FunctionList help
-
I have created structure to my code to make it easier to organize/navigate. I would like to capture the structure within the FunctionList for easier navigation. The just cant get the functionlist syntax to create it myself wondering if you can assist.
- class name: SCSFExport scsf_<capture this text as class>(SCStudyInterfaceRef sc)
- function name: //reg @<capture this text as function to class>
- comments: // or /* */
so the code below should return this structure.
ClassNameExample
– chartSettings
– defaultSettings
– create_NewOrders
AnotherClassName
– BuyOrders
– SellOrders
SCSFExport scsf_ClassNameExample(SCStudyInterfaceRef sc)
//reg @chartSettings
<code to process>
//end//reg @defaultSettings
<code to process>
//end//reg @Create_NewOrders
<code to process>
//end
SCSFExport scsf_AnotherClassName(SCStudyInterfaceRef sc)
//reg @BuyOrders
<code to process>
//end
//reg @SellOrders
<code to process>
//end -
@JR ,
I will help some, but it won’t answer everything.
Please see the Function List FAQ in this forum for more details.
As a first problem, your “comment” definition, which can start with
//, is mutually exclusive with your function name definition, which starts with//reg. If you define commentExpr to include//, the parser will never see your//regbecause it’s already matched and thrown out everything after the//. (*1)So, for a first attempt, I am not including a commentExpr.
Ignoring classes for a moment, I was able to get it to recognize function names:
<association id="fn_scs19948" userDefinedLangName="udl_scs19948" /> <association id="fn_scs19948" ext=".19948" /> ... <parser id="fn_scs19948" displayName="udl_scs19948"> <function mainExpr="//reg @\w+"> <functionName> <nameExpr expr="(?<=//reg @)\w+" /> </functionName> </function> </parser>After saving that and reloading, with a file with the udl_scs19948 active (*2), I was able to see the functions, but without class names, of course.
Unfortunately, when i tried to add in the
<classRange>with an expression akin toSCSFExport \w+\s*\(SCStudyInterfaceRef sc\), it never seemed to match that in the parser, even though that regex found the class rows in the example code I pasted from your post. It probably needs something in the regex or additional attributes to extend the range start and range stop, but I’m not sure how exactly that works for classes that don’t have obvious { and } to wrap them.The real expert on function list here is @MAPJe71, the author of the Function List FAQ. He might chime in, but he’s not necessarily here every day, so you might have to be patient. Maybe someone else can expand on my work to get you closer.
-–
*1 I had a thought on this after my experiments were done and I had deleted them. If you use a negative lookahead, you might be able to say that commentExpr=“//(?!reg).?$|/*.*/”, which I think will be close to what is needed (I tested the regexp manually, but didn’t put it back into a functionList parser)
*2 the name of my UDL was chosen by the “SCS” in your class-name identifier, and from the post# in the URL of this post -
@PeterJones said in FunctionList help:
Please see the Function List FAQ in this forum for more details.
I was surprised to see that that FAQ didn’t have a link to MAPJe71’s github site that was mentioned recently HERE. It seems like that would be a great resource to know about, for people wanting to work with function-list setup.
-
@PeterJones thanks for the help
i should of mentioned my file is ext .cpp Just like C++ file, its a software that uses C++ but they built an API off of C++ so the extension file is .cpp
i have copied your code and cannot get it to return the functions. I can go to an online Regex playground and return the Class and functions, but when i try and translate it into the FunctionList.xml it fails
<NotepadPlus> <functionList> <associationMap> <!-- ======================================================================== --> <association id="SierraChart" userDefinedLangName="SierraChart" /> <association id="SierraChart" ext=".cpp" /> <!-- ======================================================================== --> </associationMap> <parser id="SierraChart" displayName="SierraChart"> <function mainExpr="//reg @\w+"> <functionName> <nameExpr expr="(?<=//reg @)\w+" /> </functionName> </function> </parser> </parsers> </functionList> </NotepadPlus> -
<!-- ======================================================================== --> <association id="SierraCharts" userDefinedLangName="SierraCharts" /> <association id="SierraCharts" ext=".cpp" /> <!-- ======================================================================== --> </associationMap> <parser displayName="SierraChart" id="SierraChart" > <classRange mainExpr ="(^SCSFExport) ([\s\S]+\n?) (?=SCSFExport)" > <className> <nameExpr expr="([A-Z])\w+"/> </className> <function mainExpr = "//reg @([\s\S]+?)\n" > <functionName> <funcNameExpr expr = "\B(\@[a-zA-Z_]+\b)(?!;)" /> </functionName> </function> </classRange> </parser> -
@JR said in FunctionList help:
i have copied your code and cannot get it to return the functions. I can go to an online Regex playground and return the Class and functions, but when i try and translate it into the FunctionList.xml it fails
For the FUNCTION only version:
I have grabbed a fresh copy of NPP.v7.8.9-64 and unzipped to a known location, and started from there.
I defined a UDL called “SierraChart” with extension.cpp:

When I add the
<associationentries and<parserentry in the appropriate locations, it works for me as I would expect for functions only:
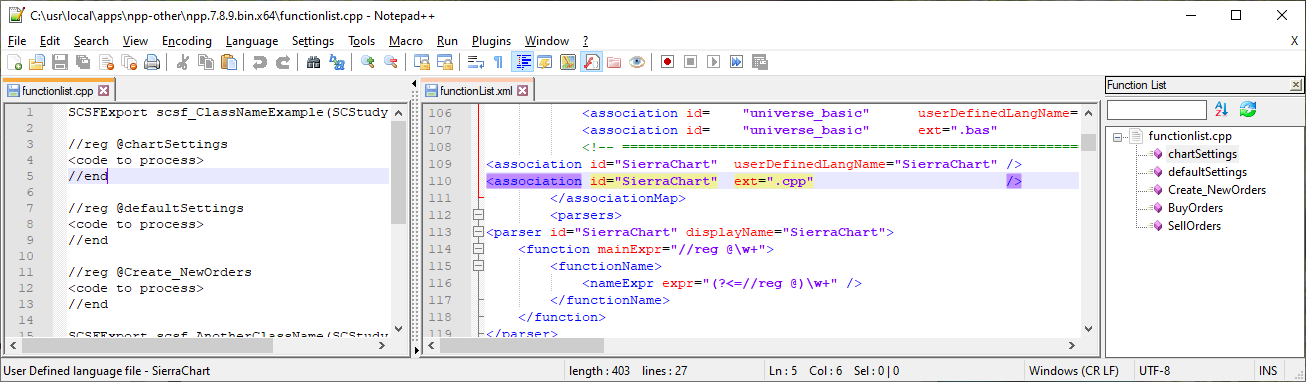
Please note that in the code you posted for the FUNCTION-only version, you did not have the
<parser ...>entry inside of the<parsers>tag: I don’t know if that was real, or a result of your pruning for the forum. My excerpt can be seen in the screenshot, and here is a direct copy paste, where there is stuff before and after, but everything shown is exactly contiguous:<association id="SierraChart" userDefinedLangName="SierraChart" /> <association id="SierraChart" ext=".cpp" /> </associationMap> <parsers> <parser id="SierraChart" displayName="SierraChart"> <function mainExpr="//reg @\w+"> <functionName> <nameExpr expr="(?<=//reg @)\w+" /> </functionName> </function> </parser>Please remember that after you make changes to functionList.xml, you have to exit Notepad++ and reload for it to take effect.
I will try to experiment with the classes next.
-
@JR ,
At first glance, in your CLASS-enabled, I found two bugs
- It’s also not showing the
<parsers>...open tag. Again, that might just be your editing - The
<association...>lines both useSierraCharts(with ansat the end), whereas your first example, and your claim about your UDL, use justSierraChart(with nos). It will not work unless the userDefinedLang name exactly matches the UDL name, and the<parser idexactly matches the<association id.
I will continue to explore, correcting those two bugs.
- It’s also not showing the
-
Continuing, using the example code
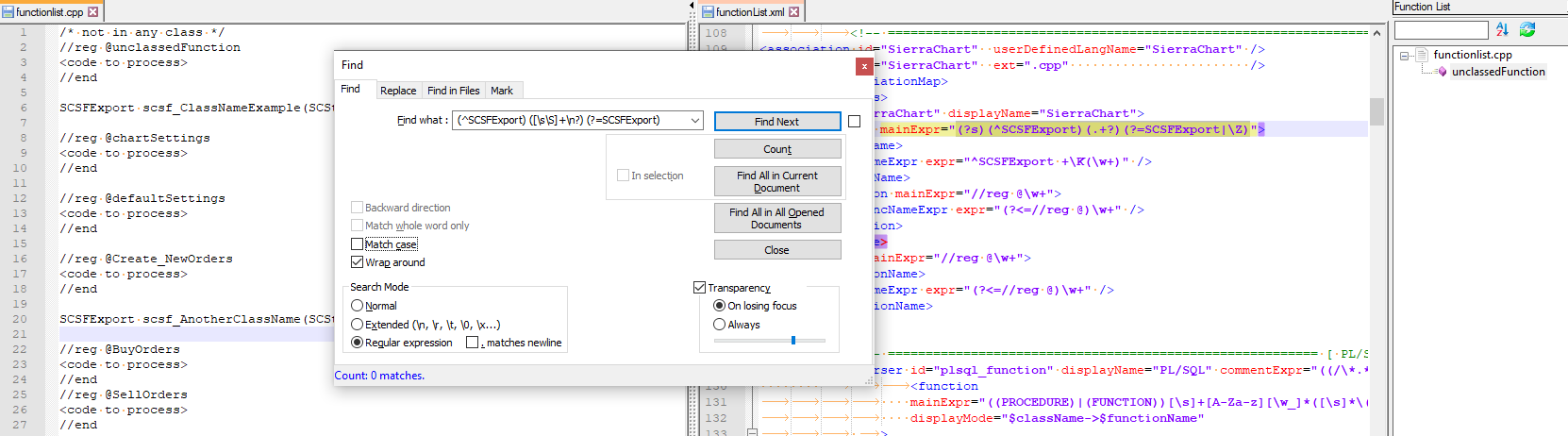
functionlist.cpp:/* not in any class */ //reg @unclassedFunction <code to process> //end SCSFExport scsf_ClassNameExample(SCStudyInterfaceRef sc) //reg @chartSettings <code to process> //end //reg @defaultSettings <code to process> //end //reg @Create_NewOrders <code to process> //end SCSFExport scsf_AnotherClassName(SCStudyInterfaceRef sc) //reg @BuyOrders <code to process> //end //reg @SellOrders <code to process> //endWhen I use your regular expression for the class section,
(^SCSFExport) ([\s\S]+\n?) (?=SCSFExport), in the normal Find dialog, I get 0 matches in my example code:
If I tweak that to
(?s)(^SCSFExport)(.+?)(?=SCSFExport|\Z), I get two matches, as I would expect. And if I highlight them, they do what I expect.However, when I plug that into the
functionList.xmland restart,<association id="SierraChart" userDefinedLangName="SierraChart" /> <association id="SierraChart" ext=".cpp" /> </associationMap> <parsers> <parser id="SierraChart" displayName="SierraChart"> <classRange mainExpr="(?s)(^SCSFExport)(.+?)(?=SCSFExport|\Z)"> <className> <nameExpr expr="^SCSFExport +\K(\w+)" /> </className> <function mainExpr="//reg @\w+"> <funcNameExpr expr="(?<=//reg @)\w+" /> </function> </classRange> <function mainExpr="//reg @\w+"> <functionName> <nameExpr expr="(?<=//reg @)\w+" /> </functionName> </function> </parser>my function list only showed the one
unclassedFunction, and didn’t find any of the functions inside classes (in the screenshot above)I’m not sure why it’s not finding the class names or functions within those classes.
Sorry.
-
@PeterJones thanks Peter. ill look into your posts this weekend and see what i can get done. I found a “regex playground” specific to Boost (which allegedly is the Regex engine for NPP). here is a link to the software. its a free download
-
@PeterJones thanks for taking the time…
here is a pic of just the classes. using the BoostRegex playground software it captures both areas of classes, then specifically the class names.
i also cant get it to work (i fixed the userLang issue, also i kept only the classes to test, removed any function expr.)
-
Hello @JR, @Peterjones, @alan-kilborn and All,
Thank you, @JR, to let us discover
Boost Regex Playground v1.1, a regular expression tester, specific to the Boost library :-))After some tests, here are some notes, in any order :
-
Boost Regex Playground v1.1uses the Boost library with documentation version1.50. But since itsv7.7version, Notepad++ uses an updated version : the Boost documentation1.70, which allow, for instance, the use of backtracking control verbs, like(*FAIL)or(*PRUNE), not taken in account by theBoost Regex Playground v1.1software ! -
By default, this software uses the
mod_sflag, so the in-line modifier(?s). Generally, in order that any dot char represents a single standard character only, two possibilities :-
Use the in-line modifier
(?-s)in the regex -
Tick the
no_mod_sflag
-
-
As examples, try the regexes, below :
-
a a # aawith the flagmod_x[(?x)] or without -
^[a\x20\#r\n]*?$with the flagno_mod_m[(?-m)] or without -
^.*with the flagno_mod_s[(?-s)] or without
-
Against this TWO-lines text :
aaaaaaaaaaaaaa a # aaaaaaaaaa aaaaaa aaaaaaaa-
It’s also worth to note that :
-
By clicking on the
...marker, you can modify the size of any sub-windows -
After clicking inside any sub-windows, you can zoom in or out each sub-window, by hitting the
Ctrlkey and moving the mouse wheel, up or down
-
-
The match flags
format_no_copyandformat_first_onlymay be interesting, too, in replacements
Best Regards,
guy038
-
-
Hi, @JR, @Peterjones, @alan-kilborn and All,
While testing the regex tester software, provided by @JR, I wanted to verify if it knew the
\x{hhhhh}syntax in order to search any character with code-point over\x{FFFF}as I know that the N++ Boost regex engine does not know this one :-((Unfortunately, it does not know this syntax, as well ! But, then, I remembered that Notepad++ can use the surrogates mechanism, to search for all characters which lie outside the Basic Multilingual Plane ( BMP ) ! And the Boost Regex Playground software, too !
For a full explanation about the two 16-bits code units, called a surrogates pair, refer to :
https://en.wikipedia.org/wiki/UTF-16#Code_points_from_U+010000_to_U+10FFFF
For the calculus of the surrogates pair of a specific character, refer, either , to :
http://www.russellcottrell.com/greek/utilities/SurrogatePairCalculator.htm
http://www.cogsci.ed.ac.uk/~richard/utf-8.cgi?
The surrogate pair of a character, with code-point in range from
\x{10000}till\x{10FFFF}, can be described by the regex :\x{hhhh}\x{iiii}whereD800< hhhh <DBFFandDC00< iiii <DFFFFor instance, the pictograph 🧀 ( A cheese wedge ), of code-point
\x{1F9C0}cannot be searched with this syntax. As its surrogates pair isD83E + DDC0, we can searched this specific character from within N++, with the regex syntax\x{D83E}\x{DDC0}If we use the free-spacing mode, for a better visibility, we may note that two syntaxes, only, are correct !
(?x) [\x{D83E}] [\x{DDC0}] # Wrong syntax (?x) [\x{D83E}] \x{DDC0} # Wrong syntax (?x) \x{D83E} [\x{DDC0}] # CORRECT syntax (?x) \x{D83E} \x{DDC0} # CORRECT syntaxIn order to match any character outside the BMP, use one of the two general syntaxes, below :
-
.[\x{DC00}-\x{DFFF}]which begins with a dot symbol -
[^\x{0000}-\x{D7FF}\x{E000}-\x{FFFF}]as the surrogates zone lies between\xD800and\xDFFF
Strangely, the more rigorous syntax
(?x) [\x{D800}-\x{DBFF}] [\x{DC00}-\x{DFFF}]does not work !?You may get some additional information, consulting these two posts :
https://community.notepad-plus-plus.org/post/51068
https://community.notepad-plus-plus.org/post/43037
So I said to myself : Is there a way to get, for instance, the surrogates syntax
\x{D83E}\x{DDC0}from the\x{1F9C0}syntax ? Yes, there a method, described in the Wikipedia article, which may be solved with4consecutive regex S/R ! And the good news is that I succeeded to gather these4regex S/R in an unique macro, described, below ;-))Example :
The string 𝅘𝅥𝅮 — 🧀, in theory, could be searched with the regex
\x{1D160}\x20\x{2014}\x20\x{1F9C0}. ( BTW, the\x{2014}represents the EM DASH character—! )So, starting with the regex
\x{1D160}\x20\x{2014}\x20\x{1F9C0}:In the first regex S/R, we identify, exclusively, the syntaxes from
\x{10000}till\x{10ffff}, adding the C1-Control code\x1F, after each code-point> \x{FFFF}=>
\x{1D160 }\x20\x{2014}\x20\x{1F9C0 }IMPORTANT : This control code
\x1Fcannot be seen on our site, but is well displayed as theUSchar, in reverse video, from within Notepad++ !In the second S/R, we rewrite the code-points >
\x{FFFF}, in binary, minus the value\x{100000}=>
\x{00001101000101100000 }\x20\x{2014}\x20\x{00001111100111000000 }In the third S/R, we rewrite the
20bytes, of each code-point, in two blocks of10bytes, adding the leading parts110110and110111, as described in the Wikipedia article=>
\x{1101100000110100 }\x{1101110101100000 }\x20\x{2014}\x20\x{1101100000111110 }\x{1101110111000000 }In the fourth S/R we reconstitute the surrogates pairs, of each code-point, by conversion of each
16 bytesblock, from binary to hexadecimal and we delete of the\x1Ftemporary character=>
\x{D834}\x{DD60}\x20\x{2014}\x20\x{D83E}\x{DDC0}
The different search and replacement regexes are stored in a macro, below. Just insert it in the
<Macros>....</Macros>node of your active shortcut.xml file !<Macro name="Conversion to Surrogates Pairs" Ctrl="no" Alt="no" Shift="no" Key="0"> <Action type="3" message="1700" wParam="0" lParam="0" sParam="" /> <Action type="3" message="1601" wParam="0" lParam="0" sParam="(?-i)\\x\{(10|[[:xdigit:]])[[:xdigit:]]{4}" /> <Action type="3" message="1625" wParam="0" lParam="2" sParam="" /> <Action type="3" message="1602" wParam="0" lParam="0" sParam="$0\x1F" /> <Action type="3" message="1702" wParam="0" lParam="640" sParam="" /> <Action type="3" message="1701" wParam="0" lParam="1609" sParam="" /> <Action type="3" message="1700" wParam="0" lParam="0" sParam="" /> <Action type="3" message="1601" wParam="0" lParam="0" sParam="(?i)(?:(1)|(2)|(3)|(4)|(5)|(6)|(7)|(8)|(9)|(A)|(B)|(C)|(D)|(E)|(F)|(10))(?=[[:xdigit:]]{4}\x1F\})|(?:(0)|(1)|(2)|(3)|(4)|(5)|(6)|(7)|(8)|(9)|(A)|(B)|(C)|(D)|(E)|(F))(?=[[:xdigit:]]{0,3}\x1F\})" /> <Action type="3" message="1625" wParam="0" lParam="2" sParam="" /> <Action type="3" message="1602" wParam="0" lParam="0" sParam="(?{1}0000)(?{2}0001)(?{3}0010)(?{4}0011)(?{5}0100)(?{6}0101)(?{7}0110)(?{8}0111)(?{9}1000)(?{10}1001)(?{11}1010)(?{12}1011)(?{13}1100)(?{14}1101)(?{15}1110)(?{16}1111)(?{17}0000)(?{18}0001)(?{19}0010)(?{20}0011)(?{21}0100)(?{22}0101)(?{23}0110)(?{24}0111)(?{25}1000)(?{26}1001)(?{27}1010)(?{28}1011)(?{29}1100)(?{30}1101)(?{31}1110)(?{32}1111)" /> <Action type="3" message="1702" wParam="0" lParam="640" sParam="" /> <Action type="3" message="1701" wParam="0" lParam="1609" sParam="" /> <Action type="3" message="1700" wParam="0" lParam="0" sParam="" /> <Action type="3" message="1601" wParam="0" lParam="0" sParam="([01]{10})([01]{10})(?=\x1F)" /> <Action type="3" message="1625" wParam="0" lParam="2" sParam="" /> <Action type="3" message="1602" wParam="0" lParam="0" sParam="110110\1\x1F}\\x{110111\2" /> <Action type="3" message="1702" wParam="0" lParam="640" sParam="" /> <Action type="3" message="1701" wParam="0" lParam="1609" sParam="" /> <Action type="3" message="1700" wParam="0" lParam="0" sParam="" /> <Action type="3" message="1601" wParam="0" lParam="0" sParam="(?:(0000)|(0001)|(0010)|(0011)|(0100)|(0101)|(0110)|(0111)|(1000)|(1001)|(1010)|(1011)|(1100)|(1101)|(1110)|(1111))(?=[[:xdigit:]]*\x1F\})|\x1F" /> <Action type="3" message="1625" wParam="0" lParam="2" sParam="" /> <Action type="3" message="1602" wParam="0" lParam="0" sParam="(?{1}0)(?{2}1)(?{3}2)(?{4}3)(?{5}4)(?{6}5)(?{7}6)(?{8}7)(?{9}8)(?{10}9)(?11A)(?12B)(?13C)(?14D)(?15E)(?16F)" /> <Action type="3" message="1702" wParam="0" lParam="640" sParam="" /> <Action type="3" message="1701" wParam="0" lParam="1609" sParam="" /> </Macro>
From the table, below, where are some characters with code-point over
\x{FFFF},•-----------•-----------•-----------------------------•--------------------• | Hex code | Character | Unicode Name | Surrogates pair | •-----------•-----------•-----------------------------•--------------------• | 2014 | — | EM DASH | N/A | | | | | | | 10000 | 𐀀 | LINEAR B SYLLABLE B008 A | \x{D800}\x{DC00} | | 10195 | 𐆕 | ROMAN SILIQUA SIGN | \x{D800}\x{DD95} | | 1D160 | 𝅘𝅥𝅮 | EIGHTH NOTE | \x{D834}\x{DD60} | | 1F0A1 | 🂡 | ACE OF SPADES | \x{D83C}\x{DCA1} | | 1F30D | 🌍 | EARTH GLOBE EUROPE-AFRICA | \x{D83C}\x{DF0D} | | 1F385 | 🎅 | FATHER CHRISTMAS | \x{D83C}\x{DF85} | | 1F600 | 😀 | GRINNING FACE | \x{D83D}\x{DE00} | | 1F78B | 🞋 | ROUND TARGET | \x{D83D}\x{DF8B} | | 1F845 | 🡅 | UPWARDS HEAVY ARROW | \x{D83E}\x{DC45} | | 1F9C0 | 🧀 | CHEESE WEDGE | \x{D83E}\x{DDC0} | | FFFFD | | <private-use-FFFFD> | \x{DBBF}\x{DFFD} | | 10FFFD | | <private-use-10FFFD> | \x{DBFF}\x{DFFD} | •-----------•-----------•-----------------------------•--------------------•I invented this little text :
Here are some pictographs, with code-point over \x{FFFF} : The INITIAL U+10000 char (old Greek syllable) 𐀀 — the roman "siliqua" coin 𐆕 — An eighth note 𝅘𝅥𝅮 — the ace of spades 🂡 — the Earth globe 🌍 — Father Christmas 🎅 — a grinning face 😀 — a round target 🞋 — an upwards heavy arrow 🡅 — a cheese wedge 🧀 — the private-use U+FFFFD char and the FINAL private-use U+10FFFD char In theory, the regex :
(?-i)Here are some pictographs, with code-point over \\x\{FFFF\} : The INITIAL U\+10000 char \(old Greek syllable\) \x{10000} \x{2014} the roman "siliqua" coin \x{10195} \x{2014} An eighth note \x{1D160} \x{2014} the ace of spades \x{1F0A1} \x{2014} the Earth globe \x{1F30D} \x{2014} Father Christmas \x{1F385} \x{2014} a grinning face \x{1F600} \x{2014} a round target \x{1F78B} \x{2014} an upwards heavy arrow \x{1F845} \x{2014} a cheese wedge \x{1F9C0} \x{2014} the private\-use U\+FFFFD char \x{FFFFD} and the FINAL private\-use U\+10FFFD char \x{10FFFD}should match the text above ! However, as we get the error message
FIND: Invalid regular expression. Then :-
Select all this initial search regex expression
-
Run the macro
Macros > Conversion to Surrogates Pairsand, at once, the search regex, still selected, is changed as :
(?-i)Here are some pictographs, with code-point over \\x\{FFFF\} : The INITIAL U\+10000 char \(old Greek syllable\) \x{D800}\x{DC00} \x{2014} the roman "siliqua" coin \x{D800}\x{DD95} \x{2014} An eighth note \x{D834}\x{DD60} \x{2014} the ace of spades \x{D83C}\x{DCA1} \x{2014} the Earth globe \x{D83C}\x{DF0D} \x{2014} Father Christmas \x{D83C}\x{DF85} \x{2014} a grinning face \x{D83D}\x{DE00} \x{2014} a round target \x{D83D}\x{DF8B} \x{2014} an upwards heavy arrow \x{D83E}\x{DC45} \x{2014} a cheese wedge \x{D83E}\x{DDC0} \x{2014} the private\-use U\+FFFFD char \x{DBBF}\x{DFFD} and the FINAL private\-use U\+10FFFD char \x{DBFF}\x{DFFD}-
Select again the search, mark or replace dialog
-
This time, it should match, as expected, the text above ;-))
Notes :
-
The macro does not change any
\xhh,\x{hh}or\x{hhhh}syntaxes, found in the selection -
The hexadecimal values can be written, in either upper or lower case !
-
Of course, you may just want to know the surrogates pair of a specific character
\x{hhhhh}by selecting the string\x{hhhhh}and running theConversion to Surrogates Pairsmacro !
Best Regards,
guy038
-
-
Hi, all,
Arrrrrrh ! My God ! Right after posting, I realized that my nice theory is, most of the time, rather useless :-(
Really, using the example, given in my previous post :
Here are some pictographs, with code-point over \x{FFFF} : The INITIAL U+10000 char (old Greek syllable) 𐀀 — the roman "siliqua" coin 𐆕 — An eighth note 𝅘𝅥𝅮 — the ace of spades 🂡 — the Earth globe 🌍 — Father Christmas 🎅 — a grinning face 😀 — a round target 🞋 — an upwards heavy arrow 🡅 — a cheese wedge 🧀 — the private-use U+FFFFD char and the FINAL private-use U+10FFFD char -
Just select all this text
-
Open the Find dialog (
Ctrl + F) -
Choose the
Normalsearch mode -
Click on the
Find Nextbutton to find any other occurrence of that text !
Also, the interest of my demonstration is rather limited, isn’t it?
Cheers,
guy038
-
-
@guy038 said in FunctionList help:
I realized that my nice theory is, most of the time, rather useless
So I guess I am confused by this.
Just select all this text… (and further instructions)
Yes, but isn’t it often the case that you don’t have handy such an exact text you need to search for?
Maybe you need to search for a certain character, and all you have is its code. Example, the cheese wedge from before. You may immediately know that it is
\x{1F9C0}but that’s all you know and you want to search for it.
{kind=link}
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login