and which shouldn't be, and how you expect to tell the difference between the abbreviations and the end of the sentence.which would not be what I would want, but maybe it meets all your rules.
-
Sometimes has to be with fist capital, sometimes there is a person name in the middle/end/start. Sometimes there is a special symbol like “”/‘’. Al least i want to find that kind of words, i will fix them manually.
-
Given those requirements, does the builtin
Edit > Convert Case To > Sentence Casework for you, or are you still looking for additional help? -
Edit > Convert Case To > Sentence Case not a solution for me, sorry.
-
If you would still like help, you’re going to have to help us help you. Your only example text does change to what you claimed you wanted given the
Edit > Convert Case To > Sentence Caseoperation (highlight text, apply conversion). If you have an example of text that does not change properly, please show us that example: using the quoting methods described below, show us some example text that doesn’t convert correctly, show us what you would ideally like that text to look like, and show us the acceptable level of things you’d have to manually fix after applying the automatic fix (because based on your vague requirements, I don’t think we can match your ideal exactly). If there’s sensitive data in the text, feel free to use dummy text instead. But it has to show all the edge cases that you want to be able to handle. Because my solution worked for your one brief example, and your “clarification” didn’t make it any more clear what’s going wrong for you.Quoting Instructions:
There are a few ways you could quote the example text: you could use```z text here ```which would render as
text hereor you could use four indent spaces before every line:
Your normal reply-text here, no indent. Your quoted textfile here, with four spaces before every line Your normal reply-text here, no indent.(include the blank line before and after)
which would render as the following (between the horizontal lines):
Your normal reply-text here, no indent.
Your quoted textfile here, with four spaces before every lineYour normal reply-text here, no indent.
or you could do a screenshot, put it on imgur, and embed the image in the post using the syntax
– make sure you take the direct-link, not the link to the image page on imgur, otherwise it won’t embed and display here. Theoretically, you could also link to a pastebin document, or similar. Note, however, I will not download anything from pastebin or similar, since random links in forums are ways of distributing spam and viruses, so some braver soul than I would have to be willing to help you if you link to pastebin; and I would not recommend anyone click such a link. -
Here s example:
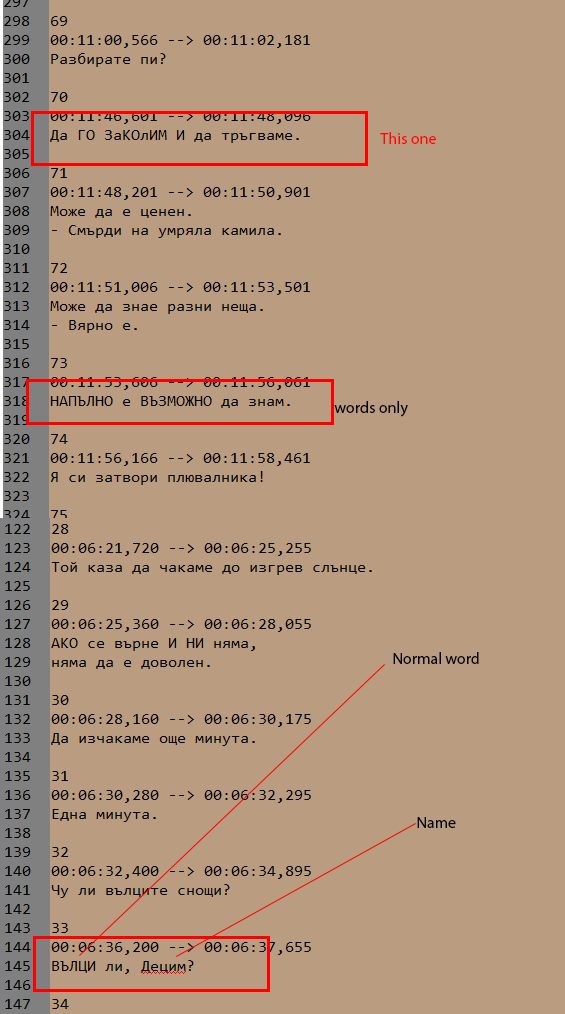
-
You still don’t show what you get, or what you expect/want, when you give it that input, so it’s still hard to tell what’s going wrong for you.
Using charmap to build up the Cyrillic characters (I think I got it right), I just successfully converted
НАПЪЛНО е ВЪЗМОЖНО да знам.into
Напълно е възможно да знам.by highlighting the one line, and applying the
Edit > Convert Case To > Sentence Casecommand. Does it not change for you? Or is this not the result you expect or desire?To clarify: with names, we’re not going to be able to have an automated conversion, because names can happen in the middle of sentences. (To be able to properly capitalize names, locations, abbreviations, and the like, you would probably need an A.I. / neural network / deep learning algorithm, or some other major parsing / lexing going on, not just a simple regex.) Hopefully, you’re willing to manually fix those. If not, then the answer is, “sorry, I cannot help you”.
-
I just realized: in my English version, there are two copies of that command:

I mean the first
Sentence Casenot the secondSentence case (blend). When I tried the(blend), it left it alone, and didn’t get the desired sentence-case.I don’t know if you’re using a Russian (or other Cyrillic-alphabet-based language) translation, in which case, the names might not translate exactly the same. But that’s what I am intending.
The more details you give us, rather than having me beg for little pieces one at a time, the easier it will be to help you. So far, as far as I can tell, the sequence I am following should work for you, so I am having trouble understanding why it doesn’t seem to work for you.
-
Is there a way (with shortcut or Ctrl+F and regex) to find that kind of words and i fix it manual with the Edit > Convert Case To > Sentence Case? Because file is big, and line after line is a pain. BTW, this is subtitle file.
-
If I had the text:
1 00:00:00,000 --> 00:11:22,333 Да ГО ЗаКОлИМ И да тръгваме. 2 00:00:00,000 --> 00:11:22,333 НАПЪЛНО е ВЪЗМОЖНО да знам. 3 33:00:00,000 --> 33:11:22,333 Да ГО ЗаКОлИМ И да тръгваме. 4 44:00:00,000 --> 44:11:22,333 НАПЪЛНО е ВЪЗМОЖНО да знам.and selected it all, then ran
Edit > Convert Case To > Sentence Case, I got:1 00:00:00,000 --> 00:11:22,333 Да го заколим и да тръгваме. 2 00:00:00,000 --> 00:11:22,333 Напълно е възможно да знам. 3 33:00:00,000 --> 33:11:22,333 Да го заколим и да тръгваме. 4 44:00:00,000 --> 44:11:22,333 Напълно е възможно да знам.Once again, this seems to apply it correctly throughout (excepting names, of course). Is that not what you want?
Ctrl+AthenCtrl+Alt+Uwould do the whole file in two key-combos.(Google Translate tells me my choice of lines from your screenshot wasn’t the best. I don’t intend harm to anyone ;). I just picked that as a second line from your screenshot.)
To answer the “manual” question: you could do some searches to just find offending lines. I provide some sample regexes below. Note, my regexes assume that the order that
charmap.exepresents the Cyrillic Unicode characters is vaguely alphabetical, so that[А-Я]is equivalent to the EnglishA-Z, matching all uppercase characters. In my test document, above, it seems to.^(?-is)[А-Я].*[А-Я].*$= find and highlight the next line that starts with an uppercase, which contains at least one more uppercase (which thus possibly violates the “one uppercase per sentence”)^(?-is)[а-я].*$= find any line that starts with a lowercase (and thus possibly violates “sentence starts with a capital”)(?-is)\b\w*[А-Я]\w*[А-Я]\w*\b= find any word that has multiple capital letters in it(?-is)\b\w+[А-Я]\w*\b= find any word that has an uppercase anywhere but the first character
Some regex hints:
^and$anchor to beginning and end of line(?-is)ensures that the search is case-sensitive, and that.will not match EOL[А-Я]meansА,Я, and all the characters in between.*means 0 or more of any character\bmeans word-boundary\wmeans word-character (alphanumeric plus_; seems to work for Unicode Cyrillic alphabet too, not just the Latin alphabet, which is nice for this context)\w*means 0 or more word characters\w+means 1 or more word characters (at least one)
-
-
This is what i searching PeterJones. This kind of regex! Thank you!
-
Hello, @maknol, @peterjones, and All
Here are two regexes, which could be useful to you :
-
(?-i)\u+will match any non null sequence of Cyrillic Capital letter(s) -
(?-i)(?<=\l|\u)(\d+|[[:punct:]]+)(?=\l|\u)will look for any non-null sequence of digit(s) OR punctuation character(s), ONLY IF surrounded, both, before and after with a letter, whatever its case
Then, each occurrence found could be, easily :
-
Converted to lower-case (
Ctrl + U) -
Converted to upper-case (
Ctrl + Shift + U) -
Deleted (
Delete)
You may also combine the two regexes, above, in the single regex, below :
(?-i)\u+|(?<=\l|\u)(\d+|[[:punct:]]+)(?=\l|\u)However, due to some bugs with backward assertions of the Boost regex engine, used by N++, it may miss some occurrences
Just test, on the text below, the two individual regexes, above, first, then, the global one to see the slight differences :
аbc33def abc//DEf aBC33def aBC//DEf ' english абв33где абв//ГДе аБВ33где аБВ//ГДе ' cyrillicNow, @maknol, which kind of symbols are you expecting within words ? For a few amount of these symobls, we could restrict the matches, let’s say, to digits and the
/symbol, for instance ?
And regarding the differences between the case conversions :
-
Proper CaseandProper Case (blend) -
Sentence caseandSentence case (blend)
just looks at that example, below :
---------------------------------------- INITIAL text ----------------------------------------------------------------- GNU GENERAL PUBLIC LICENSE abc aBc abC aBC Abc ABc AbC ABC 0000 everyone is permitted to copy and DisTRIbute verbatim copies of this License DOCUment. but changing it is NOT allowed. ^ ^^^ ^ ^^^^ ^^^ ---------------------------------------- Proper Case -------------- ( Alt + U ) --------------------------------------- Gnu General Public License Abc Abc Abc Abc Abc Abc Abc Abc 0000 Everyone Is Permitted To Copy And Distribute Verbatim Copies Of This License Document. But Changing It Is Not Allowed. ---------------------------------------- Proper Case (blend) ------ ( Alt + Shift + U ) ------------------------------- GNU GENERAL PUBLIC LICENSE Abc ABc AbC ABC Abc ABc AbC ABC 0000 Everyone Is Permitted To Copy And DisTRIbute Verbatim Copies Of This License DOCUment. But Changing It Is NOT Allowed. ---------------------------------------- Sentence case ------------ ( Ctrl + Alt + U ) -------------------------------- Gnu general public license Abc abc abc abc abc abc abc abc 0000 Everyone is permitted to copy and distribute verbatim copies of this license document. But changing it is not allowed. ---------------------------------------- Sentence case (blend) ---- ( Ctrl + Alt + Shift + U ) ------------------------ GNU GENERAL PUBLIC LICENSE Abc aBc abC aBC Abc ABc AbC ABC 0000 Everyone is permitted to copy and DisTRIbute verbatim copies of this License DOCUment. But changing it is NOT allowed.From above, Peter and All, it’s easy to deduct that :
-
The
Proper Casecommand UPPER-cases the first letter of each word and LOWER-cases all the other letters of each word -
The
Proper Case (blend)command UPPER-cases the first letter of each word and did NOT change the case of all the other letters of each word -
The
Sentence casecommand UPPER-cases the first letter of each sentence and LOWER-cases all the other letters of each sentence -
The
Sentence case (blend)command UPPER-cases the first letter of each sentence and did NOT change the case of all the other letters of each sentence
Best Regards,
guy038
-