Save found files?
-
@Ekopalypse said in Save found files?:
I’m testing this on 7.8.1
I still use 7.8 day-to-day so my previous results were with that. But…switching to 7.8.1 (64 bits) temporarily I do not see any change; meaning that I don’t see it working the way you do!
-
So before this thread was started earlier today, I had some Pythonscript code for manipulating text in the Find-result window (that I never really finished or did anything with):
import ctypes from ctypes.wintypes import BOOL, HWND, LPARAM import re class FindResultPanel(object): def __init__(self): WNDENUMPROC = ctypes.WINFUNCTYPE(BOOL, HWND,LPARAM) FindWindow = ctypes.windll.user32.FindWindowW GetWindowText = ctypes.windll.user32.GetWindowTextW GetWindowTextLength = ctypes.windll.user32.GetWindowTextLengthW SendMessage = ctypes.windll.user32.SendMessageW EnumChildWindows = ctypes.windll.user32.EnumChildWindows GetClassName = ctypes.windll.user32.GetClassNameW curr_class = ctypes.create_unicode_buffer(256) tag1 = 0 find_result_panel_scintilla_handle_list = [] def foreach_window(hwnd, lParam): tag2 = 1 if lParam == tag1: cc = curr_class[:GetClassName(hwnd, curr_class, 256)] if cc == u'#32770': length = GetWindowTextLength(hwnd) if length > 0: buff = ctypes.create_unicode_buffer(length + 1) GetWindowText(hwnd, buff, length + 1) if buff.value == u'Find result': EnumChildWindows(hwnd, WNDENUMPROC(foreach_window), tag2) elif lParam == tag2: cc = curr_class[:GetClassName(hwnd, curr_class, 256)] length = GetWindowTextLength(hwnd) if length > 0: buff = ctypes.create_unicode_buffer(length + 1) GetWindowText(hwnd, buff, length + 1) if cc == u'Scintilla': find_result_panel_scintilla_handle_list.append(hwnd) return False # stop enumeration return True # continue enumeration EnumChildWindows(FindWindow(u'Notepad++', None), WNDENUMPROC(foreach_window), tag1) try: hwnd = find_result_panel_scintilla_handle_list[-1] except IndexError: raise RuntimeError('No Find result window found') self.hwnd = hwnd # from Scintilla.iface ( https://github.com/notepad-plus-plus/notepad-plus-plus/blob/master/scintilla/include/Scintilla.iface ) # Retrieve a pointer value to use as the first argument when calling the function returned by GetDirectFunction. #get int GetDirectPointer=2185(,) self.direct_pointer = SendMessage(self.hwnd, 2185, 0, 0) def GetText(self): # https://www.scintilla.org/ScintillaDoc.html#SCI_GETTEXT # Retrieve all the text in the document. # Returns number of characters retrieved. # Result is NUL-terminated. #fun position GetText=2182(position length, stringresult text) # position -> intptr_t position in a document # stringresult -> pointer to character, NULL-> return size of result length_of_text = ctypes.WinDLL('SciLexer.dll', use_last_error=True).Scintilla_DirectFunction(self.direct_pointer, 2182, 0, 0) text_of_document = ctypes.c_char_p('\0' * (length_of_text + 1)) # allocate buffer to hold text ctypes.WinDLL('SciLexer.dll', use_last_error=True).Scintilla_DirectFunction(self.direct_pointer, 2182, length_of_text, text_of_document) return text_of_document.value def GetFoldLevel(self, line_number): # https://www.scintilla.org/ScintillaDoc.html#SCI_GETFOLDLEVEL # Retrieve the fold level of a line. #get FoldLevel GetFoldLevel=2223(line line,) SC_FOLDLEVELNUMBERMASK = 0x0FFF return ctypes.WinDLL('SciLexer.dll', use_last_error=True).Scintilla_DirectFunction(self.direct_pointer, 2223, line_number, 0) & SC_FOLDLEVELNUMBERMASK def GetFoldExpanded(self, line_number): # https://www.scintilla.org/ScintillaDoc.html#SCI_GETFOLDEXPANDED # Is a header line expanded? #get bool GetFoldExpanded=2230(line line,) return ctypes.WinDLL('SciLexer.dll', use_last_error=True).Scintilla_DirectFunction(self.direct_pointer, 2230, line_number, 0) try: find_result_panel = FindResultPanel() except RuntimeError: notepad.messageBox('Could not find Find-result window;\r\nMaybe you have not yet run a search that would create it?', '') else: find_result_text = find_result_panel.GetText() print_all = True if 0 else False copy_line_info_that_user_can_see = True if 0 else False copy_filepaths_that_user_can_see = True if 1 else False unique_filepaths_list = [] recent_start_expanded = True recent_filepath_expanded = True for (line_number, line_contents) in enumerate(find_result_text.splitlines()): if print_all: print(line_number, find_result_panel.GetFoldLevel(line_number), find_result_panel.GetFoldExpanded(line_number), line_contents) else: if line_contents.startswith('Search'): recent_start_expanded = True if find_result_panel.GetFoldExpanded(line_number) else False elif line_contents.startswith(' '): recent_filepath_expanded = True if find_result_panel.GetFoldExpanded(line_number) else False if copy_line_info_that_user_can_see: if line_contents.startswith('Search'): if waiting_for_start: pass elif copy_filepaths_that_user_can_see: if line_contents.startswith(' '): if recent_start_expanded: _ = re.sub(r'^\s+(.+?) \(\d+\shits?\)$', r'\1', line_contents) if _ not in unique_filepaths_list: unique_filepaths_list.append(_) if copy_filepaths_that_user_can_see: for _ in unique_filepaths_list: print(_)In this script, we see in the last line that there is something called
unique_filepaths_list.We can put this to use for the OP’s task by adding a bit more code at the bottom:
keep_going = True while keep_going: destination_dir = notepad.prompt('Enter destination directory:', 'Copy files with hits', '') if destination_dir == None: keep_going = False # cancel was pressed elif os.path.isdir(destination_dir): break if keep_going: from shutil import copy for source_file in unique_filepaths_list: try: copy(source_file, destination_dir) except: notepad.messageBox('Problem copying the file:\r\n"{}"\r\nto the folder:\r\n"{}"'.format(source_file, destination_dir), '')Running the code now (after doing a search that populates the Find-result window with the desired results) will result in the following popup prompt:
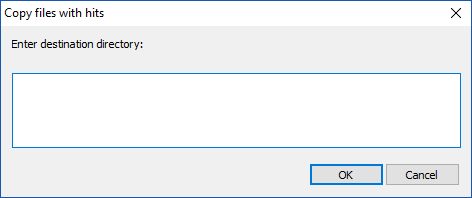
Putting a valid folder name in the box and pressing OK will complete the desired copy operation.
-
I probably also should add that the files copied by the script are going to be the disk copies of the files. Notepad++ does an in-memory search rather than a disk search when it produces its hit list. So if any of the hit files are dirty/modified/red-iconned when the search is conducted, the file contents that actually get copied are going to be different than the modified contents.
TL;DR: Save all Notepad++ files (so that none have red icons) before running the script – or when doing Eko’s originally suggested solution!
-
Hi, @ekopalypse, @alan-kilborn and All,
I did a quick test and I confirm that the Alan’s behavior seems to be the default one !
My configuration :
Notepad++ v7.8.1 (32-bit) Build time : Oct 27 2019 - 22:46:07 Path : D:\@@\781\notepad++.exe Admin mode : OFF Local Conf mode : ON OS Name : Microsoft Windows XP (32-bit) OS Build : 2600.0 Plugins : DSpellCheck.dll ExtSettings.dll mimeTools.dll NppConverter.dll NppExport.dll
-
A
Ctrl + Aaction ( or right-click on theSelect Alloption ), followed with anCtrl + Caction and, finally, aCtrl + Vaction, in a new tab, do copy all Find result contents. So your regex works fine, extracting the absolute pathnames of all the files involved in the search ! -
A
Ctrl + Aaction ( or right-click on theSelect Alloption ), followed with a right-click on theCopyoption and, finally, aCtrl + Vaction, in a new tab, only copy the lines, containing the matched string, from all the files scanned, in the Find result window
May be a plugin issue ?
Best Regards
guy038
-
-
@guy038 said :
May be a plugin issue ?
This is a good point. @Ekopalypse can you try testing this copy/paste behavior again with a very-clean 7.8.1?
-
@guy038 said in Save found files?:
-
A
Ctrl + Aaction ( or right-click on theSelect Alloption ), followed with anCtrl + Caction and, finally, aCtrl + Vaction, in a new tab, do copy all Find result contents. So your regex works fine, extracting the absolute pathnames of all the files involved in the search ! -
A
Ctrl + Aaction ( or right-click on theSelect Alloption ), followed with a right-click on the Copy option and, finally, aCtrl + Vaction, in a new tab, only copy the lines, containing the matched string, from all the files scanned, in the Find result window
I thought I would emphasize this to @Ekopalypse : the behavior is different depending on whether you use keystrokes or menu selection for the copy. I just replicated this on portable 7.8.1-64bit. If you use the
Ctrl+Ckeystroke, it copies the filename; if you useRClick > Copy, it only copies the lines, not the filenames. (I also confirmed that you cannot use File > Copy, because that’s using the active editor window, even when Find result is the foreground pane.) I pasted not only into Notepad++, but into other apps as well, confirming that it’s actually the copy-operation that’s different depending onCtrl+CvsRClick > Copy.I went back to my 7.7.1-64bit, and it behaves the same way, with
Ctrl+CvsRClick > Copyhaving separate behavior. -
-
@PeterJones said:
(I also confirmed that you cannot use File > Copy, because that’s using the active editor window, even when Find result is the foreground pane.)
Presume you meant:
(I also confirmed that you cannot use Edit > Copy, because that’s using the active editor window, even when Find result is the foreground pane.)
-
I’m still a little bit confused as it seems to work most of the time like Peter described
but sometimes it doesn’t, means I don’t get the filename lines copied into clipboard.
Using a fresh portable 7.8.1 x64 version. Need to do further tests to see if I can find
a reproducible way. -
@Alan-Kilborn FANTASTIC! Thank you so much, it works perfectly. My colleague and I are delighted. :))
Thank you other guys as well.
Awesome forum.
-
My script code has a .getText function on the FindResultPanel object.
With it I can, obviously, get the text of the Find-result window.
However, I’d like to be able to get the matching text, but I don’t know how to accomplish this.
Visually, I can see the hit results in the window as red text on a yellow background.
Anyone know how I can pull this information? -
Why not using the styling information to identify the matched text?
-
@Ekopalypse said in Save found files?:
Why not using the styling information to identify the matched text?
Well, TBH when I earlier went searching in the N++ source code for
SCE_SEARCHRESULT_*, I saw no occurrences ofSCE_SEARCHRESULT_WORD2SEARCHoccurring at all, so I was confused as to how it worked and was thinking it might not be possible at all to get this info via PS, even with ctypes usage.But with some experimentation with
SCI_GETSTYLEATit seems that I can recall the info; for example, in my “hit” text I get a style result of 4, which is indeedSCE_SEARCHRESULT_WORD2SEARCH.Is N++ source using hardcoded magic numbers for this instead of the “tags”, or some other mechanism that is strange or at least isn’t clear to me?
Hmm, had a thought to search the Scintilla part of N++, where I do see
SCE_SEARCHRESULT_WORD2SEARCHused. That must be how it is done. -
BTW, I’m still confused after looking at N++ source on how N++ identifies the hit text, so that the “search result” lexer knows where it is, so if you can shed any light on that… if you’re sufficiently interested in doing so… :-)
-
Is N++ source using hardcoded magic numbers for this instead of
Not sure I understand the question correctly.
Every lexer has hard coded style ids, which then get mapped
with a color via stylers.xml. See searchResult.how N++ identifies the hit text
It uses an internal struct MarkingsStruct which seems to be filled and provided
as a property to the document. Maybe something you can use to your advantage? -
Sorry, Forgot to include the structure reference.
-
Made me a bit of a headache because I assumed that the pointer was an integer data type
but the npp code actually said that it was a const char pointer.
In short, here’s a python script that can determine the positions of the matches.I leave the changes from py3 to py2 to you :-)
class SearchResultMarking(ctypes.Structure): _fields_ = [('_start', ctypes.c_long), ('_end', ctypes.c_long)] class SearchResultMarkings(ctypes.Structure): _fields_ = [('_length', ctypes.c_long), ('_markings', ctypes.POINTER(SearchResultMarking))] # const char *addrMarkingsStruct = (styler.pprops)->Get("@MarkingsStruct"); addrMarkingsStruct = f_editor.getProperty("@MarkingsStruct").encode() # SearchResultMarkings* pMarkings = NULL; pMarkings = ctypes.pointer(SearchResultMarkings()) # sscanf(addrMarkingsStruct, "%p", (void**)&pMarkings); ctypes.cdll.msvcrt.sscanf(addrMarkingsStruct, b"%p", ctypes.byref(pMarkings)) for i in range(pMarkings.contents._length): print(f'line {i} start:{pMarkings.contents._markings[i]._start} - end:{pMarkings.contents._markings[i]._end}') -
@Ekopalypse said in Save found files?:
I leave the changes from py3 to py2 to you
Not a big burden, only the “print” line for that…
But…What’s your magic behind
f_editor? Instead of that I would have expected something like what I did in the earlier code I posted in this thread; something much messier, like:ctypes.WinDLL('SciLexer.dll', use_last_error=True).Scintilla_DirectFunction(self.direct_pointer, 2182, length_of_text, text_of_document)``` but using a different number than `2182` and different parameters, of course... -
Not a big burden, only the “print” line for that…
and the encode is not needed as py2 returns bytes
as well as the b before the “%p”.But…What’s your magic behind f_editor?
Nothing, this is just my object which represents the editor in the find in files window.
As you said, what you would have expected must be done on your side.