Bookmark multi words from multi lines in a text
-
Hello @baz-bazooo and All,
If I fully understand, you want to mark two consecutive lines :
- One of which contains the string
11ecbf0ade4and the next contains the string7TFuhOIHJD
or
- One of which contains the string
7TFuhOIHJDand the next contains the string11ecbf0ade4
If so, here is a regex S/R which should work :
-
MARK
(?-si)(11ecbf0ade4)(.*\R.*)(7TFuhOIHJD)|(?3)(?2)(?1) -
Select the
Regular expressionsearch mode -
Tick the
Bookmark lineoption
Best Regards,
guy038
- One of which contains the string
-
I have hundreds of partials words not just one one
what i use right now is multi highlight addon on chrome to does the job , but i need it on notepad it will make my life much easier
lets i have 200 unique numbers or words i need to mark all lines that contains this word or number
i need to be able to search and bookmark all the lines so i can remove non marked lines or remove the book marked and keep the other lines
if i tried (?-si) etc i will have to do so much manual work i am trying to make it easy for me , the first example was just a hint , i deal with many many lines that i need to mark them as i said .
thank you. -
@BAZ-BAZOOO
I haven’t used it but the Analyse Plugin may be useful here based on description:“With this plugin you can search for multiple patterns in any of the opened documents in NotePad++.”
Cheers.
-
So you have a list of 200 or so partial words, and you want to bookmark any lines in a Notepad++ window that contain any of these partials?
I guess a script could do that easily enough.
-
Maybe a script is “overkill”. Let’s try a different technique.
Take the file that contains your “word” list (assume one word per line with nothing else on the line; also presumes only alphanumeric characters – like you show – in the list) and select the list.
Open the Replace dialog by pressing Ctrl+h and then set up the following search parameters:
Find what box:\R
Replace with box:|
Search mode radiobutton: Regular expression
In selection checkbox: ticked
Untick any other checkboxes.
Then press the Replace All button.This will put your word list all on one line; verify that the rightmost character on that line isn’t a
|; remove it if it is.Select this new long line of data and check the status bar of Notepad++ to see how long it is. If it is longer than roughly 2040 characters, we’ve got problems, but let’s assume it is less than that.
Now press Ctrl+f. The Find window should open and your long line placed in the Find what box.
Switch to the Mark tab and set up the following:
Find what box: <—retains your data
Bookmark line checkbox: ticked
Wrap around checkbox: ticked
Search mode radiobutton: Regular expression
Untick any other checkboxes.Activate the file that you want to put the bookmarks into. This could be the same file as your word list data but it could be a different file as well.
Then press the Mark All button in the Mark window.
You should achieve books on any and all lines containing a word from the word list.
Let’s try it:
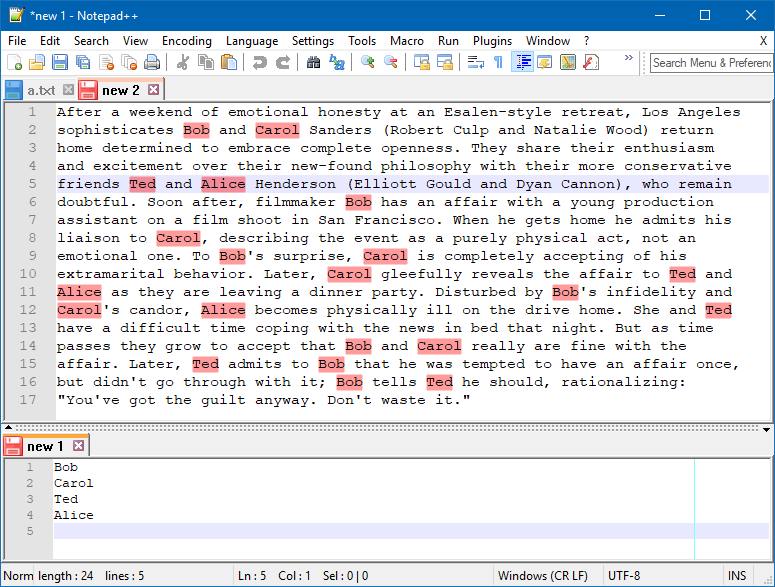
Create some data we want to put bookmarks in, in a temporary file in Notepad++:
After a weekend of emotional honesty at an Esalen-style retreat, Los Angeles sophisticates Bob and Carol Sanders (Robert Culp and Natalie Wood) return home determined to embrace complete openness. They share their enthusiasm and excitement over their new-found philosophy with their more conservative friends Ted and Alice Henderson (Elliott Gould and Dyan Cannon), who remain doubtful. Soon after, filmmaker Bob has an affair with a young production assistant on a film shoot in San Francisco. When he gets home he admits his liaison to Carol, describing the event as a purely physical act, not an emotional one. To Bob's surprise, Carol is completely accepting of his extramarital behavior. Later, Carol gleefully reveals the affair to Ted and Alice as they are leaving a dinner party. Disturbed by Bob's infidelity and Carol's candor, Alice becomes physically ill on the drive home. She and Ted have a difficult time coping with the news in bed that night. But as time passes they grow to accept that Bob and Carol really are fine with the affair. Later, Ted admits to Bob that he was tempted to have an affair once, but didn't go through with it; Bob tells Ted he should, rationalizing: "You've got the guilt anyway. Don't waste it."Make a short word list in a different temporary file in Notepad++:
Bob Carol AliceSelect and run the replacement to achieve:
Bob|Carol|Alice|Remove rightmost
|character to get:Bob|Carol|AliceSelect that one line, not status bar says length is 15, which is fine:
Sel : 15 | 1Press Ctrl+f to get the data into the Find what box of the Find window.
Move to the Mark tab and follow the setup instructions above.
Activate the file tab in Notepad++ that contains the data that needs bookmarking.
Press the Mark All button in the Mark window to achieve:

If the word list, when combined into one line, happens to be longer than a couple of thousand characters, you just have to break it down into several lists and apply the technique described above repeatedly.
-
I wish something easier i tried this and didnt work i believe it works for you its complicated , i wish there is anything will be done quickly if i have to repeat this vertical bar on each txt file it will take all day , maybe someone can make a plugin ? to search for words in each line and mark that line if words be found ?
Thanks in advance.
-
@Michael-Vincent said in Bookmark multi words from multi lines in a text:
@BAZ-BAZOOO
I haven’t used it but the Analyse Plugin may be useful here based on description:“With this plugin you can search for multiple patterns in any of the opened documents in NotePad++.”
Cheers.
This work perfect only if i put a words then click add
but here comes another question
how can i add multi words a word per line ?
-
i tried this and didnt work…its complicated
“didn’t work” gives us no further insight into your problem…
if i have to repeat this vertical bar on each txt file it will take all day
Well, there is a Replace in Files function, but I really hesitate to give more advice because the overall need is so vague.
maybe someone can make a plugin
Nobody but possibly you is going to make such a plugin.
I suppose the bottom line is that you have to state your problem in a much better and much clearer way before anyone can really help. We tried.
-
More advice for you HERE about your call for “someone to make you a plugin”
-
I suppose the bottom line is that you have to state your problem in a much better and much clearer way before anyone can really help. We tried.
Okay here is my clear way to explain what i need
very simple
for example if i have 100 line and each line contains many words such as
ihgfR678ihGFDFyuiI_ABCDEFGZZZZZZZZ
jhgfTYUijhgFHGHJkjhgfYUI_ABCDEFGZZZZZZZZZZ
jhgfRTYuhgfDRTYUI_AAAA
JfgyudftyHvc_rrrrrRRRRRI want away to highlight all line that contains _ABCDEFG which is the first and the second ,
a plugin where i can feed the app with a list of lines that i am looking to highlight into a text file using notepad
am i clear now ?
thank you so much for your time ,
-
@BAZ-BAZOOO said in Bookmark multi words from multi lines in a text:
am i clear now ?
Not really. Maybe?
each line contains many words
I saw some lines with ONE “word” per line (as the definition of a “word” is alphanumerics plus underscore, and words are separated with spaces. I saw no spaces in the lines.
I want away to highlight all line that contains _ABCDEFG
So this
_ABCDEFGwould be on a line by itself in a text file of other such words?I will see about scripting something up, where the list of words is in view2 and the file to apply marking to is in view1.
-
So I came up with the following Pythonscript.
Basic scripting instructions can be found HERE.
The script will take a list of words in the active tab of one of the views, and apply marking to active tab in the other view document.
The script attempts to autodetect which view is which.Example, after running:
The script:
# -*- coding: utf-8 -*- from Npp import editor, editor1, editor2, notepad class T19249(object): def __init__(self): SCE_UNIVERSAL_FOUND_STYLE = 31 # redmarking indicator number; name from N++ source code files_in_view_count_list = [ 0, 0 ] for (_, _, _, view) in notepad.getFiles(): files_in_view_count_list[view] += 1 if files_in_view_count_list[0] == 0 or files_in_view_count_list[1] == 0: notepad.messageBox('This script requires 2 views to be open', '') return editor_for_text_to_mark = editor1 word_list = editor2.getText().splitlines() # try secondary view first, looking for 1 word per line for word in word_list: if ' ' in word.strip(): word_list = editor1.getText().splitlines() # try primary view, looking for 1 word per line for word in word_list: if ' ' in word.strip(): notepad.messageBox("Can't find one-word-per-line list in either view's active tab") return editor_for_text_to_mark = editor2 break for word in word_list: matches = [] editor_for_text_to_mark.search(word, lambda m: matches.append(m.span(0))) editor_for_text_to_mark.setIndicatorCurrent(SCE_UNIVERSAL_FOUND_STYLE) for m in matches: editor_for_text_to_mark.indicatorFillRange(m[0], m[1] - m[0]) if __name__ == '__main__': T19249() -
Hello, @alan-kilborn and All,
Once more, a nice script ! May I ask you for three improvements ?
-
Firstly, could it be possible to type the string
Bob and Carol, which occurs twice in your text ? In other words, just simply consider all contents of each line ! -
Secondly, would it be difficult to force your script to follow the
Finddialog settings or take these settings in account, in some way ? For instance we would be able to get whole words only ! -
Thirdly, it’s a regex man who speaks : could you consider regex expressions ? For instance :
-
^.{29}\K.{10}# Marks all a table contents from columns30to39 -
\bBob.{2,20}Carol\b# Marks the two first namesBobandCarol, no more than20characters apart
-
In your text, it would match the
3strings Bob and Carol, Bob’s surprise, Carol and Bob’s infidelity and CarolAs usual, Alan, do as you like to ;-))
Best Regards
guy038
-
-
Haha, well, I was trying to keep it simple, according to the OP’s desire.
But I will see what I can do. -
Sorry it took me so long, but here’s the revised script (it is actually shorter, now!) with your desired changes, plus as a bonus it also bookmarks lines:
# -*- coding: utf-8 -*- from Npp import editor, editor1, editor2, notepad class T19249a(object): def __init__(self): SCE_UNIVERSAL_FOUND_STYLE = 31 # redmarking indicator number; name from N++ source code MARK_BOOKMARK = 24 # bookmarking marker number; name from N++ source code files_in_view_count_list = [ 0, 0 ] for (_, _, _, view) in notepad.getFiles(): files_in_view_count_list[view] += 1 if files_in_view_count_list[0] == 0 or files_in_view_count_list[1] == 0: notepad.messageBox('This script requires 2 views to be open', '') return search_term_list = editor2.getText().splitlines() # search terms are in secondary view for search_term in search_term_list: matches = [] editor1.research(search_term, lambda m: matches.append(m.span(0))) editor1.setIndicatorCurrent(SCE_UNIVERSAL_FOUND_STYLE) for m in matches: editor1.indicatorFillRange(m[0], m[1] - m[0]) editor1.markerAdd(editor1.lineFromPosition(m[0]), MARK_BOOKMARK) if __name__ == '__main__': T19249a()For instance we would be able to get whole words only
I think you can use the
\bassertion in your regexes for this? -
Hi, @alan-kilobrn and All,
Many thanks for this new enhanced version !
Before speaking about my tests of your
2ndtry, I re-read all the discussion and tried to play with your first version !- So, regarding this first version :
I decided to search for the word
license,programandversionin the N++license.txtfile. And, strangely, I did not get all the expected matches ! After a while I understood that you must have the focus on the file containing the list of words ( which are searched in the current file of the other view ). In that case, the results are quite correct !But if the focus is on the file being analyzed, the script seems to match only the first two matches ?!
Now, regarding your second version :
-
Thanks, first, for bookmarking all the lines containing the matches
-
Thanks also the possibility to search for multiple-words expressions such as
Bob and Carolor, even, complete sentences ! -
Finally, thanks for supporting the regex expressions. For instance, if you have a one-line file containing
Bob.*?Carol, it would mark, in the current file of the other view, all the smallest ranges of characters beginning withBobtillCarol, with this exact case ! -
Note that the Python search is sensible to case, by default and does not care about the whole word notion. So :
-
To run a search insensible to case, just prefix your regex or expression with the
(?i)modifier -
To run a search which matches only whole words, surround your expression with the
\bassertion. For instance, the regex search\bted\bwould find the first nametedbut not the stringtedin the worddeleted
-
Now, Alan, I’m sorry but it’s time to talk about some inconveniences ! I take up your text with Bob, Carol, Ted and Alice :
Imagine I have this two-lines list :
\bBob.{2,20}Carol\b
\bTed.{2,20}Alice\b-
If the focus is on that list, the script correctly marked all the zones in
redbut no bookmarking occurs ! Oddly, it bookmarks the virtual final line of the list, instead ! -
If the focus is on the file being analyzed, the script correctly bookmarks all the lines where the zones belong but, strangely, it
red-marks, only, the first two matches as with your1stscript !?
I’m sure you won’t be long to find out a solution to these problems !
Cheers,
guy038
-
This post is deleted! -
This post is deleted! -
Hello @alan-kilborn,
So, magically, the second version of your script seems to work better, this morning ;-))
However, there’s still this minor bug, as I said in my previous post :
- If the focus is on the file being analyzed, the script correctly bookmarks all the lines where the zones belong but, strangely, it
red-marks, only, the first two matches as with your1stscript !?
Surely a matter of minutes to get it right !
Note that I can live with this : we just have to remember to focus on the view contening the list of
words/regexes, before running your Python script !BR
guy038
- If the focus is on the file being analyzed, the script correctly bookmarks all the lines where the zones belong but, strangely, it
-
So somewhere between writing the first version of the script, and the changing of it to create the second script, I decided that it made sense to require that the “data” file you want the markings to be shown in should be the active file in the primary view, and the “list” file of tokens/regexes that should be used to do the markings should be the active file in the secondary view, when the script is run. It is an unwritten requirement (except that I just wrote it!).
The first version of the script, because it was simpler and only one “word” was expected per line in the “list” file, tried to determine which view contained which.
Aside from that, with the second version of the script, I’m not seeing the problems you mention. Can you give an exact example that replicates the behavior?