RegEx: step by step
-
before:
a cd eg g h ik
it should look like this:
A Cd Eg G H IkI want to do it step by step (Replace)
1 A cd eg g h ik
2 A Cd eg g h ik
3 A Cd Eg g h ik
4 A Cd Eg G h ik
5 A Cd Eg G H ik
6 A Cd Eg G H Ikstep by step: it works
a cd eg g h ik
(?<=^)(.)
\u$0
A cd eg g h ikstep by step: does not work
a cd eg g h ik
(?<=\s)(.)
\u$0
a cd eg g h ikWhere is the mistake?
-
@Pan-Jan said in RegEx: step by step:
I want to do it step by step (Replace)
Firstly, use of the look behind can be problematic as you have seen. @guy038 had a recent post explaining it in some detail. Have a look at
https://community.notepad-plus-plus.org/topic/19006/regex-positive-look-behind-with/6
and maybe you can see the reason why. Otherwise since I’ve referred to @guy038, he may well pop his head in and explain again. From my perspective the look-behind is constrained by a fixed width, thus where ever the cursor is your look-behind ONLY looks back 1 character. It’s also explained at:
https://www.rexegg.com/regex-disambiguation.htmlI looked at a different idea and my Replace function regex is:
Find What:(^|\s).
Replace With:\U$0\EI’m not entirely happy with the replacement field, for 2 reasons. Firstly it does attempt to convert the zero width “start of line” or the space to uppercase. Of course that doesn’t cause an issue but I feel it’s bad programming. Secondly it didn’t work with the
\umodifier (which is only for a single character), thus I used the\Uand\Eas replacements. In saying that, it does work in the single step replacement which is your original issue.Terry
-
Thanks, big U … gets the job done
uppercase
\u = [[:upper:]]
\U = [^[:upper:]]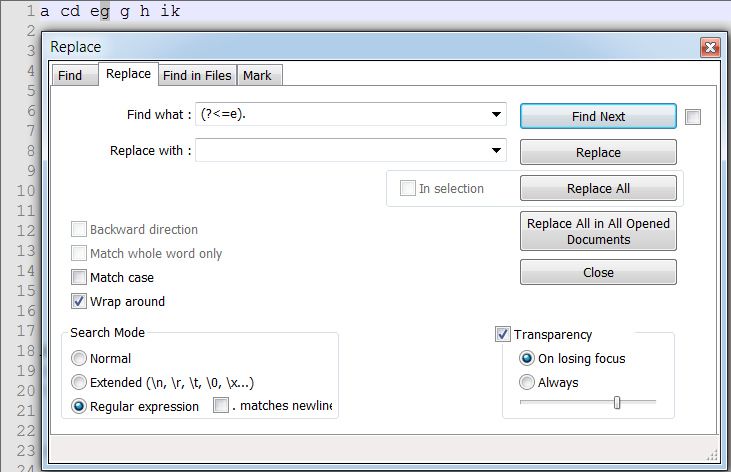
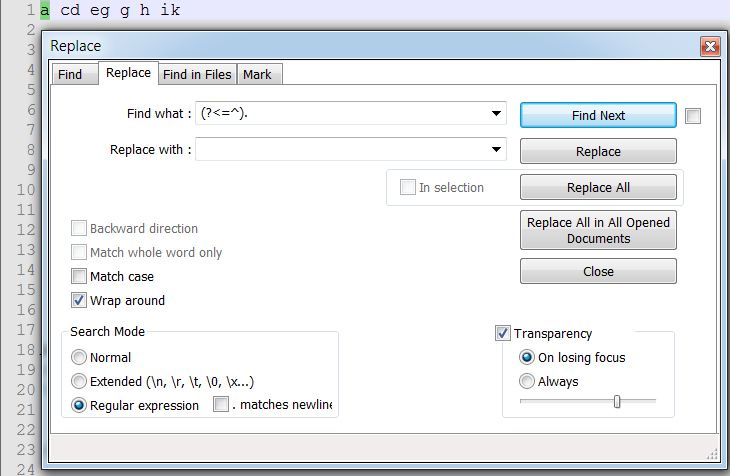
Why is there a bug here?
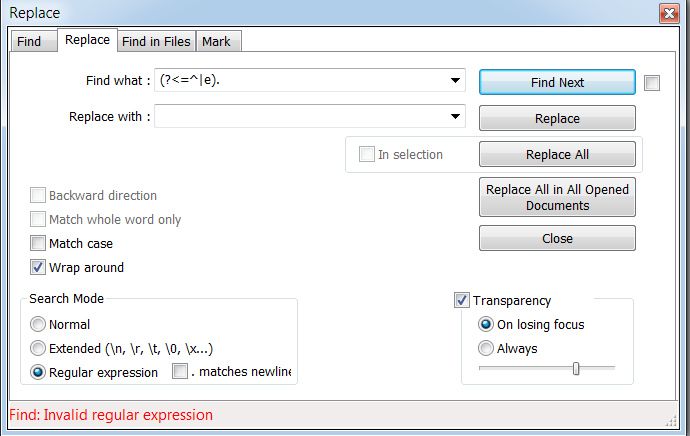
-
I don’t think that is a bug. I believe it’s the issue I mentioned. Your look behind is NOT a fixed width. The ^ is a zero width “character”, start of line. The “e” is 1 character wide. That probably makes the regex invalid.
My regex solution definitely isn’t great. It was made in a hurry to test my idea. There is bound to be a much better solution for your example.
Terry
-
I already know.
(?<=^A.+M)XYZ are forbiddenI can answer in 20 minutes.
It’s not very smart and editing before 3 minutes too -
@Pan-Jan said in RegEx: step by step:
I can answer in 20 minutes.
You have to get a reputation score of 2+ before the 20 minute thing is removed for your account.
With the quality of your postings, I wish you good luck with that. -
@Terry-R said in RegEx: step by step:
I’m not entirely happy with the replacement field, for 2 reasons.
Now that I’ve had a bit more time to look at the question my final regex is:
Find What:\w+
Replace With:\u$0As the
\uwill ONLY convert the first character of anything following it to upper case we don’t need to worry that $0 actually contains the entire “word”, not JUST the first character.Terry
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login