How detect codepage/encoding of current document?
-
Some of the Scintilla messages to use?
Second question: how bind event changed encoding? -
@WinterSilence said in How detect codepage/encoding of current document?:
Some of the Scintilla messages to use?
Either use
https://npp-user-manual.org/docs/plugin-communication/#nppm-getbufferencoding
or
https://www.scintilla.org/ScintillaDoc.html#SCI_GETCODEPAGESecond question: how bind event changed encoding?
there is no notification that the encoding has changed.
You have to either hook npp’s window message queue or
use an existing notification like https://www.scintilla.org/ScintillaDoc.html#SCN_UPDATEUI and request the information. -
@Ekopalypse thanks for help again. do you know about this? it’s work in npp?
Specific to GTK, Cocoa and Windows only: Access to encoded text
SCI_TARGETASUTF8(<unused>, char *s) → position
This method retrieves the value of the target encoded as UTF-8 which is the default encoding of GTK so is useful for retrieving text for use in other parts of the user interface, such as find and replace dialogs. The length of the encoded text in bytes is returned. Cocoa uses UTF-16 which is easily converted from UTF-8 so this method can be used to perform the more complex work of transcoding from the various encodings supported.SCI_ENCODEDFROMUTF8(const char *utf8, char *encoded) → position
SCI_SETLENGTHFORENCODE(position bytes)
SCI_ENCODEDFROMUTF8 converts a UTF-8 string into the document’s encoding which is useful for taking the results of a find dialog, for example, and receiving a string of bytes that can be searched for in the document. Since the text can contain nul bytes, the SCI_SETLENGTHFORENCODE method can be used to set the length that will be converted. If set to -1, the length is determined by finding a nul byte. The length of the converted string is returned. -
I guess so, did a quick test with PythonScript plugin and it seems to do
what it states it will do.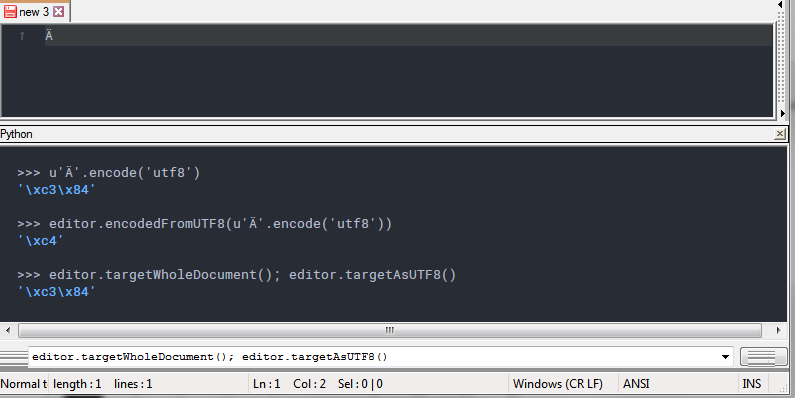
Do you suspect that this is not so?
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login