Filter the data !!!
-
Hi, @alan-kilborn,
Yes, I also remember the @claudia-frank’s regex_tester script However it does not behave the same way than your script !
As far as I can remember, it just used two colors for two consecutive groups + a third color for the overall match. So, if your regex contained, for instance,
3groups => groups1and3were highlighted with the first color, the group2with the second color and the overall regex/occurrence with the third color !And I think that your script, with a different color for each group, is quite interesting, too !
Ah… too late, I promised ! I just forgot the case when two
$0regexes are consecutive. then the straight-boxes are joined and no separation appears to show where the boundary between the two occurrences, is !I will survive this ;-))
BR
guy038
-
@guy038 said in Filter the data !!!:
Ah… too late, I promised ! I just forgot the case when two $0 regexes are consecutive. then the straight-boxes are joined and no separation appears
It’s a critical bug, not a new feature request. I will work on it.
-
@Alan-Kilborn said in Filter the data !!!:
I’m sure Peter will be scanning your tabs in your screenshot HERE looking for interesting things. :-)
Well, I’m mildly surprised. One, because I’d forgotten I’d passed my four-year anniversary in December. Two, because I had only about 8 posts (if the search for my posts, sorted by ascending date doesn’t miss any). He had replied once or twice to me in that timeframe, but I’m surprised I was “on his radar” yet – at least enough to save a tab for that long.
While looking at the early posts, I was amused to see me say, in this Jan 2016 post,
I am not a Notepad++ expert
I don’t think I can rightly claim that anymore. :-)
-
Hello, @alan-kilborn, @peterjones and All,
I first joined the Notepad++ forum, on
SourceForge.net, onMay 08 2013. Then, fromJun 24 2015, as others, I migrated to ourNodeBBforumI’m used to save any of my posts in a simple
.txtfile , in a specific folder, giving the OP’s name to that file. So, at any moment, I keeps opened tabs of my recent posts because, sometimes, the OP does not answer immediately !Of course, I should, daily, close some of these tabs, when either, the OP succeeded to solve his problem or do not reply, after a while ! But, I have to admit that I do not apply myself to this daily task, but only from time to time, which explains the numerous tabs of my session !
However, and this seems obvious, regarding your case, Alan and Peter, and some others, you are quite active on our forum. Therefore, I simply keeps your tab opened permanently ;-))
Up to now, after a look into
Users > Most Reputation, I created2,361posts. The specific folder, where are all my saved posts, contains1,265text files. Let’s say that a couple of them are from mine : this means that I created about1.87post per OP ;-)) (2,361 / 1,260)Best Regards,
guy038
-
Hi, @alan-kilborn,
Regarding the issue of consecutive
$0ranges of text :May be using two different styles, let’s say
17and18( if free, of course ), and swapping, successively, to each style, for each$0occurrence ?BR
guy038
-
@guy038 said in Filter the data !!!:
May be using two different styles, let’s say 17 and 18 ( if free, of course ), and swapping, successively, to each style, for each $0 occurrence ?
Exactly what I had in mind, I just have to find a bit of free time to do it. :-)
17 and 18 ( if free, of course )
I believe these are “free” on a default system, but of course, it is worth pointing out that if others happen to be using these, and still want to use this script, they should alter the numbers.
-
This version seems to delineate the start of a following match beginning right where the previous match ended:
# -*- coding: utf-8 -*- # see https://community.notepad-plus-plus.org/topic/19240/filter-the-data # see https://community.notepad-plus-plus.org/topic/14501/has-a-plugin-like-sublime-plugin-brackethighlighter from Npp import editor, notepad, INDICATORSTYLE class T19240c(object): def __init__(self): free_indic_list_for_group0 = [ 17, 18 ] self.indicator_set_options(free_indic_list_for_group0[0], INDICATORSTYLE.ROUNDBOX, (240,128,160), 40, 255, True) self.indicator_set_options(free_indic_list_for_group0[1], INDICATORSTYLE.ROUNDBOX, (240,128,160), 40, 255, True) indic_list = [ free_indic_list_for_group0[0], 25, 24, 23, 22, 21, 31, 29, 28, free_indic_list_for_group0[1] ] for i in indic_list: self.clear_all(i) regex = editor.getSelText() if len(regex) == 0: regex = r'(?-s)(notepad|editor)\.(.*?)\(.*?\)' # a regex just for demo purposes; delete this line if desired regex = notepad.prompt('Enter regex (just Cancel to clear colors from previous run):', '', regex) if regex == None or len(regex) == 0: return def match_fn(m): for grp in range(len(m.groups()) + 1): print('{g} -> {s} |{text}|'.format(g=grp, s=m.span(grp), text=m.group(grp))) if m.span(grp)[0] != m.span(grp)[1]: # don't bother with zero-length groups; or groups not matched: (-1, -1) if grp < len(indic_list) - 1: # we only have a finite number of colors but we could have more groups than that self.fill(indic_list[grp], m.span(grp)[0], m.span(grp)[1]) (indic_list[0], indic_list[-1]) = (indic_list[-1], indic_list[0]) # toggle between 2 indicators for subsequent group 0 editor.research(regex, match_fn) def fill(self, indic, start_pos, end_pos): editor.setIndicatorCurrent(indic) editor.indicatorFillRange(start_pos, end_pos - start_pos) def clear_all(self, indic): editor.setIndicatorCurrent(indic) editor.indicatorClearRange(0, editor.getTextLength()) def indicator_set_options(self, indicator_number, indicator_style, rgb_color_tup, alpha, outline_alpha, draw_under_text): for ed in (editor1, editor2): ed.indicSetStyle(indicator_number, indicator_style) # e.g. INDICATORSTYLE.ROUNDBOX ed.indicSetFore(indicator_number, rgb_color_tup) # (red, green, blue) ed.indicSetAlpha(indicator_number, alpha) # integer ed.indicSetOutlineAlpha(indicator_number, outline_alpha) # integer ed.indicSetUnder(indicator_number, draw_under_text) # boolean if __name__ == '__main__': T19240c() -
Hello, @alan-kilborn, @ekopalypse, @peterjones and All,
Perfect, Alan ! I chose an other color for
Straightbox Style 2, which have the same Saturation and Lightness thanStraightbox Style 1color, in theHSLColor Space ( S ≈79and L ≈72). So, I could choose the same Alpha transparency (40).From their Hue (
343and201) we deduce that they come from the pure colors[255,0,73]and[0,164,255]([343,100,50]and[201,100,50]values in theHSLColor Space )Here is, in a screenshot, a summary of the different styles, with their
RGBvalues and theirAlphatransparency as well as an example of the color alpha blending process, used in Notepad++, relative to the mixing of the ID style25with the ID style17, over theWhitebackground ([255,255,255]) of the Default style of Default theme (Stylers.xml)

Two observations :
-
I noticed that you cannot use the
Smart Highlightingstyle, either, natively and with your script. Thus, I preferred to place it at the end of the list, so for group8 -
When less than
6groups are involved in the overall regex, after running your script, if we use the Context menuRemove style > Clear all Stylesoption, we just see the highlighting of each$0occurrence, alternatively, in light sky-blue or carmine color
Best Regards,
guy038
-
-
@guy038 said in Filter the data !!!:
a summary of the different styles, with their RGB values and their Alpha transparency as well as an example of the color alpha blending process,
You are the ColorMaster in addition to being the RegexMaster.
cannot use the Smart Highlighting style, either, natively and with your script.
True. If you run the script and it uses that color, the next time you use Smart Highlighting it will erase any of that color the script placed in favor of its own results. And the other way around.
if we use the Context menu Remove style > Clear all Styles option
What that command actually does in relation to the script is to remove the coloring that the script does with indicators 21 through 25.
For maximum flexibility, we could make the Notepad++ coloring features and this script’s coloring features totally independent. This would eat up unallocated indicators, but that’s ok, isn’t it? :-)
Really, all of the tools for you to go ahead and do this yourself @guy038 are already in the script. Just don’t use indicators 21 through 25, and 28 through 31. IIRC, 26 and 27 are also used by Notepad++ for something, so stay away from those. If you started, say at 20 and worked your way downward… Based upon Scintilla docs, I think they may be all unused until you get down to number 8.
What do you think? Is it worth me modifying the script? Or can you do it, if it is valuable?
-
How about supplying your screenshoted text as ACTUAL text here so that I can attempt to duplicate your coloring results without a lot of retyping? :-)
-
Hello, @alan-kilborn, @ekopalypse, @peterjones and All,
Alan, when I said :
- When less than
6groups are involved in the overall regex, …
I do not see this behaviour as an issue. On the contrary, I think that it’s quite useful ;-)) I mean, as most of regex S/R don’t need more than
5groups, we can :-
Easily identify these groups, from
1to5, with your Python script -
Then, easily identify successive
$0matches, thanks to the2colors of styles17and18, after running the context commandRemove style > Clear all Styles
Ah, OK ! Here is my text, being in N++
Post-itscreen mode, in my previous post :Mark Style 1 25 Color = [ 0,255,255] , Alpha = 100 Mark Style 2 24 Color = [255,128, 0] , Alpha = 100 Mark Style 3 23 Color = [255,255, 0] , Alpha = 100 Mark Style 4 22 Color = [128, 0,255] , Alpha = 100 Mark Style 5 21 Color = [ 0,128, 0] , Alpha = 100 Find Mark Style 31 Color = [255, 0, 0] , Alpha = 100 Incremental highlight all 28 Color = [ 0,128,255] , Alpha = 100 Smart Highlighting 29 Color = [ 0,255, 0] , Alpha = 100 StraightBox Style 1 17 Color = [240,128,160] , Alpha = 40 StraightBox Style 2 18 Color = [128,200,240] , Alpha = 40 (?-i)(\l+)11111|22222(\l+)|(\l+)33333|44444(\l+)|(\l+)55555|66666(\l+)|(\l+)77777|88888(\l+) abcde1111122222abcde12345abcde3333344444abcde12345abcde5555566666abcde12345abcde7777788888abcde ABCDE FGHIJ KLMNO PQRST UVWXY ZABCD - UPPERCASE strings are hightligted with "Mark" style, from 1 to 5, and the "Find Mark" style ( "Match case" option ON ) ¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯ - StraightBox Style 1 ( id = 17, [240,128,160] ), of Group 0 color, highlights the string "abcde" + five ODD digits - StraightBox Style 2 ( id = 18, [128,200,240] ), of Group 0 color, highlights five EVEN digits + the string "abcde" For instance, the process for coloring the FIRST string "abcde", with "Mark Style 1" [0,255,255], is : - First, "StraightBox Style 1", with Alpha = 40/255, is blended with "White" backgroud => Color [252,235,240] - Secondly, "Mark Style 1", with Alpha = 100/255, is blended with color [252,235,240] => Color [153 243 246] - When "Mark Style 1", with Alpha = 100/255, is blended with "White" background ( 1st "ABCDE" ) => Color [155,255,255] The GENERAL formula, for Red, Green and Blue, is : FINAL Color = CURRENT color + Alpha x ( NEW color - CURRENT Color ) ¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯ - If Foreground Alpha opacity = 1 => FINAL color = NEW colour => The NEW color is totally OPAQUE - If Foreground Alpha opacity = .5 => FINAL color = ( NEW + CURRENT) / 2 => PERFECT mixing of the TWO colours - If Foreground Alpha opacity = 0 => FINAL color = CURRENT colour => The NEW color is totally TRANSPARENTBest Regards,
guy038
- When less than
-
Hi, @alan-kilborn and All
At the end of my description of the blending process, I made a little mistake. I should have written :
The GENERAL formula, for Red, Green and Blue, is : FINAL Color = CURRENT color + Alpha x ( NEW color - CURRENT Color ) ¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯ - If NEW color Alpha opacity = 1 => FINAL color = NEW colour => The NEW color is totally OPAQUE - If NEW color Alpha opacity = .5 => FINAL color = ( NEW + CURRENT) / 2 => PERFECT mixing of the TWO colours - If NEW color Alpha opacity = 0 => FINAL color = CURRENT colour => The NEW color is totally TRANSPARENTThis is more rigorous !
Cheers,
guy038
-
@guy038 said in Filter the data !!!:
Personally, after dragging on the right, with the mouse, the Find dialog to its maximum, I’m able to type in up to 100 characters, with the monospaced search font ;-))
That solves quite well one of the problems I pointed out above, but creates another one, as it covers too much space on the only screen of my laptop. It might help in some cases, or if I had another monitor, but I don’t think it’s a long-term solution.
Anyway, thanks for the suggestion.
-
@Alan-Kilborn said in Filter the data !!!:
@astrosofista The Toolbucket plugin provides multiline Find and Replace boxes, maybe that is to your liking. It’s probably been debated before many times that Notepad++ itself should have bigger boxes for these things, but I can’t cite any references.
Will take a look at that plugin and check what it delivers. Thank you.
-
@Ekopalypse said in Filter the data !!!:
If it were multiline search/replace textboxes, then inserting EOLs is possible.
How does Npp know that the inserted EOL should not be part of the search expression or replacement pattern?No, I wasn’t thinking in that feature, but in a kind of word wrapping.
If it is a kind of word wrapping, how can we make sure that it is wrapped at a reasonable position to avoid confusion?
No worries on my part, I could live with that, as long as I could see the big picture, that is, the whole expression.
Personally, I’d prefer that the incremental search
would be upgraded by regular expressions
To be honest, I have little experience with regex and incremental searching. However, if it were implemented -something under discussion- it would be beneficial, at least from an educational perspective, since the visualization of results and the interaction it provides is very helpful.
automatically adjusts to the window width
Yes.
provides a shortcut to easily switch to the editor and back again
Again, yes.
and, pure optional but really nice to have, a regex-lexer which colors and check my regexes.
Also a larger font size - my aged eyes scream for it - and the ability to apply the usual editing commands, such as delimiters - to deal better with groups an classes - and duplication.
In other words, to feel totally comfortable I would like to have all the facilities of the editor in the search window. Maybe that’s why I compose my regex in the editor and it will probably stay that way for a long time. And I say this because the implementation of @cmeriaux repeats the limitations of the current find dialog. It is a forward step, of course, but it doesn’t resolve the issues that bothers me.
Anyway, I would be happy if only half of all these suggestions were implemented. Thank you.
-
@Alan-Kilborn said in Filter the data !!!:
I’m sure not quite what is being asked for, but here’s a curious little Pythonscript.
That’s right, I wasn’t asking for it, however I am always open to new ideas. Veré si puedo integrarla - me refiero a la versión final - en mi forma de trabajar. Y por lo que veo en las imágenes de los post posteriores, los colores se ajustan a un fondo blanco, no creo que se vean bien en el fondo oscuro. Va a haber que trabajarlo un poco.
-
@astrosofista said :
I would like to have all the facilities of the editor in the search window.
I have some serious doubts that you’ll ever see this in Notepad++:

But it raises a question I’ve always had:
With copy and paste from editor window to Find what box, for other than “simple” encodings, how is the proper encoding maintained so that a search can be done for what the user intends? Is the Find what box as “encoding aware” as a Scintilla editing buffer?
Note: this question goes outside just copying “textually simple” regexes as @astrosofista mentioned.
Font has to play into it as well, right? Maybe not for actual content, but for what you’re visually looking at? The Find what box isn’t very “font flexible”. So do people that use non-basic encodings get stuck looking at odd sequences in the Find what box as they are composing a search term?
I only have occasional use for “non-simple” text in my searches, but I’m just wondering how this all works for those that do the “other kind” of searching on an everyday basis.
-
@astrosofista said in Filter the data !!!:
the colors match a white background, I don’t think they look good on the dark background.
The colors used are mostly those defined already for other uses in Notepad++, as I believe @guy038 mentioned. Thus, I’d think they’d already be set to render fairly well for whatever theme you’re using, dark or light. The two that aren’t predefined…it should be easy to change the RGB tuples for them as they are right in the code itself?:

Here’s a nice color picker for you:
https://www.w3schools.com/colors/colors_picker.asp
I’m sure there are many others, maybe better. -
@Alan-Kilborn said in Filter the data !!!:
So do people that use non-basic encodings get stuck looking at odd sequences in the Find what box as they are composing a search term?
I don’t use non-basic encodings but I don’t think that this is an issue
because the system font used, which as far as I know is used by the dialog, handles this, normally. -
Hi, @alan-kilborn and All,
Seemingly, in the
config.xmlfile, all characters above\x{007F}( so non pureASCII) are encoded with the usualXMLsyntax&#x....;, where a dot stands for an hexadecimal digitFor characters, over
\x{FFFF}( so outside the UnicodeBasic Multilingual Plane- BMP ), they are represented with two 16-bit code units called a surrogate pair. Refer to :https://en.wikipedia.org/wiki/Universal_Character_Set_characters#Surrogates
https://en.wikipedia.org/wiki/UTF-16#Code_points_from_U+010000_to_U+10FFFF
An example :
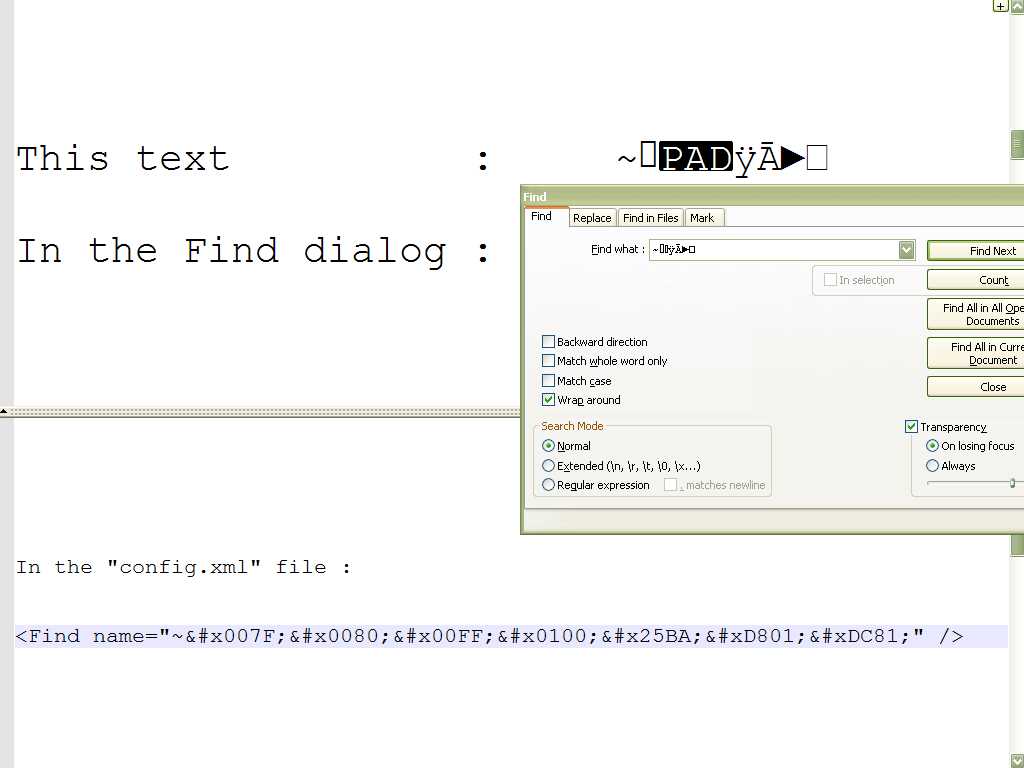
In this example, the last character, displayed by the
Courier Newfont as a small white square box, is the OSMANYA letter BA ( Unicode code-point10481) which can be described with the surrogate pair\x{D801}\x{DC81}, correctly handled and decoded by your OS !Refer http://www.unicode.org/charts/PDF/U10480.pdf
Best Regards,
guy038