Very difficult find and replace in glossary
-
I am trying to fix a glossary that did not import right to my text expansion program that I use for Medical Transcription and hoping that it can be done with notepad++.
The glossary is tab delimited from the short(the first text of the line) and what I am trying to do is change these lines.
adden ADDENDUM" display="ADDENDUM first line - pend to FHAK
To
adden <displayform>ADDENDUM first line - pend to FHAK</displayform>ADDENDUMAny help is So Greatly appreciated. I hope I explained this as to not confuse anyone.
Thank You! -
It’s looking like your data got mangled. Please re-post the data in a reply, this time highlight the data and click the
</>button in the editor window. It should end up likeadden ADDENDUM" display="ADDENDUM first line - pend to FHAKand
adden <displayform>ADDENDUM first line - pend to FHAK</displayform>ADDENDUMWhile you’re doing that, you might also read the paragraphs I quote below, because it will help you better define your data. A single line is rarely enough to write a good regular expression, because with a single line, someone could just say find what =
adden ADDENDUM" display="ADDENDUM first line - pend to FHAK, replace with =adden <displayform>ADDENDUM first line - pend to FHAK</displayform>ADDENDUM, with search mode=normal, and that would technically match what you asked for. It’s best to give multiple representative lines that you want changed, plus some lines that you don’t want changed, so we can better understand what your data really looks like, and write a meaningful regex that will meet your needs. Further, showing an effort (both in what data you present, and showing what you’ve already tried) will indicate that you are willing to do your part, and really want to learn, rather than just asking us to do your job for you.-----
Please Read And Understand This
FYI: I often add this to my response in regex threads, unless I am sure the original poster has seen it before. Here is some helpful information for finding out more about regular expressions, and for formatting posts in this forum (especially quoting data) so that we can fully understand what you’re trying to ask:
This forum is formatted using Markdown. Fortunately, it has a formatting toolbar above the edit window, and a preview window to the right; make use of those. The
</>button formats text as “code”, so that the text you format with that button will come through literally; use that formatting for example text that you want to make sure comes through literally, no matter what characters you use in the text (otherwise, the forum might interpret your example text as Markdown, with unexpected-for-you results, giving us a bad indication of what your data really is). Images can be pasted directly into your post, or you can hit the image button. (For more about how to manually use Markdown in this forum, please see @Scott-Sumner’s post in the “how to markdown code on this forum” topic, and my updates near the end.) Please use the preview window on the right to confirm that your text looks right before hitting SUBMIT. If you want to clearly communicate your text data to us, you need to properly format it.If you have further search-and-replace (“matching”, “marking”, “bookmarking”, regular expression, “regex”) needs, study the official Notepad++ searching using regular-expressions docs, as well as this forum’s FAQ and the documentation it points to. Before asking a new regex question, understand that for future requests, many of us will expect you to show what data you have (exactly), what data you want (exactly), what regex you already tried (to show that you’re showing effort), why you thought that regex would work (to prove it wasn’t just something randomly typed), and what data you’re getting with an explanation of why that result is wrong. When you show that effort, you’ll see us bend over backward to get things working for you. If you need help formatting, see the paragraph above.
Please note that for all regex and related queries, it is best if you are explicit about what needs to match, and what shouldn’t match, and have multiple examples of both in your example dataset. Often, what shouldn’t match helps define the regular expression as much or more than what should match.
-
@Scott-Smith-0 said in Very difficult find and replace in glossary:
I am trying to fix a glossary that did not import right to my text expansion program that I use for Medical Transcription and hoping that it can be done with notepad++.
The glossary is tab delimited from the short(the first text of the line) and what I am trying to do is change these lines.My Explanation of what I actually need. I have 474 replacements that I need to make.
The display= part goes between the <displayform> and </display form> and the expansion word goes to the end of </displayform>.pool pool" display="pool - ctrl-shift-Pto
pool <displayform>pool - ctrl-shift-P</displayform>poolanother example…
adden ADDENDUM" display="ADDENDUM first line - pend to FHAKto
adden <displayform>first line - pend to FHAK</displayform>ADDENDUM
-
You’re still not doing a good job of explaining it, but I think I might understand. Your data is in the form
SHORTNAME spaces SOMETHING quotemark space-display-equal quotemark SOMETHING space CONTENTS, and you want to transform it toSHORTNAME spaces <displayform>CONTENTS</displayform>SOMETHING. Assuming that’s the rule: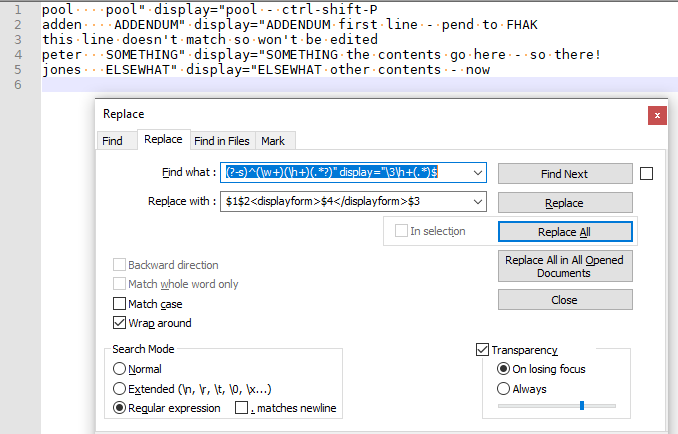
- FIND =
(?-s)^(\w+)(\h+)(.*?)" display="\3\h+(.*)$ - REPLACE =
$1$2<displayform>$4</displayform>$3 - MODE = regular expression
Original data:
pool pool" display="pool - ctrl-shift-P adden ADDENDUM" display="ADDENDUM first line - pend to FHAK this line doesn't match so won't be edited peter SOMETHING" display="SOMETHING the contents go here - so there! jones ELSEWHAT" display="ELSEWHAT other contents - nowFinal data:
pool <displayform>- ctrl-shift-P</displayform>pool adden <displayform>first line - pend to FHAK</displayform>ADDENDUM this line doesn't match so won't be edited peter <displayform>the contents go here - so there!</displayform>SOMETHING jones <displayform>other contents - now</displayform>ELSEWHATHmm, this doesn’t match on the
poolline… I still obviously don’t understand your rules, because in thepoolline, you put thepoolwrapper both after the<displayform>and after the</displayform>, whereas in theaddenexample in your recent post, you only put theADDENDUMafter the</displayform>, and I don’t see how to decide between the two; going back to your original example, theADDENDUMdid come both after the<displayform>and after the</displayform>. If that’s really what you want, then change to- REPLACE =
$1$2<displayform>$3 $4</displayform>$3,
which will have final data of
pool <displayform>pool - ctrl-shift-P</displayform>pool adden <displayform>ADDENDUM first line - pend to FHAK</displayform>ADDENDUM this line doesn't match so won't be edited peter <displayform>SOMETHING the contents go here - so there!</displayform>SOMETHING jones <displayform>ELSEWHAT other contents - now</displayform>ELSEWHATIf the number of spaces between SOMETHING and CONTENTS is also important, then you can capture those spaces into a separate group, which will renumber some of the above groups
- find=
(?-s)^(\w+)(\h+)(.*?)" display="\3(\h+)(.*)$ - replace =
$1$2<displayform>$3$4$5</displayform>$3
pool pool" display="pool - ctrl-shift-P adden ADDENDUM" display="ADDENDUM first line - pend to FHAK this line doesn't match so won't be edited peter SOMETHING" display="SOMETHING the contents go here - so there! jones ELSEWHAT" display="ELSEWHAT other contents - now spaces WHITESPACE" display="WHITESPACE lots of prefix spacesbecomes
pool <displayform>pool - ctrl-shift-P</displayform>pool adden <displayform>ADDENDUM first line - pend to FHAK</displayform>ADDENDUM this line doesn't match so won't be edited peter <displayform>SOMETHING the contents go here - so there!</displayform>SOMETHING jones <displayform>ELSEWHAT other contents - now</displayform>ELSEWHAT spaces <displayform>WHITESPACE lots of prefix spaces</displayform>WHITESPACE - FIND =
-
@PeterJones, I really appreciate your help with this.
I actually do a lot of code… mostly PHP and have been trying to get the Regex down for a while now for PHP. It is for some reason a little overwhelming sometimes.
With your help I got 102 lines fixed and played with your code a little and got the rest with this.find = (?-s)^(\w+)(\h+)(.*?)" display="(.*) replace = $1\t<displayform>$4</displayform>$3Thank You
-
Great! I’m glad you were able to tweak it to make it work better. Seeing occasional feedback like yours makes up for the many people who just change their requirements 3-5 times until they get one of us to give them a regex that “works”, and then leave. (It also helps on a day like today, when the job that pays my bills is not going well, it’s good to know that at least my free relaxation efforts are doing some good in the world.)
I’m sorry that I had trouble understanding what you were asking for. The one copy of
ADDENDUMvs two copies ofpoolconfused me.For future hints, the way I usually break down trying to figure out a regex:
- Compare what portions of each line I want to match is identical to every other one (“constants”), and what parts do I want to allow to be different in each line (“variables”) but still be part of the match.
- Look at both the variables and constants, and see what portions of each I’ll want to keep or move around, vs which parts get thrown away completely. Each sub-component that I want to keep will be put in a regex group. Anything that gets completely thrown away doesn’t need to be in a group, though sometimes I put it in a numbered
(___)or unnumbered(?:___)group anyway, if I have a good reason for it. Anything that needs to be split apart, I break into multiple groups, instead of having it as one group. - For each group, I do a mental “how would I describe to my son how to correctly match these characters?” – which should hopefully give me a simple, foolproof algorithm of characters that must match or must not match; then I ask, “how would I translate those instructions into regex sequences?” If I don’t know the answer to the second, I read documentation, or ask a specific question.
- try it, debug, iterate
(I’m actually going to start including that four-step procedure into my boilerplate.)
-
Hello, @scott-smith-0, @peterjones and All,
Just a clarification about greedy and lazy quantifiers :
Imagine the following regex, using the free-spacing mode for a better readability :
(?x) \w+? ABC test ABCYou may think that we must use the lazy quantifier
+?, in order to get the first occurrence of the stringABC. But, it’s a common mistake of reasoning !Indeed, in fact, the regex are looking for the shortest range of word characters, followed with the string
ABCtestABCEasy to prove :
-
Against the text XYZ 12345ABCtestABCdefghiABCtestABCjklmn the regex
\w+?ABCtestABCdoes match the string 12345ABCtestABC, whereas the regex\w+ABCtestABCmatches the string 12345ABCtestABCdefghiABCtestABC. Given this subject text, the difference between the two kinds of quantifiers is obvious ! -
Now, against the shorter text XYZ 12345ABCtestABCdefghi, as there is only
1occurrence of the string ABCtestABC, you don’t have to bother about lazy vs greedy quantifiers ! Both, the regexes\w+?ABCtestABCand\w+ABCtestABCwill match the same string12345ABCtestABC
Of course, had we used the simple regexes
\w+?ABCand\w+?ABC, the matched strings would have been quite distinct !
Now, let’s imagine :
-
The subject text XYZ 12345" display="defghi, where I replaced the two strings
ABCwith a double-quote"and the word test with <sp>display= -
The regex
\w+?" display="
In this specific case, there an additional reason why the lazy quantifier is useless ;-))
Indeed, if you think, wrongly, at first sight, that this quantifier is needed in order to get the first
"symbol, it could not match a further bunch of chars as, both, the double-quote and the following space character are not word characters, anyway !Just try the two regexes
\w+?" display="and\w+" display=", against the following text :XYZ 12345" display=“defghi” display="jklmn
In both cases, the matched string is just 12345" display="
Best Regards,
guy038
Reminder : for correct tests, replace any
“and”quoting characters with a classic double-quote char"(\x{0022}) -
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login