Regex: Select all from row except
-
base64 encode…LOL… +1
-
@PeterJones said:
If you can show enough effort to go search out a utility that will decode base64-encoded data
…or do what I did and rack my brain trying to remember how to get Notepad++ itself to do it (which I finally was able to do) !
-
Honestly, I was expecting the OP to just google and click on the first link found, which would have done the trick, too. But doing it inside Notepad++ is even better.
I had forgotten that option was there in that menu. There are a lot of good features either built in or added to Notepad++. I knew there was a reason I love this editor. :-)
-
Hi, @vasile-caraus, @scott-sumner, @peterjones and All,
Scott and Peter, I do understand and agree to the general philosophy of your replies. Besides, I’m a bit surprised of Vasile’s request as he have already been able to create regexes more complicated that the one needed for that topic !
To be honest, just admit that Vasile clearly identified the BEFORE text and the AFTER desired text :-)
So, I’ll try to solve his problem, using a bit of logic, just to demonstrate that, as always, when a problem is well posed, the solution often becomes obvious !
So, using your first sample line :
<li><a hrefs="love-and-attitude.html" title="Love and Attitude">Love and Attitude (24)</a></li>-
Select any
>symbol and use the menu option Search > Mark All > Using 5th Style -
Select any
<symbol and use the menu option Search > Mark All > Using 2nd Style
Note that I have chosen these colours, on purpose, with reference to traffic lights : Green =>
Goand Red =>Stop!By examining the line, you’ll clearly see that the only gap beginning with a green style and ending with a red style, which contains some characters inside, is the string that you expect to keep :
Love and Attitude (24)So a first approach would be to consider the regex
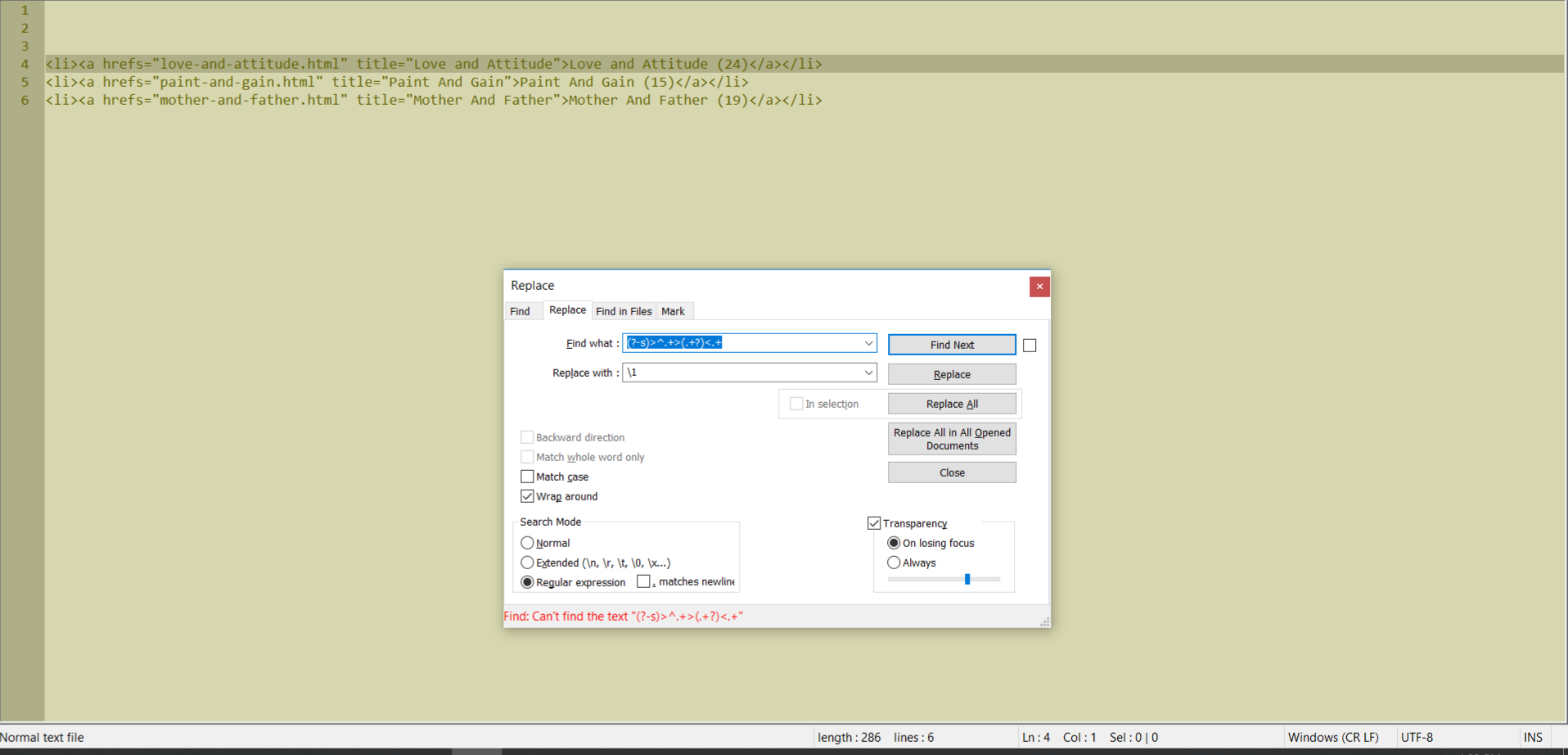
(?-s)>.+<, which matches any standard char between the>and<boundaries !But, actually, there are two ranges of characters which verify that rule :
-
>Love and Attitude (24)< -
>Love and Attitude (24)</a><
Right away, we realize, or course, that we must use the shortest range, which leads to the use of lazy quantifiers in regexes, adding a
?symbol to the present+quantifierSo, we’re looking for the shortest non-null range of characters, between the
>and<boundaries and, as we’ll have to rewrite this range in replacement, this leads to the regex(?-s)>(.+?)<, with the parentheses to store it for future replacement
IMPORTANT :
Beware about these two descriptions :
-
If I write the regex
(?-is).+?a, it will match any non-null range of characters, different from analetter, till the first found lower-case lettera -
If I write the regex
(?-is).+?abc, it will match any non-null range of characters, which does not contain any stringabc, till the first found stringabc
Just test the two syntaxes, with the greedy
+and the lazy+?quantifiers, against the text below :0123456789 a 0012345678900123 ab 45678900123456789 abc 001234567890012 a 3456789001234 ab 56789001234567 abc 89001234567890
Now, Vasile, as all the line contents must be replaced with the group
1, we have to grab all characters, which are, either, before and after the>Love and Attitude (24)<string. As any non-null gap of characters, in a single line, can be obtained with the regex(?-s).+, then, the final regex is :(?-s)^.+>(.+?)<.+If we use the free-spacing mode, where any non-escaped space character is not taken in account, we get this more clear syntax :
(?x-s) ^ .+ > (.+?) < .+ # Line Beginning Some chars > The REPLACED string < Some charsOf course, the replacement zone is
\1and the line-break remains unchanged, as not processedCheers,
guy038
P.S. :
Naturally, I immediately remembered of the
Base64 Decodebuilt-in option, from Don’s plugin ;-)) -
-
@guy038 said:
(?-s)>^.+>(.+?)<.+
hello Guy, I try your regex, but it does not work
See a print screen:
-
Guy, I change a little bit your regex:
SEARCH:
.+>(.+?)<.+OR(?-s)^.+>(.+?)<.+
Replace by:\1Seems to work this.
-
Hi, @vasile-caraus, and All,
Sorry, I didn’t re-read enough my post after replying :-(( Indeed, you’re right : the
>character, located right after the(?-s), is useless, of course !So, I updated my last post, too and deleted this wrong
>char, in the regex ;-))Cheers
guy038
-
Perhaps it would be best if you shared your email address with @Vasile-Caraus for his future regex solution needs (of which there will probably be many). That way the rest of the Community doesn’t have to be bothered with the noise of trivial regex questions that don’t relate to Notepad++ and are better asked elsewhere.
I would also encourage you to set up some sort of “donation” method so that your consulting time can be paid for. Clearly all contributors here enjoy helping people learn on a free basis, but for those recipients that refuse to learn, infinite solutions provided without payment seems ridiculous.
-
it is not about me, Scott Sumner. It’s about hundreds of people searching for this information on the internet and they will find it here. Also, this will make notepad++ more popular in the world. You should learn to see things globally !
guy038 is a great man, helped me every time. Thank you very much. Next time I will send him email. Happy?
-
Hello, @Scott-sumner, @vasile-caraus, and All,
In your last post, Scott, you said :
That way the rest of the Community doesn’t have to be bothered with the noise of trivial regex questions that don’t relate to Notepad++ and are better asked elsewhere
I think you are particularly right on this point. But now I feel a little guilty !! So I’m wondering :
By answering, for the most part, to questions, related to regular expressions, ( for years ! ), am I distorting the true purpose of this forum, which should remain, I agree, focused on the features, improvements and bugs of Notepad++ ?
May be, I should slow down my appetite of regexes ;-)) What’s your feeling, fellows ?
Cheers,
guy038
-
@guy038 said:
What’s your feeling, fellows ?
Radio Yerevan would say: It depends ;-).
Notorious leechers shouldn’t be feeded for ever. I don’t know if @Vasile-Caraus actually is such a guy but his “I’m a designer and not a programmer” statement is a lame excuse.
-
So I think that first time regex question posters come here because they don’t know what else to do. They don’t (necessarily) know even what regular expressions are–they just know that they have a problem with data manipulation and don’t know how to solve it…but they hope Notepad++ can help them…AND IT CAN! So, yes, true, this is not a forum for regex, but these naive first-time posters certainly don’t know that; they can be excused.
And I think it is fine to help them out, and give them a boost (pun fully intended) into learning about the Wonderful World of Regular Expressions. But I also think it is fair, if the same people keep coming back for more answers, over and over, that we ask them what they’ve tried first, to show their learning or at least how they are thinking about a problem…instead of just handing out answers.
So, no, @guy038, I don’t think you should slow down with the regexes. You have to be you. :-)
{kind=link}
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login