Finding multiple words inside extra quotes
-
Hello,
I’m using this string to find an incorrectly quoted single word inside of a set of double quote text qualifiers and comma delimiters.
(,“[^”])("\w)(“)([^”]*",)
Finds
,“123 Main St Apt “D””,What modification do I need to make to find multiple words(and possible numbers) like example below?
,“123 Main “St Apt D””,
Thank you in advance for the help!
-
Assuming you meant:
(,"[^"]*)("\w*)(")([^"]*",)as your regex, with real data of,"123 Main St Apt "D"", ,"123 Main "St Apt D"",(so real quotes, not “smart” quotes)
… then the problem is that
("\w*)is looking for word characters only. Spaces are not word characters. If you want word chars or spaces in that match, then make a character class that looks for both:("[\w\s]*)Full regex =
(,"[^"]*)("[\w\s]*)(")([^"]*",)This regex found the two example lines above in my test. If your data is different, it may or may not work for you.
Please notice I used backticks around the regex like
`(,"[^"]*)("[\w\s]*)(")([^"]*",)`, so that the regex would be treated as plain text, and the asterisks wouldn’t be turned into italics by the forum. Similarly, I used the</>forum button (or equivalently, the plaintext markdown syntax```on a line before and after the data) to mark the example text as pure text, so that the forum wouldn’t convert quotes to “smart quotes”.-—
Do you want regex search/replace help? Then please be patient and polite, show some effort, and be willing to learn; answer questions and requests for clarification that are made of you. All example text should be marked as literal text using the
</>toolbar button or manual Markdown syntax. To makeregex in red(and so they keep their special characters like *), use backticks, like`^.*?blah.*?\z`. Screenshots can be pasted from the clipboard to your post usingCtrl+Vto show graphical items, but any text should be included as literal text in your post so we can easily copy/paste your data. Show the data you have and the text you want to get from that data; include examples of things that should match and be transformed, and things that don’t match and should be left alone; show edge cases and make sure you examples are as varied as your real data. Show the regex you already tried, and why you thought it should work; tell us what’s wrong with what you do get. Read the official NPP Searching / Regex docs and the forum’s Regular Expression FAQ. If you follow these guidelines, you’re much more likely to get helpful replies that solve your problem in the shortest number of tries. -
@PeterJones Thank you so much! Yes you were correct with the regex I tried to enter. Showing my noob status with my first post lol. Thank you for the guidance!
Your solution absolutely returned the values I am looking for but I am also getting false positives from every line due to wrap around effect from the end of one line to the next. Here’s the value it returned as a result:
1 ,"CRLF 2 "Field1",I attempted add a piece to not include CR or LR
\r\nto exclude these false positives and was unsuccessful. Is there a way to further refine my search?(,"[^"](^\r\n)*)("[\w\s\]*)(")([^"]*",)However, my incorrect modification actually exposed an issue I didn’t know existed. A misplaced comma delimiter separating double quote text qualifiers. I will be keeping this line of code to identify these issues so I can correct them.
(,"[^"](^\r\n)*)("[\w\s\]*)(")([^"]*",),"123 Main St,","","Dallas",TX"12345"," -
@TexasKCFan said in Finding multiple words inside extra quotes:
(^\r\n)*
Did you mean
[^\r\n]*instead. What you wrote means a group of characters with the start of a line followed by carriage return/line feed, effectively an empty line.Terry
PS I should add that the
*also meant this group can be ignored if not found and the rest of the regex would then be processed. -
Here is the results I get with the solution you gave me. The correct result along with incorrect results from the end of one line to the beginning of the next. I’m trying to figure out what to add so it won’t pick up the false results that include CRLF.

-
@TexasKCFan said in Finding multiple words inside extra quotes:
Here is the results I get with the solution you gave me.
Sorry it was not a solution. I was just pointing out that your requirement to exclude certain characters had been coded incorrectly, and how it might be coded. I didn’t do any tests.
I haven’t been following this thread so don’t feel that I could provide one, others who have already presented some ideas might be the better ones to extend those solutions for your latest request.
Terry
-
My apologies Terry I thought you were Peter. Thank you for the input!
-
(,"[^\r\n][^"]*)("[\w\s]*)(")([^"]*",)This is the solution that worked. I had to include the
\r\nearlier in the line of code so it ignored the CRLF.
This is now the desired result.
Thank you @PeterJones and @Terry-R for your help!
-
Hello @texaskcfan, @Peterjones, @terry-r and All,
@texaskcfan, if I assume that :
-
Your list contains one record per line
-
The field separator is the comma, located right after the previous field and right before the next field
-
Any field is, either :
-
Any text, between two double quotes, beginning a line, possibly preceded with blanks characters and followed with a comma, as
"xxxxxx", -
Any text, between two double quotes, itself surrounded by two commas, as
,"xxxxxx", -
Any text, between two double quotes, preceded by a comma and ending a line or the very end of current file, as
,"xxxxx"CRLF
-
The following regex, containing a recursive pattern, will find all the zones between two commas, which contains an even number of
"( double-quote characters ) :(?x) (?:^\h*|,) (?: ( " (?: [^"\r\n,]++ | (?1) )* " ) )+? (?=,|\R|\z)For instance, given this sample, that you’ll copy in a new tab :
"0","0","","","","","","","","","","","","","" "Field1","Field2","Field3","Field4","Field5","Field6","Field7","Field8","123 Main "St AptD"","","Dallas","TX","12345","","","","","","","","","","","","","","","","","","","","","","","" "Field1","Field2","Field3","Field4","Field5","Field6","Field7","Field8","This fie"ld is NOT correct","","Dallas","TX","12345","","","","","","","","","","","","","","","","","","","","","","","" ," abcde","","ijk "123"," 987 "This is"a small""pie"""ce of"text for" tests" !!","","abc"de"fgh"ij","12345" " abcde","","ijk "123"," 987 "This is"a small""pie"""ce of"text for" tests" !!","","abc"de"fgh"ij","12345" "","","",","","","","" ","","","","","" " """ """ """ " " " " """ """ " 1234567890","","","","","" " abcde","","ijk "123"," 987 "This is"a small""pie"""ce of"text for" tests" !!","","abc"de"fgh"ij","12345"-
Open the Mark dialog (
Ctrl + M) -
Paste the above regex in the
Find what:zone -
Preferably, tick the
Purge for each searchoption -
Possibly, tick the
Wrap aroundoption -
Select the
Regular expressionsearch mode -
Click on the
Mark Allbutton
=> All the fields
,........,containing an even number of"( thus any correct field ), are marked in red style. This means that any zone, still unmarked, contains an odd number of double quotes, probably indicating one"character, too many or too few ;-))Note that, for a correct scanning process of the text, the regex marks from the comma, before each zone
"....."till the", right before the next comma !You may, as well, use the
Finddialog to visualize each correct field, one a a time !Here is a snapshot of the sample, after the mark operation :

As you can see, all the fields non marked are incorrect in some ways and need examination.
Note, also, that it’s impossible build up a regex in order to get the opposite logic, i.e. which would match the general case of any zone, between two commas, containing an odd number of double quotes inside !
Best Regards
guy038
-
-
Hi, @texaskcfan, @Peterjones, @terry-r and All,
@guy038 said :
Note, also, that it’s impossible build up a regex in order to get the opposite logic, i.e. which would match the general case of any zone, between two commas, containing an odd number of double quotes inside !
Well… I was wrong :-( As usual , just when I woke up, I understood the way to do ! We simply must add the two control verbs sequence
(*SKIP)(*F)at the end of the previous regex and add an alternative which selects all standard chars sequence till the nearest comma,character ;-)), giving the final regex :MARK
(?x) (?:^\h*|,) (?: ( " (?: [^"\r\n,]++ | (?1) )* " ) )+? (?=,|\R|\z) (*SKIP) (*F) | (?-s) .+? (?=,|\R|\z)With the same sample as in my previous post, we get, this time :

Now, it’s even more easy to focus our attention on the problem areas !
BR
guy038
-
This post is deleted! -
@texaskcfan, @peterjones, @terry-r and All,
I improved my regex in order to satisfy all the possible cases and get a coherent behavior :
MARK
(?x) (?:^\h*|,) (?: ( " (?: [^"\r\n,]++ | (?1) )* " ) )+? (?=,|\R|\z) (*SKIP) (*F) | (?:^\h*|,) (?: [^"\r\n]+ (?=,|\R|\z) (*SKIP) (*F) | [^,\r\n]+? (?=,|\R|\z) )So, to summarize, this regex will mark, from beginning of line, any possible comma and its next zone, till the nearest comma, excluded, or till the end of line / file, ONLY IF this zone contains an odd number of double quotes
"Just use this sample, below, to test the regex against !
# With 0, 1, 2, 3, 4, 5 or 6 DOUBLE quote(s) and WITHOUT any char between DOUBLE-quotes # => Matches when 1, 3 or 5 DOUBLE quote(s) ( INCORRECT zones ) : ,, ,", ,"", ,""", ,"""", ,""""", ,"""""", # With 0, 1, 2, 3, 4, 5 or 6 DOUBLE quote(s) and with some WORD chars between DOUBLE-quotes # => Matches when 1, 3 or 5 DOUBLE quote(s) ( INCORRECT zones ) : ,, ,", ,"123456", ,"123"456", ,"12"34"56", ,"12"34"56"78", ,"12"34"56"78"90", ,ABCXYZ, ,"ABCXYZ, ,"ABCXYZ", ,"ABC"XYZ", ,"ABC""XYZ", ,"ABC"""XYZ", ,"ABC""""XYZ", ,ABCXYZ, ,ABCXYZ", ,"ABCXYZ", ,"ABC"XYZ", ,""ABCXYZ"", ,""ABC"XYZ"", ,"""ABCXYZ""", # With an EVEN number of DOUBLE quotes ( 4 ) for the STARTING, MIDDLE and ENDING field of a record # => CORRECT zones, NOT matched : "12"345678"90", ,"123"4567"890", ,"1234"56"7890" # With an ODD number of DOUBLE quotes ( 3 ) for the STARTING, MIDDLE and ENDING field of a record # => INCORRECT zones, matched : "12345"67890", ,"12345678"90", ,"12"34567890" # WITHOUT any DOUBLE-quote => All are CORRECT zones, so NOT matched ( indeed ZERO is an EVEN number ! ) , ,, ABCXYZ ABCXYZ, ,ABCXYZ, ,ABCXYZ
And we get the picture :
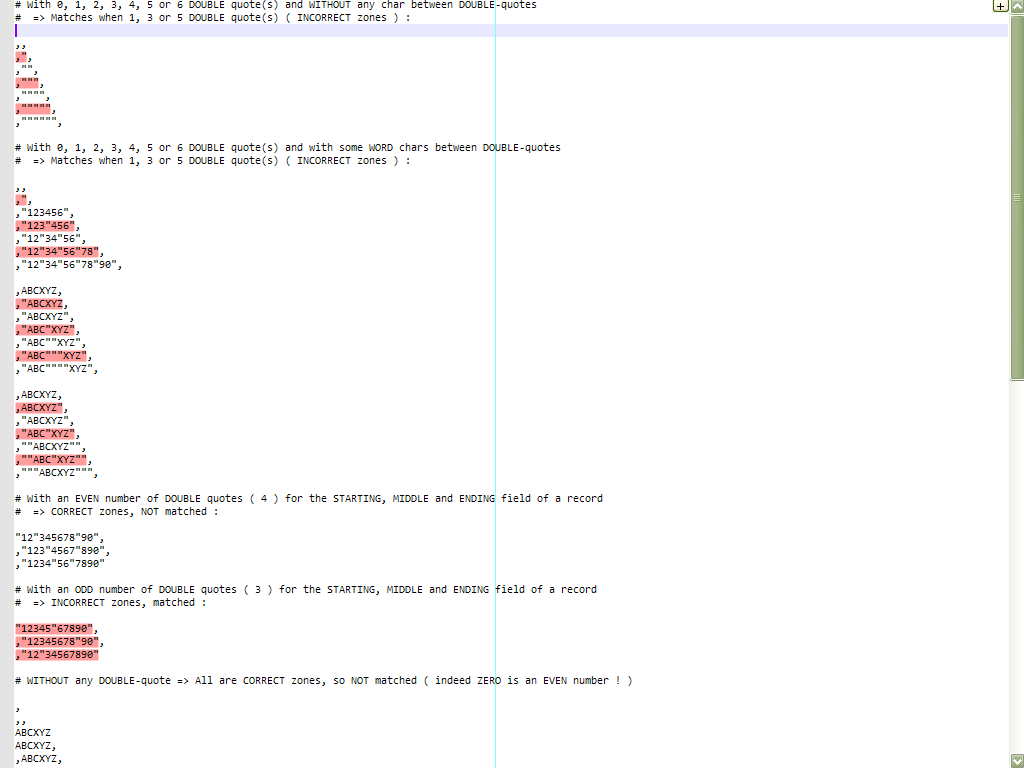
Best Regards,
guy038
-
@guy038 I can’t express how much I appreciate this additional detail! One search string to identify all inconsistencies would be a HUGE time saver. Since many of the files I work with have a couple of hundred thousand lines, my process is to identify the lines with issues, copy them and send them back to the client so they can correct them.
One note on the structure of my data…a successful line is 38 fields in this structure:
"Field 1", "Field 2","Field 3"CRLFData wrapped in a set of double quotes is acceptable regardless of punctuation (a lot of foreign addresses have multiple periods and commas). The issues are caused by extra single or double quotes without the properly associated commas, incorrectly causing the fields to be misaligned. Either one word, or a group of words contains extra single or double quotes without the correctly placed comma creates extra fields. Single quotes can cause an also because the system’s looking for the non-existent matching quote.
"Field "1"", "Fiel'd 1", "Field 1 "but with additional spaces and characters" and extra set of quotes",When I run
(?x) (?:^\h*|,) (?: ( " (?: [^"\r\n,]++ | (?1) )* " ) )+? (?=,|\R|\z) (*SKIP) (*F) | (?-s) .+? (?=,|\R|\z)I see that I’m getting non-error results like:,"123 Main St, Apt Q"While this example is not really correct (Apt Q should be in the next field), it doesn’t cause an issue per se because the whole thing is correctly enclosed in one set of double quotes and there are no extra quotes.
I think the expected error output would be something like this:
"123 Main "St", Apt Q" "123 "Main St, Apt Q"" "123 Main S't, Apt Q"If every line starts with an opening quote, ends with a closing quote, followed by CRLF and all the quotes in between have matching quote with a comma delimiter then I have the correct number of fields and my only concern is when they put the data in the wrong fields which is beyond the scope of this post. :)
Is it possible to make the start and end of the search string double quotes instead of commas so we can identify extra quotes (single or double) that don’t belong?
I’m brand new to the regex world and I truly appreciate the assistance!
-
Hi, @texaskcfan, @peterjones, @terry-r and All,
Well, of course, my previous search is rather academic and not adapted to your own data. It just showed a way to search for an odd number of double quotes in fields defined as below :
-
A field begins after a double quote at beginning of line or after the string
"," -
This same field ends before a next string
","or before an end of line or the very end of current file
And my goal was to demonstrate that this kind of search can be achieved, only with recursive regexes. Indeed, if you lack this kind of regexes, you need to find out one regex which will match zones with
1double quote ONLY, an other regex, which will match zones with3double quotes ONLY, and so on…
But, seemingly, it’s not exactly why you’re posting here !. However, I’m rather confused in some ways, by your last post :
- When you say :
I think the expected error output would be something like this:
“123 Main “St”, Apt Q”
“123 “Main St, Apt Q””
“123 Main S’t, Apt Q”Do you mean that, given a single record of
8fields :CRLFField_1","Field_2","Field_3 with ERROR 1","Field_4","Field_5","Field_6 with ERROR 2","Field_7","Field_8"CRLFYou expect this output :
.... PREVIOUS record .... "Field_1","Field_2"CRLF "Field_3 with ERROR 1"CRLF "Field_4","Field_5"CRLF "Field_6 with ERROR 2"CRLF "Field_7","Field_8"CRLF .... NEXT record ....In other words do you plan to isolate erroneous fields ?
Note that, at this time of the discussion, I don’t care about the errors themselves ! We’ll track them, later, by appropriate regexes !
- Secondly, does your sample text :
"123 Main "St", Apt Q" "123 "Main St, Apt Q"" "123 Main S't, Apt Q"Represent
3fields, one per line, delimited with the outer"characters ?Represent several fields per line. For instance,
"123 "Main St, Apt Q""would have two fields123 "Main StandApt Q", separated with the comma ?-
Thirdly, if we consider any field, with delimiter = beginning or end of line or the string
",", can you show us the different types of strings, containing single and/or double quotes and/or commas, in between, which may occur and which are the ones that you would like to detect as errors ? -
More generally, which further treatment do you expect, when meeting these errors ?
@texaskcfan, it’s important to note that regexes are extremely sensitive to real data used and, although I give some generic regexes for general purposes, in this forum, a regular expression is generally adapted to a specific user and for specific data ;-))
I probably miss a lot of things about your data and your work-flow :-( So, just enlighten me !
See you later,
Best regards,
guy038
P.S. : The best would be that you provides a part of your file, containing a fairly range of records, which identifies the zones to be detected as erroneous !
Finally, if your data is rather confidential, just send me an e-mail at :
-
-
@guy038 My apologies for the confusion. Thank you for the general knowledge for the community!
- Given a single record of 8 fields, I would expect to see it exactly as you posted but minus the CRLF at the beginning and with an opening quote.
"Field_1","Field_2","Field_3 with ERROR 1","Field_4","Field_5","Field_6 with ERROR 2","Field_7","Field_8"CRLF- Yes, I plan to isolate erroneous fields. What I meant to say is these would be the three different examples of errors I would be able to identify in my data. My sample text represented three versions of errors I would find in a single field. A full line would be 38 fields in the format just included above.
“123 Main “St”, Apt Q” - Example of a single word incorrectly encased in double quotes `"St"` “123 “Main St, Apt Q”” - Example of a phrase incorrectly encased in double quotes `"Main St, Apt Q"` “123 Main S’t, Apt Q” - Example of an incorrect single quote `S't`- Yes, my goal is to identify the errors so I can copy the rows and bring them to the client’s attention so the can fix them. I am not correcting the errors, simply identifying them during my pre-processing QA. If I process the files with these errors, the records will not load so I’m attempting to provide additional value to the client. :-)
I will be able to use the solutions above to identify the issues. I will put together a range of records for you to review and post later.
Thank you so much for your help! :-))
-
Hello,@TexasKCFan
Please try this code, To Finding multiple words inside extra quotes
Regex:/^[^"]*("[^"]*"[^"]*)*"[^"]*search[^"]*"/iI hope this code will be useful to you.
Thank you. -
Hello, @texaskcfan, @peterjones, @terry-r and All,
While searching a solution, I realized that the comma delimiter can also be found inside fields themselves ! This is really problematic :(
So, in order to get a neat field delimiter, we should, temporarily, change the
,delimeter by, let’s say, the¤character if this char is not used in your file ! From now on, I suppose that it’s the case :Thus, we first change the field delimiter of your file with the simple normal S/R :
SEARCH
","REPLACE
"¤"Note that you may replace the
¤char with any char not used yet !And, at the very end of the process, you’ll just perform this normal S/R to get the right syntax, again :
SEARCH
¤REPLACE
,
Now, given your
3error cases that you provided, here is my first try towards a complete solution ! I’m using the free-spacing mode(?x)for a better readability !- MARK
(?x) (?:^"|"¤") \K ([^"'¤\r\n]*?) ("|') (?1) \2? (?1) (?="¤"|"\R|"\z)without the outer"chars marked
OR
- MARK
(?x) (?:^|"¤) \K " ([^"'¤\r\n]*?) ("|') (?1) \2? (?1) " (?=¤"|\R|\z)with the outer"chars marked
If we try these two regexes, against this sample text, below :
"Field_1"¤"Field_2"¤"Field_3"¤"Field_4"¤"Field_5"¤"123 Main "St", Apt Q"¤"Field_7"¤"Field_8"¤"Field_9"¤"Field_10" "Field_1"¤"Field_2"¤"Field_3"¤"Field_4"¤"Field_5"¤"Field_6"¤"Field_7"¤"Field_8"¤"Field_9"¤"Field_10" "Field_1"¤"Field_2"¤"Field_3"¤"Field_4"¤"Field_5"¤"Field_6"¤"Field_7"¤"Field_8"¤"Field_9"¤"Field_10" "123 "Main St, Apt Q""¤"Field_2"¤"Field_3"¤"Field_4"¤"Field_5"¤"Field_6"¤"Field_7"¤"Field_8"¤"Field_9"¤"Field_10" "Field_1"¤"Field_2"¤"Field_3"¤"Field_4"¤"Field_5"¤"Field_6"¤"Field_7"¤"Field_8"¤"Field_9"¤"Field_10" "Field_1"¤"Field_2"¤"Field_3"¤"Field_4"¤"Field_5"¤"Field_6"¤"Field_7"¤"Field_8"¤"Field_9"¤"Field_10" "Field_1"¤"Field_2"¤"Field_3"¤"Field_4"¤"Field_5"¤"Field_6"¤"Field_7"¤"Field_8"¤"Field_9"¤"123 Main S't, Apt Q" "Field_1"¤"Field_2"¤"Field_3"¤"Field_4"¤"Field_5"¤"Field_6"¤"Field_7"¤"Field_8"¤"Field_9"¤"Field_10" "Field_1"¤"Field_2"¤"Field_3"¤"Field_4"¤"Field_5"¤"Field_6"¤"Field_7"¤"Field_8"¤"Field_9"¤"Field_10" "Field_1"¤"Field_2"¤"Field_3"¤"Field_4"¤"Field_5"¤"123 Main "St, Apt Q"¤"Field_7"¤"Field_8"¤"Field_9"¤"Field_10" "Field_1"¤"Field_2"¤"Field_3"¤"Field_4"¤"Field_5"¤"Field_6"¤"Field_7"¤"Field_8"¤"Field_9"¤"Field_10" "Field_1"¤"Field_2"¤"Field_3"¤"Field_4"¤"Field_5"¤"Field_6"¤"Field_7"¤"Field_8"¤"Field_9"¤"Field_10" "123 Main St, Apt Q""¤"Field_2"¤"Field_3"¤"Field_4"¤"Field_5"¤"Field_6"¤"Field_7"¤"Field_8"¤"Field_9"¤"Field_10" "Field_1"¤"Field_2"¤"Field_3"¤"Field_4"¤"Field_5"¤"Field_6"¤"Field_7"¤"Field_8"¤"Field_9"¤"Field_10" "Field_1"¤"Field_2"¤"Field_3"¤"Field_4"¤"Field_5"¤"Field_6"¤"Field_7"¤"Field_8"¤"Field_9"¤"Field_10" "Field_1"¤"Field_2"¤"Field_3"¤"Field_4"¤"Field_5"¤"Field_6"¤"Field_7"¤"Field_8"¤"Field_9"¤"123 Main S't, A'pt Q" "Field_1"¤"Field_2"¤"Field_3"¤"Field_4"¤"Field_5"¤"Field_6"¤"Field_7"¤"Field_8"¤"Field_9"¤"Field_10" "Field_1"¤"Field_2"¤"Field_3"¤"Field_4"¤"Field_5"¤"Field_6"¤"Field_7"¤"Field_8"¤"Field_9"¤"Field_10" "123 "Main St, Apt Q""¤"Field_2"¤"Field_3"¤"Field_4"¤"Field_5"¤"123 Main "St", Apt Q"¤"Field_7"¤"Field_8"¤"Field_9"¤"123 Main S't, Apt Q" "Field_1"¤"Field_2"¤"Field_3"¤"Field_4"¤"Field_5"¤"Field_6"¤"Field_7"¤"Field_8"¤"Field_9"¤"Field_10"
we get :

-
In that sample, I simply consider lines of
10fields -
In lines
4,7and10, you’ll recognize your3error cases -
In lines
14,17and20, I deleted one double quote and added one single quote, which are also correctly detected as a possible error by the regex. But, If you do not need the detection of these extra cases, I won’t have any problem to modify the regex -
In line
24, I added a record with the3error cases, together -
From lines
29to50, results are identical to those above, but the outer double-quotes, containing fields, are also marked !
In this text, it’s very easy to move from one error’s zone to an other one :
-
Use the
F2and theShift + F2shortcuts to move from one erroneous record to the next or previous one -
Use the
Ctrl + 0andCtrl + Shift + 0shortcuts, on the main keyboard, to move from one erroneous field to the next or previous one
You’ll remark, that I haven’t spoken yet, about a method to isolate all the erroneous fields, one per line. Indeed, @texaskcfan, I would like, first, to get your feeling about keeping records as they are ( excepted for the temporary field delimiter change ! ) and simply navigating between all error’s zones, with the shortcuts mentioned above !
Best Regards,
guy038
- MARK
-
@guy038 This solution is perfect and returns all the errors I am looking for. Thank you!
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login