File sorting
-
I’m new here so please be gentle!!!
Is it possible to sort a file by line length??
Thats all!
Thanks
Dave -
As gently as possible…quiet now…here it comes: no (sorry), not with Notepad++ itself.
A lot of other ways, though: think “programming”.
-
Hello, @dave-pruce, @alan-kilborn and All,
Still, as gently as possible, I can whisper to you : There a possible work-around, which only uses native N++ features ;-))
As it’s about
1.40 a.m, presently, in France, I hope to be able to post my solution, tomorrow. So just be patient, a while !Best Regards,
guy038
-
I’ll have to see the number of steps involved to see if it invalidates my original “no”. :)
-
While we’re waiting for @guy038, while not native to Notepad++, a Pythonscript one-liner can do the job:
editor.setText(['\r\n','\r','\n'][editor.getEOLMode()].join(sorted(editor.getText().splitlines(),key=len)))And since it is a one-liner, one doesn’t even have to create a file for it. Just open a Pythonscript Console window (Plugins > Pythonscript > Show Console) and then find the little box that has
>>>to its left in the console window and paste the above there. Press Enter to execute it for the active Notepad++ file.Sadly, the bigger hurdle would be getting Pythonscript installed. :-(
-
Hi, @dave-pruce, @alan-kilborn and All,
The work-around comes from a simple idea. Imagine these
5lines, below !wxyz defghijklm no abcd pqrstuvTo begin with, right justify these
5lines. So you get :wxyz defghijklm no abcd pqrstuvNow, run a simple ascending alphabetic sort
no abcd wxyz pqrstuv defghijklmNice ! We have, automatically, all the lines sorted by line length.
To end, you just have to get rid of the leading spaces, giving the expected text :
no abcd wxyz pqrstuv defghijklmIn addition, notice that lines of same length are, also, sorted alphabetically, too ;-))
OK ! Let’s use a real list. From, the link, below :
https://en.wikipedia.org/wiki/List_of_rivers_by_length
I got, for instance, after some re-formating, an English world list of
243rivers, below, pasted in a new N++ tab :Nile White Nile Kagera Nyabarongo Mwogo Rukarara Amazon Ucayali Tambo Ene Mantaro Yangtze Mississippi Missouri Jefferson Beaverhead Red Rock Hell Roaring Yenisei Angara Selenge Ider Yellow River Ob Irtysh Río de la Plata Paraná Congo Chambeshi Amur Argun Kherlen Lena Mekong Mackenzie Slave Peace Finlay Niger Brahmaputra Tsangpo Murray Darling Culgoa Balonne Condamine Tocantins Araguaia Volga Indus Sênggê Zangbo Shatt al-Arab Euphrates Murat Madeira Mamoré Caine Rocha Purús Yukon São Francisco Syr Darya Naryn Salween Saint Lawrence Niagara Detroit Saint Clair Saint Marys Saint Louis North Nizhnyaya Tunguska Danube Breg Zambezi Vilyuy Araguaia Ganges Hooghly Padma Amu Darya Panj Japurá Nelson Saskatchewan Paraguay Kolyma Pilcomayo Biya Katun Ishim Juruá Ural Arkansas Colorado Olenyok Dnieper Aldan Ubangi Uele Negro Columbia Zhujiang Red Ayeyarwady Kasai Ohio Allegheny Orinoco Tarim Xingu Orange Salado Vitim Tigris Songhua Tapajós Don Podkamennaya Tunguska Pechora Kama Limpopo Chulym Guaporé Indigirka Snake Senegal Uruguay Blue Nile Churchill Khatanga Okavango Volta Beni Platte Tobol Alazeya Jubba Shebelle Içá Magdalena Han Kura Oka Murray Guaviare Pecos Murrumbidgee Yenisei Godavari Colorado Río Grande Belaya Cooper Barcoo Marañón Dniester Benue Ili Warburton Georgina Sutlej Yamuna Vyatka Fraser Brazos Liao Lachlan Yalong Iguaçu Olyokma Northern Dvina Sukhona Krishna Iriri Narmada Lomami Ottawa Lerma Grande de Santiago Elbe Vltava Zeya Juruena Rhine Athabasca Canadian North Saskatchewan Vistula Bug Vaal Shire Ogooué Nen Kızılırmak Markha Green Milk Chindwin Sankuru Wu Red James Kapuas Desna Helmand Madre de Dios Tietê Vychegda Sepik Cimarron Anadyr Paraíba do Sul Jialing Liard Cumberland White Huallaga Kwango Draa Gambia Tyung Chenab Yellowstone Ghaghara Huai Aras Chu Seversky Donets Bermejo Fly Kuskokwim Tennessee Oder Warta Aruwimi Daugava Gila Loire Essequibo Khoper Tagus FlindersIronically, we’re going to classify them, according to the length of their name and not according to their length ;-))
First, we’ll, roughly, estimate the maximum length of the listed names, with the generic regex
(?-s)^.{N,}-
Open the
Replacewindow (Ctrl + H) -
Select the
Regular expressionsearch mode-
(?-s)^.{30,}and a click on theCountbutton =>0matches -
(?-s)^.{25,}and a click on theCountbutton =>0matches -
(?-s)^.{20,}and a click on theCountbutton =>1match
-
=> The maximum length is between
20and25. So, we’ll rely on the upper boundary25in the subsequent regexes :
For all the subsequent regex S/R :
-
Tick the
Wrap aroundoption -
Click on the
Replace Allbutton, exclusively, to process each S/R
We’ll begin to add
25space chars, at end of each line of the list :SEARCH
(?-s)^.+REPLACE
$0( and type in25space characters, right after$0, in the Replace zoneNote : In case, you would need, for an other list, additional space chars, at end of lines, just re-run this S/R to get
50,75,100, spaces and so on !
Then, use the following regex S/R, in order to truncate any standard character, located after the
25column :SEARCH
(?-s)^.{25}\K.+REPLACE
Leave EMPTY
Now, we’re going to right justify all these names, with the regex S/R :
SEARCH
(?-s)^(.+?)(\x20{2,})$REPLACE
\2\1You should get the following text ( I simply put the beginning and end of the list, in order to limit my post length ! ) :
Nile White Nile Kagera Nyabarongo Mwogo Rukarara Amazon Ucayali Tambo Ene ......................... ......................... ......................... Oder Warta Aruwimi Daugava Gila Loire Essequibo Khoper Tagus FlindersNow, we perform the usual alphabetic sort (
Edit > Line Operations > Sort Lines Lexicographically Ascending) and we get :Ob Wu Bug Chu Don Ene Fly Han Ili Içá Nen Oka Red Red Amur Aras Beni ......................... ......................... ......................... Hell Roaring Murrumbidgee Saskatchewan Yellow River Madre de Dios Shatt al-Arab São Francisco Sênggê Zangbo Northern Dvina Paraíba do Sul Saint Lawrence Río de la Plata Seversky Donets Grande de Santiago Nizhnyaya Tunguska North Saskatchewan Podkamennaya Tunguska
To end, we get rid of all the leading spaces, with :
SEARCH
^\x20+REPLACE
Leave EMPTYand we get our expected list :
Ob Wu Bug Chu Don Ene Fly Han Ili Içá Nen Oka Red Red Amur Aras Beni Biya Breg Draa .............. .............. .............. Saint Louis Saint Marys Yellowstone Hell Roaring Murrumbidgee Saskatchewan Yellow River Madre de Dios Shatt al-Arab São Francisco Sênggê Zangbo Northern Dvina Paraíba do Sul Saint Lawrence Río de la Plata Seversky Donets Grande de Santiago Nizhnyaya Tunguska North Saskatchewan Podkamennaya Tunguska
Note that this kind of text manipulation should certainly be programmed, in a more elegant way, with a Python or Lua script ;-)) Unfortunately, my skills in that matter are quite poor :-((
However, I’m sure that some gurus, as @alan-kilborn, @ekopalypse @peterjones or dail, will probably be able to give you a script solution, that, of course, will require you to install the Python or Lua interpreter !
Hey, guys, it’s not a competition, OK !
Best Regards,
guy038
-
-
@guy038 said:
Hey, guys, it’s not a competition, OK !
Haha. No, definitely not. A support forum is about giving posters options to solving problems where there is not a very clear answer. It seems we’ve done that so far in this thread! :)
BTW, that was what I anticipated: A lot of manual steps. :)
-
Hi, @dave-pruce, @alan-kilborn and All,
My previous list of rivers contained
5duplicate names :Red,Murray,Yenisei,AraguaiaandColoradoBut this is not important, regarding our problem, anyway !
As you can see, @@dave-pruce, the Python solution, from Alan, is neater ! Isn’t it ?
Now, Alan, I’ve just tested your one-line script and, to my mind, there’s two problems :
-
Inside a section of river names, of a same length, the names are not sorted alphabetically !
-
Secondly, some names, containing accentuated characters, as, for instance, the
Içáriver, are located outside their section, as noticed, below :
Snake Volta Tobol Jubba Içá Pecos Benue Iriri LermaCheers,
guy038
-
-
@guy038 said:
names are not sorted alphabetically
This is outside the scope of the originally stated problem! :)
containing accentuated characters…are located outside their section
The Python
lenfunction is apparently simple-minded in this case (using a simple byte count for the length of these strings containing multibyte characters). -
@Alan-Kilborn said:
The Python len function is apparently simple-minded in this case
Perhaps this new one-liner is better, for the case where the OP has Unicode data:
editor.setText(['\r\n','\r','\n'][editor.getEOLMode()].join(sorted(editor.getText().splitlines(),key=lambda x:len(unicode(x,'utf-8')))))Of course, still big assumption that the OP is using (or is willing to use) Pythonscript! ;)
-
Yes, your new attempt, Alan, is the solution, when working with
UTF8encoded files, which may content multi-bytes encoded chars !As for me, I was thinking about the opposite solution : to convert
UTf8-files toANSI. However, when using this solution, some characters may result in question marks or may be changed for an approximate character, because, they do not belong to the the corresponding ANSI table of256characters !For instance, in my previous list of rivers, the Turkish
Kızılırmakriver, containing the Latin lowercase pointless letterı, ( of code-point\x{0131}), is changed into the approximate nameKizilirmak, after conversion toANSI!Anyway, we just did our best to solve the OP’s problem ;-))
BR
guy038
-
@ Dave-Pruce said :
Is it possible to sort a file by line length??
Yes, not natively, but there is a Notepad++ plugin for it: Linesort v1.1 (but only for 32bit Notepad++) :
https://webarchive.org/web/20200207125518/http://www.scout-soft.com/linesort/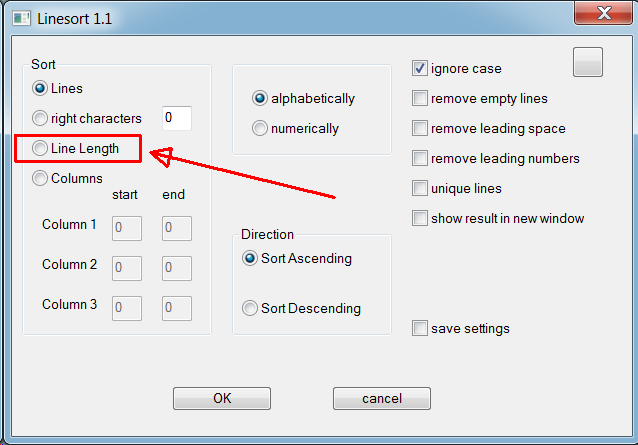
-
This post is deleted! -
@guy038 You essentially did “programming” with a human computer doing the evaluations and flow control. :-)
That reminds me of the stories about the first computers, which was a human job title, for those that computed but also had to do flow control! When ways were figured out in how to do parts of the job, first via mechanical means, and then electronic, the resulting machines came to be known as computers.
-
Hello, All,
Thanks to, @mkupper, which recently posted a comment and exactly, three years later, I going to simplify the way to get a sort by length of lines and, secondly, by line contents, too !
Like in my previous post, I will use this list of rivers, below :
https://en.wikipedia.org/wiki/List_of_rivers_by_length
After suppression of some doublons, we get an INPUT text of
238river’s names :Nile White Nile Kagera Nyabarongo Mwogo Rukarara Amazon Ucayali Tambo Ene Mantaro Yangtze Mississippi Missouri Jefferson Beaverhead Red Rock Hell Roaring Yenisei Angara Selenge Ider Yellow River Ob Irtysh Río de la Plata Paraná Congo Chambeshi Amur Argun Kherlen Lena Mekong Mackenzie Slave Peace Finlay Niger Brahmaputra Tsangpo Murray Darling Culgoa Balonne Condamine Tocantins Araguaia Volga Indus Sênggê Zangbo Shatt al-Arab Euphrates Murat Madeira Mamoré Caine Rocha Purús Yukon São Francisco Syr Darya Naryn Salween Saint Lawrence Niagara Detroit Saint Clair Saint Marys Saint Louis North Nizhnyaya Tunguska Danube Breg Zambezi Vilyuy Ganges Hooghly Padma Amu Darya Panj Japurá Nelson Saskatchewan Paraguay Kolyma Pilcomayo Biya Katun Ishim Juruá Ural Arkansas Colorado Olenyok Dnieper Aldan Ubangi Uele Negro Columbia Zhujiang Red Ayeyarwady Kasai Ohio Allegheny Orinoco Tarim Xingu Orange Salado Vitim Tigris Songhua Tapajós Don Podkamennaya Tunguska Pechora Kama Limpopo Chulym Guaporé Indigirka Snake Senegal Uruguay Blue Nile Churchill Khatanga Okavango Volta Beni Platte Tobol Alazeya Jubba Shebelle Içá Magdalena Han Kura Oka Guaviare Pecos Murrumbidgee Godavari Río Grande Belaya Cooper Barcoo Marañón Dniester Benue Ili Warburton Georgina Sutlej Yamuna Vyatka Fraser Brazos Liao Lachlan Yalong Iguaçu Olyokma Northern Dvina Sukhona Krishna Iriri Narmada Lomami Ottawa Lerma Grande de Santiago Elbe Vltava Zeya Juruena Rhine Athabasca Canadian North Saskatchewan Vistula Bug Vaal Shire Ogooué Nen Kızılırmak Markha Green Milk Chindwin Sankuru Wu James Kapuas Desna Helmand Madre de Dios Tietê Vychegda Sepik Cimarron Anadyr Paraíba do Sul Jialing Liard Cumberland White Huallaga Kwango Draa Gambia Tyung Chenab Yellowstone Ghaghara Huai Aras Chu Seversky Donets Bermejo Fly Kuskokwim Tennessee Oder Warta Aruwimi Daugava Gila Loire Essequibo Khoper Tagus Flinders-
At end of the first line, we add some
spacechars till column100 -
Then, with a zero-length selection, at column
100, we insert a exclamation mark (!) at end of all lines of the list :
=> We get this temporary text ( I just listed the first lines and the last lines ) :
Nile ! White Nile ! Kagera ! Nyabarongo ! Mwogo ! Rukarara ! Amazon ! Ucayali ! Tambo ! Ene ! Mantaro ! Yangtze ! Mississippi ! Missouri ! ...... ! ...... ! ...... ! ...... ! Seversky Donets ! Bermejo ! Fly ! Kuskokwim ! Tennessee ! Oder ! Warta ! Aruwimi ! Daugava ! Gila ! Loire ! Essequibo ! Khoper ! Tagus ! Flinders !-
Now, we perform this regex S/R :
-
SEARCH
^([\w -]+?)(\x20+)(?=!) -
REPLACE
\2\1
-
=> Again, we get this temporary text ( I just listed the first lines and the last lines ) :
Nile! White Nile! Kagera! Nyabarongo! Mwogo! Rukarara! Amazon! Ucayali! Tambo! Ene! Mantaro! Yangtze! Mississippi! Missouri! ......! ......! ......! ......! Seversky Donets! Bermejo! Fly! Kuskokwim! Tennessee! Oder! Warta! Aruwimi! Daugava! Gila! Loire! Essequibo! Khoper! Tagus! Flinders!- Then, we run the
Edit > Line Operations > Sort Lines Lexicographically Ascendingoption
==> Here is our sorted text ( I just listed the first lines and the last lines ) :
Ob! Wu! Bug! Chu! Don! Ene! Fly! Han! Ili! Içá! Nen! Oka! Red! Amur! Aras! ......! ......! ......! ......! Saskatchewan! Yellow River! Madre de Dios! Shatt al-Arab! São Francisco! Sênggê Zangbo! Northern Dvina! Paraíba do Sul! Saint Lawrence! Río de la Plata! Seversky Donets! Grande de Santiago! Nizhnyaya Tunguska! North Saskatchewan! Podkamennaya Tunguska!-
Finally, let’s run this last regex S/R
-
SEARCH
^\x20+|!$ -
REPLACE
Leave EMPTY
-
=> It remains our expected OUTPUT text, sorted by
line length:Ob Wu Bug Chu Don Ene Fly Han Ili Içá Nen Oka Red Amur Aras Beni Biya Breg Draa Elbe Gila Huai Ider Kama Kura Lena Liao Milk Nile Oder Ohio Panj Uele Ural Vaal Zeya Aldan Argun Benue Caine Congo Desna Green Indus Iriri Ishim James Jubba Juruá Kasai Katun Lerma Liard Loire Murat Mwogo Naryn Negro Niger North Padma Peace Pecos Purús Rhine Rocha Sepik Shire Slave Snake Tagus Tambo Tarim Tietê Tobol Tyung Vitim Volga Volta Warta White Xingu Yukon Amazon Anadyr Angara Barcoo Belaya Brazos Chenab Chulym Cooper Culgoa Danube Finlay Fraser Gambia Ganges Iguaçu Irtysh Japurá Kagera Kapuas Khoper Kolyma Kwango Lomami Mamoré Markha Mekong Murray Nelson Ogooué Orange Ottawa Paraná Platte Salado Sutlej Tigris Ubangi Vilyuy Vltava Vyatka Yalong Yamuna Alazeya Aruwimi Balonne Bermejo Darling Daugava Detroit Dnieper Guaporé Helmand Hooghly Jialing Juruena Kherlen Krishna Lachlan Limpopo Madeira Mantaro Marañón Narmada Niagara Olenyok Olyokma Orinoco Pechora Salween Sankuru Selenge Senegal Songhua Sukhona Tapajós Tsangpo Ucayali Uruguay Vistula Yangtze Yenisei Zambezi Araguaia Arkansas Canadian Chindwin Cimarron Colorado Columbia Dniester Flinders Georgina Ghaghara Godavari Guaviare Huallaga Khatanga Missouri Okavango Paraguay Red Rock Rukarara Shebelle Vychegda Zhujiang Allegheny Amu Darya Athabasca Blue Nile Chambeshi Churchill Condamine Essequibo Euphrates Indigirka Jefferson Kuskokwim Mackenzie Magdalena Pilcomayo Syr Darya Tennessee Tocantins Warburton Ayeyarwady Beaverhead Cumberland Kızılırmak Nyabarongo Río Grande White Nile Brahmaputra Mississippi Saint Clair Saint Louis Saint Marys Yellowstone Hell Roaring Murrumbidgee Saskatchewan Yellow River Madre de Dios Shatt al-Arab São Francisco Sênggê Zangbo Northern Dvina Paraíba do Sul Saint Lawrence Río de la Plata Seversky Donets Grande de Santiago Nizhnyaya Tunguska North Saskatchewan Podkamennaya TunguskaThat’s all ! Neat, isn’t it ?
Best Regards,
guy038
-
-
I received a feature request related to this post. It doesn’t quite feel like a good fit for Columns++ to me, but I think your MultiReplace plugin can assist in making this possible in a reasonable number of steps.
I believe multi-replace can be set up to find
^.*$and replace withset(string.len(MATCH).." "..MATCH).Then Edit | Line operations | Sort Lines As Integers Ascending will sort the lines in order by length, and then
^\d+\x20replaced with nothing would remove the lengths. -
JsonTools v6.0 or higher, open treeview for document, go to
REGEX mode, enter query@ = s_join(`\r\n`, sort_by(s_split(@, `\r\n`), s_len(@)))
Hopefully the syntax is reasonably easy to understand- split the file by\r\n, sort the list of lines by string length, then set the document’s text (@) to the result of string-joining the list back together with\r\n.This converts
abcdefg ab abcdefgh a abcdefghi abcde abcd abcinto
a ab abc abcd abcde abcdefg abcdefgh abcdefghi -
In case anyone comes across this topic looking for a way to sort lines by length, Columns++ release 1.0.1 can do this.
Select Sort… from the Columns++ menu and let it enclose the entire document in a rectangular selection (or make your own selection first).
Use Whole lines, Ascending or Descending as desired, and Width. You can then sort on Entire column, unless you wish to use one of the other options.
The sort is based on the on-screen width of text in the current font. Columns++ is meant to deal with data in columns using tabs, including elastic tabstops and proportionally-spaced fonts; I found that using the width, rather than a count of characters, was the most consistent way to deal with all the variations in a way that makes intuitive sense for users. For files using monospaced fonts and no tabs, the results are the same as counting characters.
-
@Mark-Olson , your proposed solution seems to be so easy but can you please elaborate more,
1- how to open the file in tree view
2- how to go to REGEX mode to enter the querymany thanks
-
@Mahmoud-Madkour
To open a tree view for a file inREGEXmode, just use theRegex search to JSONcommand from theJsonToolsplugin menu.
Once the tree view is open, you can paste the query into the text box at the top right corner of the tree view, and click theSubmit querybutton next to the text box.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login