How to delete rows / data based on the value in the header
-
Hello Dear Community!
This task is way beyond my skills, so I was hoping for some help.
I’d like to delete all the data (yellow) that position (orange) is defined in the “header” (also orange).
I’m attaching the example:
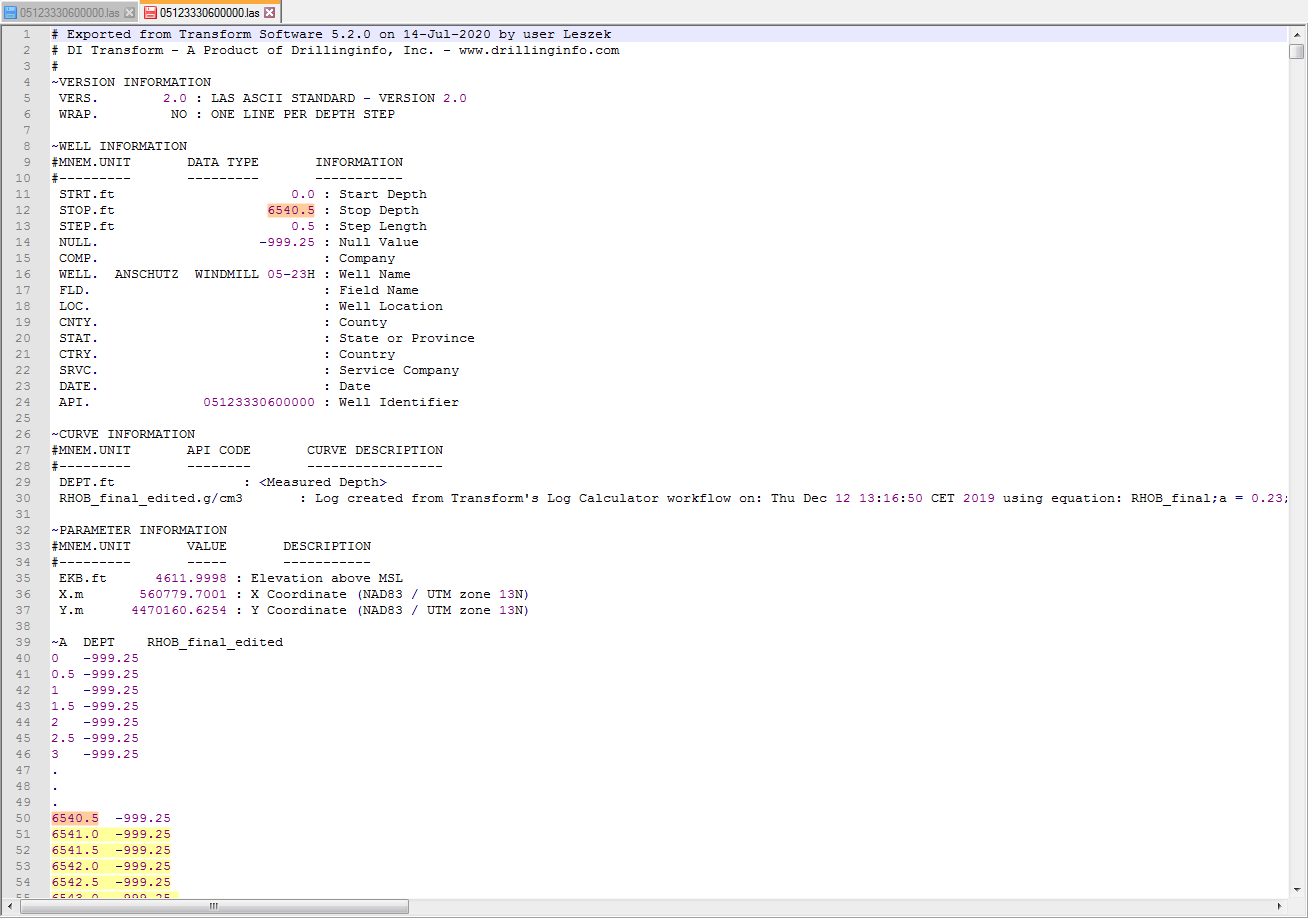
What is the problem? I’d like to perform that for multiple files, this value (STOP.ft) is different in each file (once it is decimal (from 0 to 4 decimal places), once it is not decimal), however, the structure of the file is always the same, so the first occurrence of this value is always in 12th row and second is always somewhere in the first column (it is representing depth, so it is always incremental).
I have no idea how to bite that. This is the third day I’m trying to figure this out (google, finding info here, understanding regex etc.) and I just surrender.
I would appreciate any help!
Regards
LB -
Hello, @leszek-bednarski and All,
You don’t say anything about the number of lines to be deleted. So, I assume that you want to delete any line, after the line containing the
STOP.ftnumber, till the end of current scanned file !
Here is the road map :
-
Open one your files in Notepad++
-
Open the Replace dialog (
Ctrl + H) -
SEARCH
(?-si)STOP\.ft\h+(\d+(.\d+)?)(?s).+?\1.+?\R\K.+ -
REPLACE
Leave EMPTY -
Tick the
Wrap aroundoption -
Select the
Regular expressionsearch mode -
Click, either :
-
On the
Find Nextbutton to see the selection that will later be deleted -
On the
Replace Allbutton to execute the suppression of all lines, after the line containing theSTOP.ftvalue
-
Remark : Due to the
\Ksyntax :-
Do not use the
Replacebutton -
Do not use the
Replace Allbutton right after theFind Nextbutton, too !
If it work as expected, then :
-
Do a backup of all the files to be modified ;-))
-
Open the Find in Files dialog (
Ctrl + Shift + F) -
SEARCH
(?-si)STOP\.ft\h+(\d+(.\d+)?)(?s).+?\1.+?\R\K.+ -
REPLACE
Leave EMPTY -
Type in the file filters and the directory zones
-
Select the
Regular expressionsearch mode -
Click on the
Replace in Filesbutton
Voila !
Best Regards
guy038
-
-
It works just great!
Thank you very, very, very much!
I was so frustrated, it’s unbelievable.
Definitely I have to spend much more time on learning this, it’s absolutely worth it.
Thank you again.Best Regards
LB -
Hi, @leszek-bednarski,
I realize that I made a mistake in my previous search regex ! The correct version is :
SEARCH
(?-si)STOP\.ft\h+(\d+(\.\d+)?)(?s).+?\1.+?\R\K.+
^
I added a baskslash\before the., as we need a literal dot, only, in the decimal number !
Now, some explanations about this search regex, which, I admit, is very complicated !
-
First the
(?-si)in-line modifiers :-
Ensures that the regex dot symbol represents a single standard character and not a
line-breakcharacter(?-s) -
Carries the search in a non-insensitive way
(?-i)
-
-
Then, the pattern
STOP\.ftsearches for the literal string STOP.ft. Note that the special regex symbol.must be escaped to be considered as a literal -
Now, the part
\h+(\d+(.\d+)?)looks for some horizontal blank characters ( mainlyTaborSpace)\h+, before a number\d+, possibly followed with a decimal part(\.\d+)?. Note that the?quantifier means{0,1} -
As the entire number ( integer or decimal) is embedded in parentheses, it is stored as group
1 -
Then, the
(?s)in-line modifier means that, from now on, a dot pattern may match any character, even EOL ones -
And the
.+?\1syntax matches the smallest range of any character.+?till the next group1number, so\1 -
Now, the
.+?\Rpattern matches the smallest range of any character.+?till EOL characters\R( So all remaining characters of the line after the6540.5number ) -
Finally, with the
\K.+:-
Due to the
\Ksyntax forces the regex engine to forget anything that has been matched so far -
This time, the
.+, with a greedy quantifier matches the greatest range of characters till… the end of current file. This final range is, indeed, the range of characters to be deleted, during the replacement phase !
-
- For a quick overview of regular expressions, begin here :
https://www.regular-expressions.info/quickstart.html
- On the official N++ documentation, refer to :
https://npp-user-manual.org/docs/searching/#regular-expressions
- You’ll find additional information here
Good luck with your learning of regular expressions ;-))
Best Regards,
guy038
-
-
Hello @guy038,
Thank you very much! Not only for the help but also the very detailed, valuable explanations and references.
At this point in my learning curve, it so complicated that it is just blowing my mind :)Best Regards
LB
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login