How to find the Correct Regex pattern to extract data from a text file
-
Hello,
I want to find the proper Regex syntax or anyother way to extract only the lines matching the attached pattern. The problem is with the Description Column which has text split into Two,Three Or even Four Rows.
1.Is there any way to Mark lines between two dates? so that all the transaction lines get selected?
- Is it possible to Unwrap the Text in “Description” Column so that all the transaction data fits in One line for each date?
-
@Suresh-Reddy said in How to find the Correct Regex pattern to extract data from a text file:
Mark lines between two dates?
Not easily as regex doesn’t understand dates, it’s all just characters. It can’t determine if something is above one number and below another. The number range would likely need to be explicitly (and individually) described, a rather laborious process.
In terms of moving the description onto one line, this should be easy enough although since you only provided an image which could be of data saved in any format Notepad++ may be unable to open that type of file unless a text based file.
In fact I’d suggest that since you are dealing with dates another application such as Excel may be more appropriate as it understands dates and can filter easily on those. It should also be able to adjust the description fields as well
Terry
-
Thank you for the kind reply. Unfortunately I couldn’t attach the .text file here. Is there any way I could attach the sample data here?
Since this is not a delimited file I couldn’t use excel too because of the Description column being split into several rows. If the description column is moved into one line then I could easily use excel further.
Thankyou
-
@Suresh-Reddy Generally we only need to see some examples from the data that is a faithful representation.
To insert example text, insert it into the posting window, highlight it and then click on the</>button you see immediately above the window. If you did want to put a link to entire file, which will be stored on another website in your post please read our FAQ section. One of the posts there shows how to do that, insert website links and many other options.Can you advise what is the extension of the file. Perhaps
.csv?Terry
-
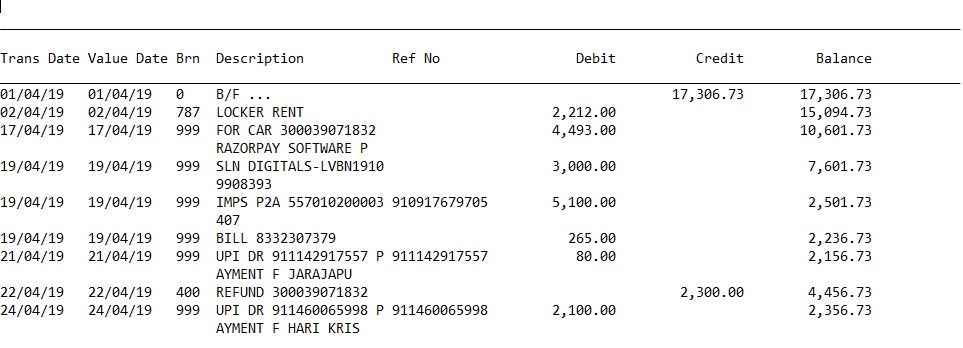
I am attaching the sample text. Please check if this helps else I will upload the full text file. The Description column is sometimes split into two,three,four lines
The extension of the original file is .htm I copied the data from htm to notepad++ and saved in .txt format
Trans Date Value Date Brn Description Ref No Debit Credit Balance ________________________________________________________________________________________________________________________ 01/04/19 01/04/19 0 B/F ... 17,306.73 17,306.73 02/04/19 02/04/19 787 SOCKET RENT 2,212.00 15,094.73 17/04/19 17/04/19 999 FOR CAB 300039071832 4,493.00 10,601.73 TAZORPAY SOFTWARE P URCHASE 19/04/19 19/04/19 999 ALN DITITALS-LVBN1910 3,000.00 7,601.73 9908393 2523 19/04/19 19/04/19 999 IMPS P2A 557010200003 910917679705 5,100.00 2,501.73 407 19/04/19 19/04/19 999 BILL 8332307379 265.00 2,236.73 21/04/19 21/04/19 999 UPI DR 911142917557 P 911142917557 80.00 2,156.73 AYMENT F JARAJAPU 22/04/19 22/04/19 400 REFUND 300039071832 2,300.00 4,456.73 24/04/19 24/04/19 999 UPI DR 911460065998 P 911460065998 2,100.00 2,356.73 AYMENT F HARI KRIS 07/05/19 07/05/19 999 UPI DR 912748447121 P 912748447121 800.00 1,556.73 AYMENT F SAMMANGI 08/05/19 08/05/19 787 787.360.3550 TO 787.3 000000000351 5,00,000.00 5,01,556.73 28.1374 08/05/19 08/05/19 787 G VENKAT GIRI-LAVBR52 9 5,00,000.00 1,556.73 019050800002088 09/05/19 09/05/19 999 UPI DR 912972226147 P 912972226147 1,155.00 401.73 AYMENT F HARI KRIS 15/05/19 15/05/19 787 787.360.3550 TO 787.3 000000000356 5,00,000.00 5,00,401.73 28.1374 15/05/19 15/05/19 787 G VENKAT GIRI-LAVBR52 10 5,00,000.00 401.73 019051500000894 -
Given that text file, it can easily be imported into Excel or another spreadsheet, because one of the options in the text-import is to manually define column widths in terms of number of characters, and you’ve definitely got a fixed-width format there.
Trying to parse a mangled report using regex, instead of using the original data, is really the wrong way to go about things. The right way is to ask for access to the original data in a machine-readable format, and go from there. Or if your goal is just to get a new copy of the report with “better” formatting, then ask for the report to be modified.
If it were my data, and you couldn’t convince anyone to give you access to the data instead of the mangled report, I’d go study the .htm version better – because if it was a well-formed HTML file, all the data for the Description would be in one
<td>cell, rather than being split across multiple<tr>rows. If that’s the case, then parsing the HTML to generate a better report might be easier than parsing this split-row txt. But if the report was horrendously generated, and the HTML really does have the Description split into multiple HTML rows, then working from the text is definitely the way to go.It would be possible to look for lines that begin with 27 spaces instead of beginning with a number using regex… but you’re going to still run into problems that will make the replacement difficult – because you would have to know the maximum number of lines that the Description field was ever split into. (The easiest would probably be to move the whole Description column to the far right, so it can be as long as you want it to be)
You claimed,
The Description column is sometimes split into two,three,four lines
Assuming 4 is the maximum number of lines for a description, I might do something like this two step process – all of these search/replace have Search Mode = Regular Expression set:
- Make sure the “additional” lines all have enough space to make the next step easier:
- FIND =
(?-s)^(\x20{27}.*?)\h*$
Find 27 spaces followed by anything followed by spaces - REPLACE =
$1\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20\x20
Make sure there’s at least 21 spaces after the text
- FIND =
- Join the additional lines into the Description field, and widen the description field when there are fewer than four lines
- FIND =
(?-s)^(\S.{26})(.{21})(.)(.{60})(\R\x20{27}(.{0,21})\h*$)?(\R\x20{27}(.{0,21})\h*$)?(\R\x20{27}(.{0,21})\h*$)?
Make some groups: the first 27 characters, then the 21-character description, then the separator column, then the remaining main line data, then the three optional Description additional texts - REPLACE =
$1$2(?6$6:$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3)(?8$8:$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3)(?10${10}:$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3)$3$4
Include the main data; if the three optional lines are there, use them; otherwise, use the 21 instances of the separator character to pad in that space
- FIND =
But I think you won’t be completely happy with the results. I really think you should ask for the data in a machine-readable format that doesn’t have the line splits to begin with.
If you want to learn more about the syntax, read the official NPP Searching / Regex docs and the forum’s Regular Expression FAQ. You might be able to tweak the regex yourself to make it more to your liking. But really, starting with data that isn’t mangled would be better for you in this instance.
Good luck
- Make sure the “additional” lines all have enough space to make the next step easier:
-
Respected Sir,
Thank you for the very detailed explanation and guidance in the right direction. With the help of your code I was able to achieve desired output. It was an Amazing experience and now I am very curious to learn more about Regex.
The output is almost perfect expect when there are 5 rows ( Maximum Rows). Could you please let me know what changes should be done to the above code when the maximum rows are five. I am sorry as the data was huge I missed it.
Regarding
-
I tried importing the Fixed-Column Width in Excel but I had problem with the Description column which is getting split into Several Columns instead of One . Otherwise It would have been very easy task with the Text-join Function in excel.
-
It’s impossible to convince the people sitting at the helm of affairs of IT, who don’t understand the importance of clean data file. They still use the old legacy report formatting with dot matrix printers.
-
Pasring the HTML is completely a new task for me. I didn’t find any <td> or <tr> rows in the Html report. I just got curious with Notepad++ and Regex because at one instance I could easily extract the first lines of the transactions in the text file using (^\d). I got the first lines copied into excel very easily. Also I removed the header parts with simple find and replace feature of Notepad++.
-
I always cross verify the output with original data which in this case is the closing Balance , Total of Debits & Total of Credits which got tallied with the output of your Regex code.
Thank you
-
-
@Suresh-Reddy said in How to find the Correct Regex pattern to extract data from a text file:
The output is almost perfect expect when there are 5 rows ( Maximum Rows
You would add one more
(\R\x20{27}(.{0,21})\h*$)?to the end, and in the replacement there would be a(?12${12}:$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3)before the$3$4=>- FIND =
(?-s)^(\S.{26})(.{21})(.)(.{60})(\R\x20{27}(.{0,21})\h*$)?(\R\x20{27}(.{0,21})\h*$)?(\R\x20{27}(.{0,21})\h*$)?(\R\x20{27}(.{0,21})\h*$)? - REPLACE =
$1$2(?6$6:$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3)(?8$8:$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3)(?10${10}:$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3)(?12${12}:$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3$3)$3$4
Regarding
- Sorry I wasn’t more clear; in the excel import, I meant to mention that it would require manual (or VBA) merging of the multiple cells for the Description. But since this isn’t an Excel help forum, I didn’t focus my attention on that.
- I understand IT can be difficult. But really the best would be to get a CSV report or other machine-readable rather than a report generated for printing
- “I didn’t find any <td> or <tr> rows in the Html report”: that surprises me, unless everything was in
<pre>, which would be… well, I guess that shouldn’t surprise me.
Good luck.
- FIND =
-
Thank you for the kind help.
The Description column got fully merged into single line, but the end of first line is getting forced into second line though there is sufficient space, with “Enter Symbol” I don’t know the exact name of the symbol. I will try to cut the Description column using “Alt + C” columnar option in Notepad++ and get it copied to excel.
As I am a newbie your code is completely Greek to me , I will try to analyze and learn it step by step and post query if I am not clear on any thing.
-
Sir,
I tried the same logic on Different file (It’s extension is .mht) but it’s not working as desired. I removed the headers using the find and replace option and also shifted the Description column to end using the “ALT + Shift” Column option so that there wouldn’t be a space problem when joining lines. I am attaching the new format. New Line always starts with a date, can we have a regex which can combine multiple rows of description till the next date ( Irrespective of the number of maximum rows they are split). In that way I can use the logic on every file for Extraction of data
01/04/2019 01/04/2019 0.00 0.00 812,430.84 B/F ... 02/04/2019 02/04/2019 000000082847 50,000.00 0.00 762,430.84 SELF CASA. CHEQUE WITHDRAWAL 03/04/2019 03/04/2019 7.20 0.00 762,423.64 SMS ALERT CHG INCL OF GST-Q4 2018 11/04/2019 11/04/2019 910116174465 740.00 0.00 761,683.64 CART CARR PURCHASE-DELICACIES. ISHISHISHISHISIND 15/04/2019 15/04/2019 910306119640 2,813.00 0.00 758,870.64 CART CARR PURCHASE-FINESSE,, ISHISHISHISHISIND 17/04/2019 17/04/2019 0.00 500,000.00 1,258,870.64 UARTHKIEI TRADERS-HDFCR5201904177 4193606 18/04/2019 18/04/2019 0.00 100,000.00 1,358,870.64 IMPS CR.:XX5007:PRI SKUANTESWPS:BILLPAY: 18042019 095225: 910809123296 18/04/2019 18/04/2019 910804827306 10,000.00 0.00 1,348,870.64 ATM. CASH WITHDRAWAL. ON US 18/04/2019 18/04/2019 082848 1,304,334.00 0.00 44,536.64 DLXBR52019041800500142- MANGEENI DOLEIERIES CO LTDThank you
-
This forum isn’t a regex writing service. I’ll give you one last regex for this, but at some point, you need to start studying the regex syntax and figuring it out on your own.
Because it’s at the end of a line, rather than in the middle, it’s much easier. I would check for newline followed by 99 spaces, and replace that with nothing (or with one space):
- FIND =
\R\x20{99} - REPLACE = empty, or a single space, or
\x20 - MODE = regular expression
Determine whether to use a space or empty in the replacement based on whether your data has spaces between last alphanumeric and the line-ending.
- FIND =
-
I forgot I hadn’t shared my generic regex advice. Please read and understand this for any future questions
-—
Do you want regex search/replace help? Then please be patient and polite, show some effort, and be willing to learn; answer questions and requests for clarification that are made of you. All example text should be marked as plain text using the
</>toolbar button or manual Markdown syntax. Screenshots can be pasted from the clipboard to your post usingCtrl+Vto show graphical items, but any text should be included as literal text in your post so we can easily copy/paste your data. Show the data you have and the text you want to get from that data; include examples of things that should match and be transformed, and things that don’t match and should be left alone; show edge cases and make sure you examples are as varied as your real data. Show the regex you already tried, and why you thought it should work; tell us what’s wrong with what you do get… Read the official NPP Searching / Regex docs and the forum’s Regular Expression FAQ. If you follow these guidelines, you’re much more likely to get helpful replies that solve your problem in the shortest number of tries. -
Thank you for the kind help. I am completely new to Notepad++ and Regex. As you have mentioned in the previous about the ease of having description column at end, I tried moving the column to end in Notepad++. However I was not able to figure out the Regex code. I would be patient enough and try the syntax before posting.
-
I have a basic query. How did you find out the number of spaces i.e 99 followed by a new line. Is it manual processes of counting or Does Notepad++ has any feature to find out the same?
Thank you
-
I could have counted the spaces – easier to do with View > Show Symbol > Show Whitespace and TAB
Or, with my cursor at “WITHDRAWL” from your example data, Notepad++ says the cursor is at column 100, which means that there are 99 spaces before:

Or I could select all the spaces, and the status bar tells me the selection is 99 characters wide:

Any of those will work
-
Thank you for the detailed explanation.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login