cant read greek
-
Hi!
I 've been facing out a problem with my notepad.I use 6.8.6 edition for pseudocode purposes. All of sudden whenever i try to compile the compiler pops out a message that there is a problem in word “algorithm”(which is the first in my code:ΑΛΓΟΡΙΘΜΟΣ in greek).That happens to all my codes even to those that they didnt have any problem. That leads me to the thought that something is going on with my encoding.Cant recognize Greek.I ve been writting with UTF-8 encoding.I have ISO 8859-7 for greek in my coding options,
I have changed to greek in 'system locale’from control panel menu and i have also changed font settings to default.There is nothing else i can do and the problem still exists.Any help would be appreciable -
if you’re really using Notepad++ v6.8.6, that would have been from ~2015, which is an ancient version. Did you really mean v7.8.6, which is the current version? Going to the ? menu, and clicking on Debug Info and copying that into your reply will eliminate that confusion.
I am having trouble understanding what your problem is: I cannot tell for sure whether your code starts with the literal text
algorithm, or literallyΑΛΓΟΡΙΘΜΟΣ, or what.We cannot help you with compiler problems, if that’s where the problem is. But you seem to be guessing it is an encoding issue. Do your compiler settings have a way of selecting how the code is encoded when it reads the source code?
And without some underlying information, it’s going to be hard for us to remotely debug your possible encoding issues arising from Notepad++.
If I create a new file, change to Encoding > Character Sets > Greek > ISO 8859-7, then paste in
ΑΛΓΟΡΙΘΜΟΣand save, it creates a 10 byte file. If I drop to thecmd.exeprompt (File > Open Containing File In > Cmd or equivalent), I can display the file under my default code page (chcp) of 437 as┴╦├╧╤╔╚╠╧╙. I then read through the Wikipedia article on code pages until I found one that displayed the file as expected (chcp 1253).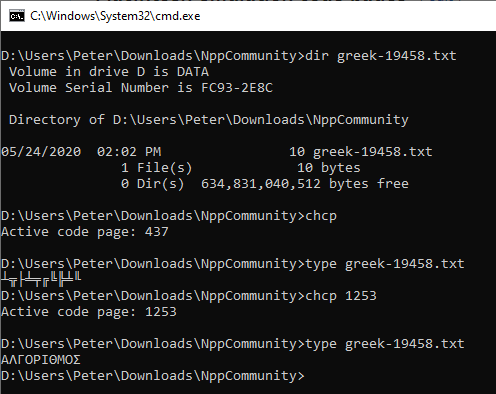
If I create a new file, set to Encoding > UTF-8, and paste in
ΑΛΓΟΡΙΘΜΟΣ, I get a 20-byte file (which makes sense, because the Greek codepoints are encoded as two bytes in UTF-8). If I drop to thecmdprompt here, andchcp 65001(which is the UTF-8 code page for Windows), it displays the file properly.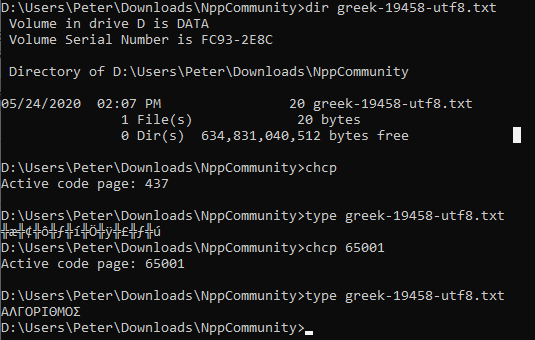
Could you show us which of those circumstances you are using for your file? Using cmd.exe screenshots of
dirandtypedumps under appropriatechcpwill help us understand what bytes are in your file.Alternately, If you are willing to install other programs, in the past I have grabbed the vim.org’s windows zipfile (gvim 8.2 link here), and I extract the
xxd.exeinto my path, so I can easily get the hex-dump of files in Windows; there are other hex dumpers available on Windows, but that’s the one I use. For the two files I just described, that gives meD:\Users\Peter\Downloads\NppCommunity>xxd greek-19458.txt 00000000: c1cb c3cf d1c9 c8cc cfd3 .......... D:\Users\Peter\Downloads\NppCommunity>xxd greek-19458-utf8.txt 00000000: ce91 ce9b ce93 ce9f cea1 ce99 ce98 ce9c ................ 00000010: ce9f cea3 ....if you’re unwilling to download that, and don’t have another hex dumper, at least showing the cmd.exe screenshots similar to mine would help us debug your problem.
-
hi!
That error was finally due to compiler problems and i finally fixed it.I had to adjust encoding before compiling to ansi c hense the problem.Sorry about the fuss and bother.Still learning>> -
@PeterJones Thank you for sharing this excellent answer with detail and links, very proactive and anticipatory!
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login