Copy, search and replace between 2 HTML files
-
Dear experts,
I am a newbie with Notepad++. So, I am sorry if my question makes you boring.
I have to HTML files (named a, b). There is a text phrase “ABC” in file a and this appears in many places (1000 times). There are 1000 different text phrases (one per line) in HTML file b and they are in order from 1 to 1000. My question is how to automatically copy text from file b and replace in file a by a macro. For more details as the followings:- Copy line 1 in file b.
- Search for text “ABC” in file a.
- Replace “ABC” by paste.
- It loops 1000 times.
I greatly appreciate your help.
Bests,
Kosmos
-
Hello, @hientwi and All,
Just a first try to verify if I correctly understood your needs !
Let’s suppose we have two files
AandB, containing, each,5lines-
First, we paste the contents of file
Ain a new N++ tab -
Secondly, we write a separation line, with, at least, three consecutive equal signs, so the minimum string
===, in the new tab -
Finally, we append the contents of file
B, in the new N++ tab
Then, for instance, we get the following input text :
First line of file A with text ABC Text ABC in the second line of file A File A : Third line with ABC text Fourth text ABC of line 4 in file A ABC = contents of last line 5 of file A === -- The Line 1 contents ( File B ) -- -- The Line 2 contents ( File B ) -- -- The Line 3 contents ( File B ) -- -- The Line 4 contents ( File B ) -- -- The Line 5 contents ( File B ) --By running the regex S/R, below :
-
SEARCH
(?-si)ABC(?=.*\R(?s:.+?\R){5}(.+))|(?s)===.+ -
REPLACE
?1\1 -
The
Wrap optionoption ticked and theRegular expressionsearch mode chosen -
A click on the
Replace Allbutton
We get the output text, below :
First line of file A with text -- The Line 1 contents ( File B ) -- Text -- The Line 2 contents ( File B ) -- in the second line of file A File A : Third line with -- The Line 3 contents ( File B ) -- text Fourth text -- The Line 4 contents ( File B ) -- of line 4 in file A -- The Line 5 contents ( File B ) -- = contents of last line 5 of file AAs you can see, the string
ABC, in the first five lines of fileA, in the input text, have been replaced, in the output text, by, successively, the last five lines of fileB
Are you expecting this kind of search/replacement ?
See you later,
guy038
-
-
@guy038 said in Copy, search and replace between 2 HTML files:
?1\1
Hallo @guy038 ,
Thank you very much for your quick support. Your solution is exactly what I wanted to have. But, I have played with my files but it did not work out and I could not get the same result as yours. So, I would like to make my question is clearer.
My file a have 895 “KOSMOS” and they are placed in a single line. And, this is the first one.
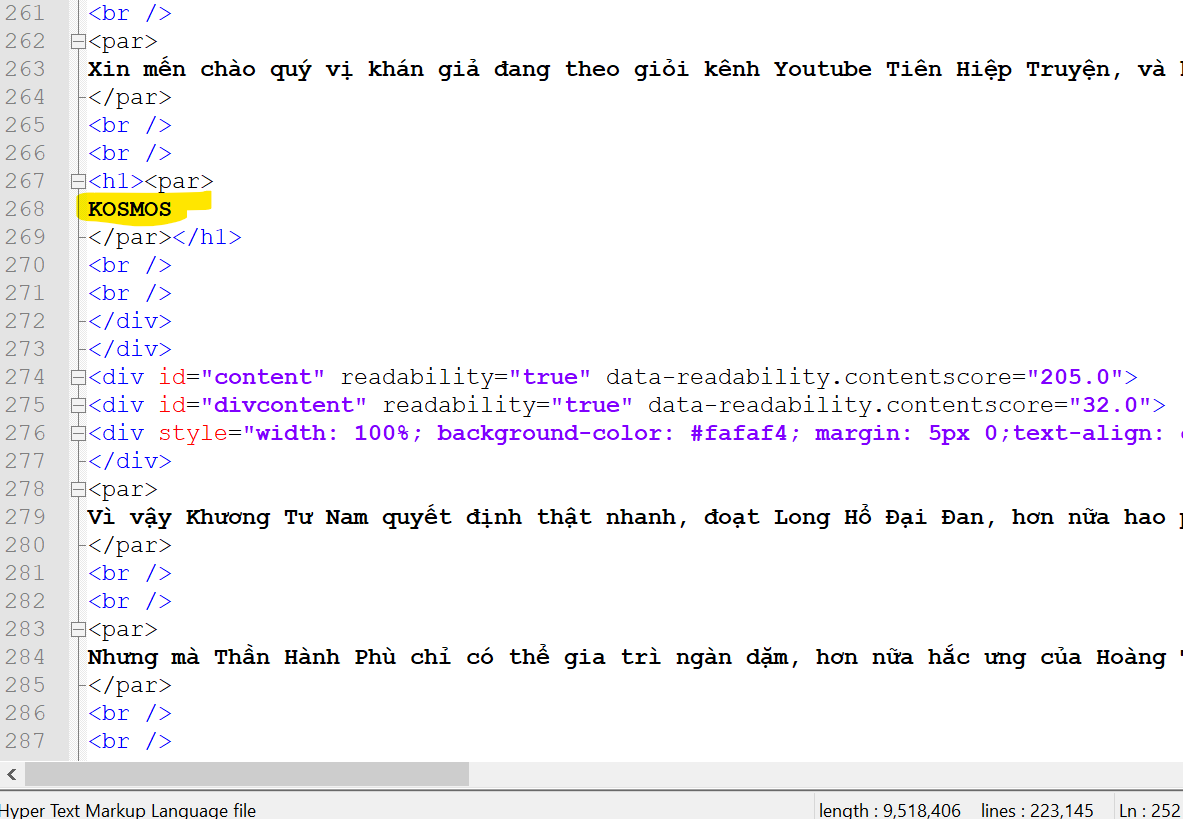
So, I would like to replace the first “KOSMOS” by the file line in my file b.
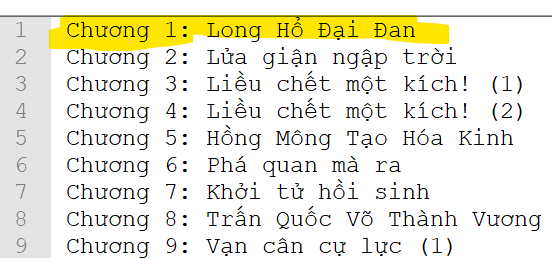
And then, it will repeat the procedure until the last “KOSMOS” with line 895 in file b.
So,…
- I copy the content of file a started from first “KOSMOS” and end with the last KOSMOS one, then I pasted to a new tab.
- I appended this new tab with 895 lines from file b.
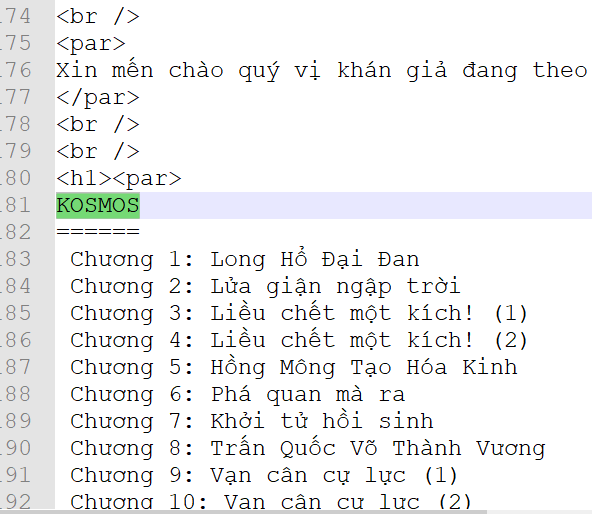
- I followed your instructions but I could not the expected results.
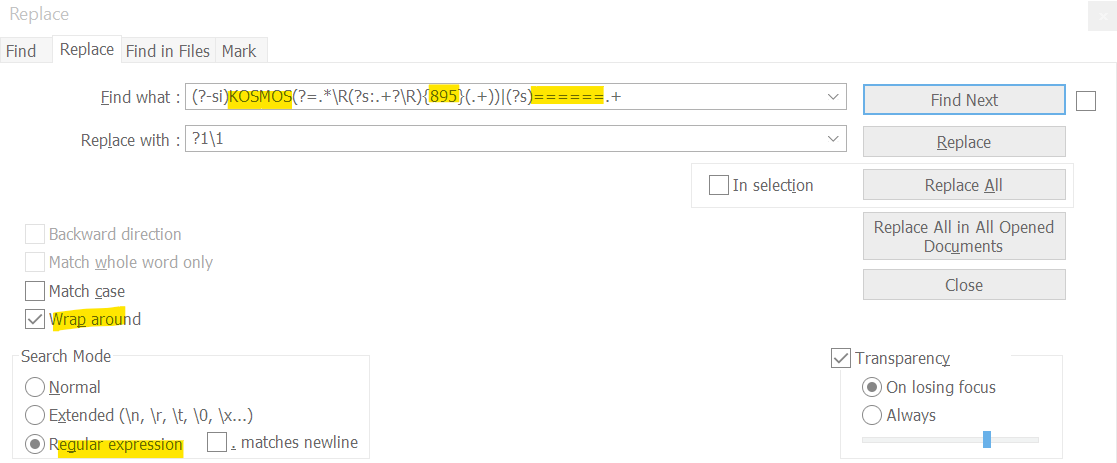
In my opinion, the problem could be the number of lines of file a-copied content does not exactly match to file b. However, I am not so sure and I also do not have any idea to deal with it.
Could you please give me a suggestion?
Many thanks in advance!
Kosmos -
@HienTwi said in Copy, search and replace between 2 HTML files:
In my opinion, the problem could be the number of lines of file a-copied content does not exactly match to file b. However, I am not so sure and I also do not have any idea to deal with it.
Hi @hientwi, All,
I don’t know if that is actually the cause of the failure, but you can easily check how many instances of “
KOSMOS” are in file A. To get it, please go to the very beginning offile A, open theFind window, type “KOSMOS” in theFind boxand click onCount. Look for the number of matches at thebottom of the Find window. -
Hi, @hientwi and All,
Ah…, of course, It cannot work because, there are a random number of lines between each
KOSMOSline ! So, here is an other method which should work fine, although it contains numerous steps ;-))To begin with, from your pictures, I noticed that your file
Acontains223,145lines and I assume that your fileBcontains895lines onlyOK, let’s go !
- Open your two files
AandBin Notepad++
Let’s suppose the following file
A, containing only5lines KOSMOS, among the223,145lines of fileA, then the input text :Line 1 Line 2 Line 3 KOSMOS Line 5 KOSMOS Line 7 KOSMOS Line 9 ..... ..... ..... ..... Line 223,139 KOSMOS Line 223,141 Line 223,142 KOSMOS Line 223,144 Line 223,145-
Open the Column Editor`
-
Select
Number to Insert -
Type in
1in the following three zones -
Tick the
Leading zerosoption -
Verify the
Decformat -
Click on the
OKbutton
-
You should get :
000001Line 1 000002Line 2 000003Line 3 000004KOSMOS 000005Line 5 000006KOSMOS 000007Line 7 000008KOSMOS 000009Line 9 xxxxxx..... xxxxxx..... xxxxxx..... xxxxxx..... 223139Line 223,139 223140KOSMOS 223141Line 223,141 223142Line 223,142 223143KOSMOS 223144Line 223,144 223145Line 223,145-
Now open the Mark dialog (
Search > Mark...option )-
SEARCH
(?-i)KOSMOS -
Option
Bookmark lineticked -
Option
Purge for each searchticked, preferably -
Option
Wrap aroundticked -
Mode
Regular expressionselected -
Click on the
Mark All
-
=> The
895linesKOSMOSshould be bookmarked-
Then, run the option
Search > Bookmark > Copy bookmarked Lines -
Now, select your File
Btab, containing also5lines, which will replace each KOSMOS line of fileA
-- The Line 1 contents ( File B ) -- -- The Line 2 contents ( File B ) -- -- The Line 3 contents ( File B ) -- -- The Line 4 contents ( File B ) -- -- The Line 5 contents ( File B ) ---
After the
895lines of fileB, add a separation line with, at least,3consecutive equal signs, so the string===with a line-break -
Then paste the contents of the clipboard, with
Ctrl + V( so the895lines KOSMOS of fileA)
Thus, the contents of file
Bshould contain895lines before the===: line and895after (5, in our example )-- The Line 1 contents ( File B ) -- -- The Line 2 contents ( File B ) -- -- The Line 3 contents ( File B ) -- -- The Line 4 contents ( File B ) -- -- The Line 5 contents ( File B ) -- === 000004KOSMOS 000006KOSMOS 000008KOSMOS 223140KOSMOS 223143KOSMOS-
Perform the following regex S/R, in the Replace dialog (
Ctrl + H)-
SEARCH
(?-si).+(?=\R(?s:.+?\R){5}(.+))|(?s)===.+( Of course, use the quantifier{895}, instead of{5}, with your present fileB) -
REPLACE
?1\1$0 -
Option
Wrap aroundticked andRegular expressionselected -
Click on the
Replace Allbutton
-
After
895replacements (5, in our example ), we get, at once, the following text :000004KOSMOS-- The Line 1 contents ( File B ) -- 000006KOSMOS-- The Line 2 contents ( File B ) -- 000008KOSMOS-- The Line 3 contents ( File B ) -- 223140KOSMOS-- The Line 4 contents ( File B ) -- 223143KOSMOS-- The Line 5 contents ( File B ) ---
Then select all the contents of file
B, withCtrl + A -
Copy it into the clipboard, with
Ctrl + C -
Select the file
Atab -
Paste the clipboard contents, after the last line of file
A, withCtrl + V
=> So, the file
Acontents are as below :000001Line 1 000002Line 2 000003Line 3 000004KOSMOS 000005Line 5 000006KOSMOS 000007Line 7 000008KOSMOS 000009Line 9 xxxxxx..... xxxxxx..... xxxxxx..... xxxxxx..... 223139Line 223,139 223140KOSMOS 223141Line 223,141 223142Line 223,142 223143KOSMOS 223144Line 223,144 223145Line 223,145 000004KOSMOS-- The Line 1 contents ( File B ) -- 000006KOSMOS-- The Line 2 contents ( File B ) -- 000008KOSMOS-- The Line 3 contents ( File B ) -- 223140KOSMOS-- The Line 4 contents ( File B ) -- 223143KOSMOS-- The Line 5 contents ( File B ) --- Now, sort the lines of file
A, with the optionEdit Line operations > Sort Lines Lexicographically Ascending
We get the following output :
000001Line 1 000002Line 2 000003Line 3 000004KOSMOS 000004KOSMOS-- The Line 1 contents ( File B ) -- 000005Line 5 000006KOSMOS 000006KOSMOS-- The Line 2 contents ( File B ) -- 000007Line 7 000008KOSMOS 000008KOSMOS-- The Line 3 contents ( File B ) -- 000009Line 9 xxxxxx..... xxxxxx..... xxxxxx..... xxxxxx..... 223139Line 223,139 223140KOSMOS 223140KOSMOS-- The Line 4 contents ( File B ) -- 223141Line 223,141 223142Line 223,142 223143KOSMOS 223143KOSMOS-- The Line 5 contents ( File B ) -- 223144Line 223,144 223145Line 223,145Finally, run this last regex S/R :
-
SEARCH
(?-is)^\d{6}|\h*KOSMOS\h*\R? -
REPLACE
Leave EMPTY
Here we are ! We have the expected output, below :
Line 1 Line 2 Line 3 -- The Line 1 contents ( File B ) -- Line 5 -- The Line 2 contents ( File B ) -- Line 7 -- The Line 3 contents ( File B ) -- Line 9 ..... ..... ..... ..... Line 223,139 -- The Line 4 contents ( File B ) -- Line 223,141 Line 223,142 -- The Line 5 contents ( File B ) -- Line 223,144 Line 223,145
If OK, I’ll explain the regexes syntax, next time !
See you later,
Best Regards,
guy038
- Open your two files
-
Hi @guy038 and all,
Definitely, it works perfectly with @guy038 smart solution. Many many many thanks for your solution which helps me a lots to save my time. It would be really nice if you can explain the regexes syntax, when you have free time!
In addition, I want to split file A into 895 files based on “KOSMOS”. Could you please give me a further favor? For instances,
file 1: From the very beginning of file A to the first KOSMOS, but not include it.
file 2: From the 1st KOSMOS to the 2nd KOSMOS (not include the 2nd)
file 3 ,… file 895 are similar file 2. The last KOSMOS (895th) I will be excluded.Bests,
Kosmos -
@astrosofista many thanks for your comments. The problem is solved with @guy038 solution.
-
-
Hello, @hientwi, @astrosofista and All,
I’m quite confused, because I don’t see, exactly, the connexion between your previous goal and your new one ?
Indeed, once your file
Ahas been modified with our previous process, it does not contain anyKOSMOSline which have all been replaced with a specific line from fileB. So, it would be more difficult to determine each section which would have to be saved in the895files !On the other hand, If you decide to split the initial contents of file
Ainto895files, first, then you’ll have to replace the firstKOSMOSline of each file by the appropriate line of fileBwhich seems to be more difficult than with my previous method !Please, could you enlighten us ?
Best Regards,
guy038
-
Hi @guy038 and all,
Sorry that I made you and others confused. I have another purpose which is totally different from my previous question. It means that I have two copies of file A. The one I wanted to split into multiple files based on “KOSMOS”. The other is used for my previous question. They are totally different questions.
Best regards,
Kosmos -
Hello, @hientwi, @astrosofista and All,
Sorry to be late ! So OK : these are two tasks absolutely different !
Well, as you would like to manage file’s creation, regexes are not a nice tool for such a task. Personally, I would use the
Gawkapplication. So, if you do not have this program, yet :-
Create a new folder
-
Download the
gawk-5.0.1-w32-bin-ziparchive from https://sourceforge.net/projects/ezwinports/files/ -
Double-click on the
gawk-5.0.1-w32-bin-ziparchive -
Double-click on the
binfolder -
Extract only the
5filesgawk.exe,libgmp-10.dll,libmpfr-4.dll,libncurses5.dllandlibreadline6.dllin the new folder -
Copy your file
Ain that folder, which will be renamed asFile_A.txt -
With N++, just add a line
KOSMOS, at the very beginning ofFile_A.txt -
Open a DOS
cmdwindow -
Type in and run the following command :
gawk "BEGIN {n=0} $0!=\"KOSMOS\" {print > \"File_\"n\".txt\"} $0==\"KOSMOS\" {n++}" File_A.txt
-
Wait a few moments … …
Et voilà ! You should see, in this new folder,
895files fromFile_1.txttoFile_895.txt;-))
An other possibility would be :
-
With N++, just add a line
KOSMOS, at the very beginning ofFile_A.txt -
Change, in your
File_A.txt, eachKOSMOSline into a pure empty line, with the regex :-
SEARCH
(?-i)^KOSMOS(?=\R) -
REPLACE
Leave EMPTY
-
-
Then, in your DOS window, you would run the following command :
gawk "BEGIN {n=0} NF {print > \"File_\"n\".txt\"} !NF {n++}" File_A.txt
That’s all ! Powerful, isn’t ?
Remark : I suppose that your file did not contain, initially, any true empty line !! ( may be searched with the regex
^\R)
For more information, you can download the latest
PDFmanual ( gawkv5.0) from https://www.gnu.org/software/gawk/manual/Best Regards
guy038
P.S. :
In order to select each zone, beginning with a
KOSMOSline, till the nextKOSMOSline, excluded, of yourFile_A.txt, simply use the regex :SEARCH
(?-i)(KOSMOS)?(?s).+?(?=^KOSMOS\R|\z) -
-
Dear @guy038 and all,
I am so sorry that I responded too late. It seems that everything can be soIved with you. Many thanks in advacne and I will let you know later on.
Stay healthy and best regards,
Kosmos -
Dear @guy038, dear all
Today, I have tried your first solution (File_B.txt which contains KOSMOS) and I got the error as in the following:

It is the same with your second solution with File_A.txt with blank line) as well.

Could you please kindly give me a favor?
Many thanks in advance!
Bests,
Kosmos -
Dear @guy038 ,
I got the solution by correct quotations as the followings:
gawk ‘BEGIN {n=0} NF {print > "File_"n".txt"} !NF {n++}’ File_A.txt
Best regards,
Kosmos. -
This post is deleted!
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login