"Special characters" in Search Results window (encoding issues?)
-
Maybe this opens a can of worms, but I must ask.
The lead-up:
- I recorded a macro for a Find All in Current Document search.
- I edited
shortcuts.xmlto get to the macro’s text. - I changed some text in the macro to use a “special” UTF-8 character in the search term.
- The search works; that isn’t the issue.
The issue is that when I run the macro, what appears in the Search Results window is strange for this character:
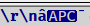
My “special character” is the a-with-the-hat then the black-boxed “APC”, in case that is not obvious. :-)
BTW, the character displays nicely if used in an editor window.
So, in thinking about the “why” of this happening, I start to wonder:
-
Is the search results window set up correctly for UTF-8? Or, alternatively for users of other encodings, is the search results window set up for the same encoding as the editor window that a search is initiated from?
-
What if a user has several files open in tabs that are various different encoding types, and the user runs a Find All in Opened Documents search? All of the results get put into the same result window, so how are the different encodings accounted for in the same window simultaneously?
Any and all input is appreciated.
We seem to be talking about “encoding” a lot lately. -
The usual group of very-opinionated posters have remained silent on this. :-)
Maybe it is a dumb/bad question? -
@Alan-Kilborn said in "Special characters" in Search Results window (encoding issues?):
I know you have access to the find result window, did you try to read the current encoding?
As for the many documents with multiple encodings - your knowledge of
C++ is better than mine - if you haven’t figured it out, I won’t figure it out :-) -
@Ekopalypse said in "Special characters" in Search Results window (encoding issues?):
I know you have access to the find result window, did you try to read the current encoding?
I did not, but that is a good suggestion.
I will do that and report back.your knowledge of
C++ is better than mine
Perhaps only slightly?
Wait, wait, Mr. Ctypes!Truly, though, I thought I was missing something really obvious – how could no one have thought about N++ doing a find-in-files for perhaps many different encodings of the candidate files, and writing content output to a single window that, being a Scintilla buffer window, must have a single encoding specified for it?
-
ctypes
:-D - with a “speakable” language like python - no problema
What I hope npp does is
- read the content from the document and convert it to utf16
- search for the string in utf16 as well
- display the search result in whatever encoding is needs to do
but it looks like this isn’t the case.
-
I realized I could have added more info to my original post:
The character I manually added to my macro was this one:
⟯
which looks like a right-parens but is actually this:
https://graphemica.com/⟯When I put it into
shortcuts.xmlI just pasted it as a single character, but now I notice that it looks like this if I open the xml:⟯This all makes sense as the xml is UTF-8; I just wanted to add the info to the thread.
-
Hi, @alan-kilborn,
Many thanks for pointing us to https://graphemica.com ! Really, this site gives a ton of information on each character ;-))
Just for information :
https://graphemica.com => SEARCH of a SPECIFIC Unicode character https://graphemica.com/characters => List of Unicode CHARACTERS by NAME https://graphemica.com/categories => List of Unicode GENERAL_CATOGORIES https://graphemica.com/blocks => List of Unicode BLOCKS https://graphemica.com/scripts => List of Unicode SCRIPTS https://graphemica.com/unicode/characters => List of Unicode CHARACTERS per PAGE of 256 chars INPUT Examples : Char => Character ITSELF &10180 => CHOICE between character U+10180 and character U+27C4 = U + Hex(10180) #10180 10180 => Character U+10180 ( GREEK FIVE OBOLS SIGN ) 𐆀 ⟄ => Character U+27C4 = U + Hex(10180) ( OPEN SUPERSET )Cheers,
guy038
-
@guy038 said in "Special characters" in Search Results window (encoding issues?):
Many thanks for pointing us to https://graphemica.com ! Really, this site gives a ton of information on each character
It was a site previously unknown to me.
Glad you enjoyed it.
BTW, I found it because I googledE29FAFafter finding that Notepad++ had converted my entry of the UTF-8 character to these codes – my quickest way to explain the “more info” I wanted to provide in my previous post. -
@Ekopalypse said in "Special characters" in Search Results window (encoding issues?):
I know you have access to the find result window, did you try to read the current encoding?
My investigation down this path:
# Get the code page used to interpret the bytes of the document as characters. get int GetCodePage=2137(,)Calling that function on the Find result window results in a
65001being returned.Looking in
scintilla.hI see:#define SC_CP_UTF8 65001So it does appear that the encoding for the Find result window is UTF-8.
Which makes me wonder even more why my UTF-8 character doesn’t show up correctly there.
-
The other usual suspects would be the font and technology (GDI/DirectX).
By the way, which font do you use?
None of my installed fonts show this symbol in the editor. -
@Ekopalypse said in "Special characters" in Search Results window (encoding issues?):
The other usual suspects would be the font and technology (GDI/DirectX).
By the way, which font do you use?I have direct-write enabled.
I play around with different fonts (can’t seem to find the best–for me); “Consolas” is the one currently in favor for me.None of my installed fonts show this symbol in the editor.
You mean this actual character?:
⟯
-
@Alan-Kilborn said in "Special characters" in Search Results window (encoding issues?):
You mean this actual character?:
I guess so, even my browser refuses to display it

But more I think about it, the less I’m convinced that it is a font or technology issue as you do get a representation - just a different one.
-
@Ekopalypse said in "Special characters" in Search Results window (encoding issues?):
What I hope npp does is
- read the content from the document and convert it to utf16
- search for the string in utf16 as well
- display the search result in whatever encoding is needs to do
When I noticed the following in the Scintilla documentation, it reminded me of Eko’s points above:
SCI_ENCODEDFROMUTF8(const char *utf8, char *encoded) → position
SCI_ENCODEDFROMUTF8 converts a UTF-8 string into the document’s encoding which is useful for taking the results of a find dialog, for example, and receiving a string of bytes that can be searched for in the document.I’m not sure what I’m saying by pointing this out; perhaps just noticing a somewhat common theme? :-)
-
since the Windows API uses utf16 for internal storage of strings, this does not sound efficient.
I wonder why the scintilla devs thought that this might be a good idea.
Hmm … most likely because the library is used on different platforms,
but then why not have a compile time variable to convert it to utf16 on Windows and utf8 on Linux … ?? -
In hindsight, I probably shouldn’t have mentioned
SCI_ENCODEDFROMUTF8as I did a search of the Notepad++ source code, and it isn’t used there. -
@Alan-Kilborn said in "Special characters" in Search Results window (encoding issues?):
When I put it into shortcuts.xml I just pasted it as a single character, but now I notice that it looks like this if I open the xml:
⟯So just providing some more data on this, after I experimented with it a bit more:
I see that if I record a macro using the multibyte unicode character (discussed much further up in the thread), instead of “hand editing” shortcuts.xml after-the-fact, when I run the macro I DO see the correct character appearing in the Find result window:
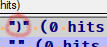
AND…if I later look at the saved xml, I see this for that character in the macro:
⟯Which does indeed make sense.
So perhaps the error was mine and it comes down to directly inserting the unicode character into the XML instead of inserting its
&#x....code. -
More thoughts:
From my immediately preceding post, it follows that anytime a “special” character is used in a N++ configuration xml file, the “html syntax”, example
EFshould be used, rather than inserting the character “directly”, for example via a paste.However, I notice in
english_customizable.xmlthe following, which does not follow this idea:<Item id="1721" name="▲"/> <Item id="1723" name="▼ Find Next"/>But yet these items display correctly…
Okay, different usage from the above; these appear on buttons in the UI, the earlier discussion is some text in the Find result window…But in general, I would be interest to know why these don’t require any special “treatment” in the xml.
Or what is the “rule”?
Always use the “html syntax” seems the “safest”.Ideas? Or is the topic too “meh” for anyone to care? :-)
-
@Alan-Kilborn said in "Special characters" in Search Results window (encoding issues?):
Always use the “html syntax” seems the “safest”.
Ideas? Or is the topic too “meh” for anyone to care? :-)I don’t know enough about XML to know the default encoding, but my guess is Windows-1251.
If you added<?xml version="1.0" encoding="UTF-8" ?>at the beginning of the
shortcuts.xml(and reloaded Notepad++), does that allow you to hand-insert the https://graphemica.com/⟯ or other special character into the macro XML directly? -
@PeterJones said in "Special characters" in Search Results window (encoding issues?):
If you added
First, I’m a bit surprised that after adding that line manually, that Notepad++ allows it to remain (after recording a new macro, forcing N++ to rewrite
shortcuts.xml).Second, it was a good idea, but sadly, after trying it, I get the same result as earlier, specifically, “garbage” characters in the Find result window text.
Third, thanks for the interest, @PeterJones
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login