Regex: check for a specific word/string across multiple files, then insert a string below
-
Hello,
I have blocks of dialogue lines reoccurring hundreds of times across many files, and I want to insert the same word pattern of Name-linebreak-quotationmarks:Pucchi ""in the same specific place: in the empty line between TRANSLATION and END STRING.
ぷっち 「いいなぁ。ほしいなぁ。」 # TRANSLATION # END STRINGafter reading up on regex a little, I tried to search and replace for
ぷっち[^"]*TRANSLATIONbut that’s clearly not working and just cannibalizes everything nearby. What’s a regex search that correctly identifies the name above the 「 bracket and then inserts the word on the next empty line between TRANSLATION and END STRING?
So that this:
# TEXT STRING # UNTRANSLATED # CONTEXT : Dialogue/Message/FaceUnknown # ADVICE : 49 char limit (35 if face) ぷっち 「いいなぁ。ほしいなぁ。」 # TRANSLATION # END STRING # TEXT STRING # UNTRANSLATED # CONTEXT : Dialogue/Message/FaceUnknown # ADVICE : 49 char limit (35 if face) 初期ぷっち 「わぅーん♪」 # TRANSLATION # END STRINGturns into this:
# TEXT STRING # UNTRANSLATED # CONTEXT : Dialogue/Message/FaceUnknown # ADVICE : 49 char limit (35 if face) ぷっち 「いいなぁ。ほしいなぁ。」 # TRANSLATION Pucchi “” # END STRING # TEXT STRING # UNTRANSLATED # CONTEXT : Dialogue/Message/FaceUnknown # ADVICE : 49 char limit (35 if face) 初期ぷっち 「わぅーん♪」 # TRANSLATION # END STRINGwithout destroying any nearby lines which also contain END STRING, but start with a different name.
Cheers
-
@juon2nd said in Regex: check for a specific word/string across multiple files, then insert a string below:
inserts the word on the next empty line between TRANSLATION and END STRING?
First off, welcome to the NPP forum. You almost had it. Your find text was correct in so far as it works. In order to add in additional text, once you select something with the find text you need to return that text otherwise it will be removed.
So my idea of the replace function is:
Find What:(ぷっち[^"]*TRANSLATION\h*\R)(\R)
Replace With:\1Pucchi\2""\2Notice I extended what your find text selects and also put brackets around them. This is what we call a “capture” group. Using this allows us to identify it in the replace text field to return it.
Have a go with my answer and see if that helps. Remember to have a backup of the file just in case it doesn’t work.
Terry
-
Hello,
thanks for the quick reply, but that didn’t work for me, since it finds too much text and indiscriminately inserts the dialogue string into any empty space instead the ones I want, see attached pic:
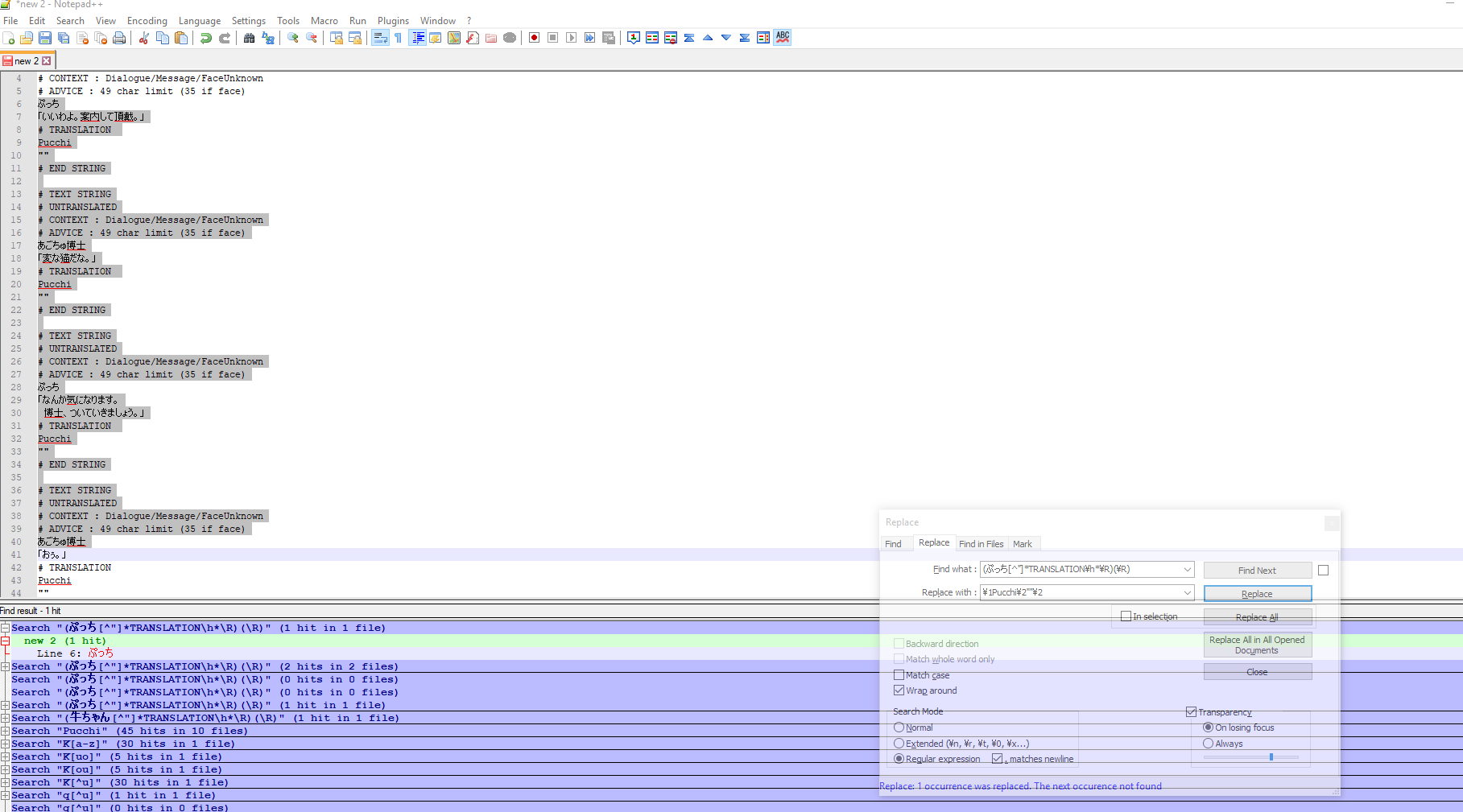
(instead of a backslash there’s a yen symbol because of Japanese system locale, not sure if that is a problem)Is the problem maybe that the text contains a Japanese bracket「」?
cheers
-
@juon2nd said in Regex: check for a specific word/string across multiple files, then insert a string below:
but that didn’t work for me, since it finds too much text
Sorry about that, I didn’t have multiple instances of the text to search. That meant your original find text was ALSO selecting too much text.
Try this (I did a bit more testing this time).
Find What:(?-i)^(ぷっち(\R.*){2}TRANSLATION\h*\R)(\R)
Replace With:\1Pucchi\3""\3Note again more characters in the find what field. I added the
^near the start so that it forces looking for that text only at the START of a line, not as a subset of any other (your example should those characters as a subset of the next one).
Also the Replace field had some changes as a result. Let us know if this helps.Terry
-
@Terry-R said in Regex: check for a specific word/string across multiple files, then insert a string below:
Find What:(?-i)^(
Your regex had an inherent “failure” that I temporarily forgot about, I’m going to say it was because I was in awe of the “weird” characters. Actually the
[^"]is a dangerous piece of coding. It would appear you do know something about regexes, however this piece of coding has a hidden side to it.You will note I included a
(?-i), actually that was also wrong it should have been(?-s)which means the.can be any character EXCEPT an ‘end of line marker’. However the[^"]saysanything EXCEPT "and that includes an end of line marker. In your regex this allowed it to select multiple lines unchecked.So my amended answer is
Find What:(?-s)^(ぷっち(\R.*){2}TRANSLATION\h*\R)(\R)
Replace With:\1Pucchi\3""\3Terry
-
@Terry-R
actually I really don’t know jack about regex except what I’ve learned by looking at a tutorial for only 1 hour - so processing all you’ve said is tough for me.
The last regex you’ve provided got me very close to the goal, but in this example it doesn’t catch the lower text block - is it because the brackets are on two different lines?
「なんか気になります。
博士、ついていきましょう。」Here’s highlighted text from editpad for comparison’s sake, showing that only the above block is matched by the regex
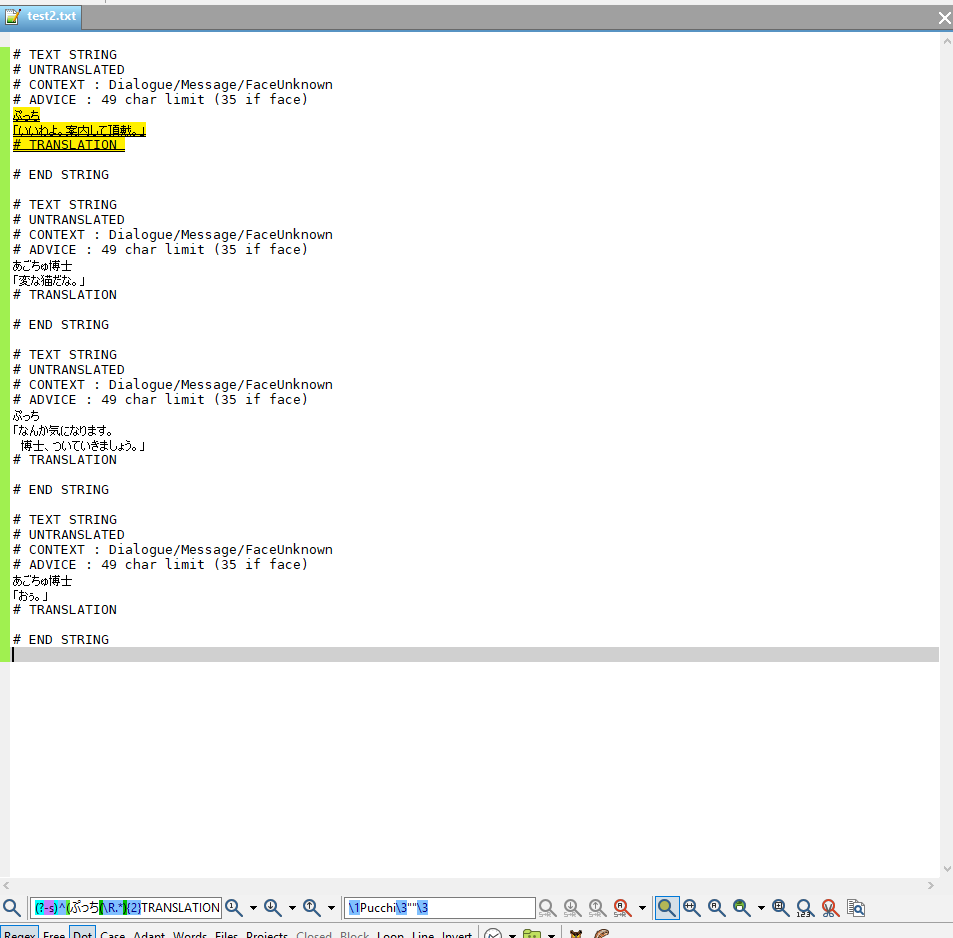
I’m out of time now but I will try again tomorrow. Thanks so far.
-
Since the latest screenshot doesn’t appear to be Notepad++, this thread has truly devolved into something that should be on a regex forum rather than here?
-
@juon2nd said in Regex: check for a specific word/string across multiple files, then insert a string below:
what I’ve learned by looking at a tutorial for only 1 hour
Right, yes there were some unknowns, one being how many lines those “weird” brackets used up. From the latest info you provided they may be spread over several lines. That involves an almost complete redesign of my regex.
I will explain the regex (broken down) as best I can in the hope you can alter any minor issues you find in the next test.Find What:
(?s-i)^ぷっち.*?(?=TRANSLATION)\K(TRANSLATION\h*\R)(\R)
Replace With:\1Pucchi\2""\2The
(?s-i)states we will accept “end of line” markers with a.and the-imeans a non-insensitive’ test. So ‘TRANSLATION’ is NOT equal to ‘translation’.
^ぷっちmeans find these characters at the start of a line
.*?(?=TRANSLATION)means (along with the(?s) any characters but non-greedily so long as we stop when we see TRANSLATION directly ahead.
\Kmeans we forget any characters we previously searched for and possibly captured. This allows us to recommence our search again.
(TRANSLATION\h*\R)(\R)this is the REAL search we want, we capture those parts we wish to return in the replace with field with the additional text.Terry
-
Hi, @juon2nd, @Terry-r, @alan-kilborn and All,
An alternate generic regex S/R could be :
SEARCH
(?x-i) ^Your Japanese Expression\R (?s:「.+?」)\R \#\h*TRANSLATION\h*(\R)REPLACE
$0Your translation\1""
which gives, for your specific example, the following S/R :
SEARCH
(?x-i) ^ ぷっち\R (?s:「.+?」)\R \#\h*TRANSLATION\h*(\R)REPLACE
$0Pucchi\1""Notes :
-
The first part
(?x-i)is a shorthand of(?x)(?-i), two in-line modifiers which mean :-
Any subsequent space char is not taken in account for the overall regex and any range after a
#char is considered as a comment, independent of the overall regex, too ! ((?s)) -
The search is processed in a non-insensitive way (
(?-i))
-
-
The
^assertion matches a beginning of line -
Then,
ぷっち\Ris your Japanese expression, followed with its line-break -
Now the
(?s:「.+?」)\Rpart is a non-capturing group containing the shortest range, even in multi-lines, of any character, even EOL ones, between a left and a right corner brackets, followed with its line-break -
Finally the part
\#\h*TRANSLATION\h*(\R)looks for a literal#char, followed with possible horizontal blank characters ( Tab, Space ), then the string TRANSLATION, with this exact case and ending with possible blank chars, again and a line-break, stored as group1, due to the surrounding parentheses -
In replacement, we rewrite the
$0part, which represents the overall regex, so all lines from the line, located above the CJK brackets line till the entire line # TRANSLATION -
Then the part
Pucchi\1adds your translation string Pucchi, followed with a line-break ( group1)
Finally, the part
""just writes two consecutive double quotes characters. No need for an extra line-break, which already exists ( the empty line between the lines # TRANSLATION and # END STRING )Best Regards,
guy038
-
-
Thank you, thank you, thank you! Terry’s last solution did the trick. Thanks for the elaborate explanations, I’ll learn more about regex later when I have the time, for now by doing this simple search I killed at least a thousand times of repetitive CTRL V and can smoothly proceed with my translation.
Cheers
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login