Basic Language and Folding Questions
-
Hi All,
First post here - I have scoured the internet, and forums for several hours but can’t seem to find resources on some basic things. Apologies if these answers exist somewhere here already. I do have a specific problem I’d like to solve - but some general resources would be helpful. I found a huge thread on folding problems, but still would like to know the answer to #1.- Is there documentation of existing settings for each languages (specifically interested in code folding settings)?
For example, I would like to know what are the built-in code folding keywords for SQL language. Right now, I can just scour through my code and see where it folding occurs and extract some of the characters/words, but a list would be great and could be the simplest solution to my problem. In case it helps others, here is what i’ve learned from trial and error/observation:
Keywords / characters to “Open”:
begin
case
(
if then
/*Keywords / characters to “Close”:
end
)
*/Is there a complete list somewhere?
-
Can you export a language (SQL in my case) so that I can make custom UDL? - I did read somewhere they are quite different things so this is not possible.
-
Specifically, I want to add a custom folding character or word, while staying within the existing SQL language settings built into np++. I dont want to create a UDL for SQL from scratch - is there a simple solution? As per #2 above, I thought i might be able to export and edit SQL settings or xml? but no luck so far.
Thank you in advance for your help.
-
@David-Lin said in Basic Language and Folding Questions:
- Is there documentation of existing settings for each languages (specifically interested in code folding settings)?
Is there a complete list somewhere?
Not that I know of. Each of the built-in syntax highlighters has its own source code, and they might have proprietary ways of deciding where to fold
- Can you export a language (SQL in my case) so that I can make custom UDL? - I did read somewhere they are quite different things so this is not possible.
Nope. Completely different beast, implemented in very different ways.
- Specifically, I want to add a custom folding character or word, while staying within the existing SQL language settings built into np++. I dont want to create a UDL for SQL from scratch - is there a simple solution? As per #2 above, I thought i might be able to export and edit SQL settings or xml? but no luck so far.
No, sorry, from the UDL side, you would be starting from scratch (or you could see if there’s a pre-existing custom UDL for SQL (maybe in the UDL Collection, though a quick glance through the list doesn’t have SQL jump out at me).
Another option for using the built-in lexer: if you were willing to use the PythonScript or similar plugin, I believe that you can influence code-folding from PythonScript. If my belief is correct, then a custom-folding script could be written that would add more folding points depending on what language is selected, similar in concept to the way that @Ekopalypse adds custom highlighting to an existing lexer. I actually thought that there was maybe another recent conversation asking for custom folding where I suggested this, but I don’t remember for sure (and definitely don’t know if any of the PythonScript experts ever looked into it and provided hints or sample code for how it was done). You can search the forum, or if someone else remembers, they will hopefully reply.
- Is there documentation of existing settings for each languages (specifically interested in code folding settings)?
-
@PeterJones
I’m not sure if this can be done so easily, as different lexers use different folding strategies.
Basically, a lexer puts a mask on a line and if the next line has a higher value than the previous one, scinitilla adds the fold point.
But to be honest - I haven’t dug enough to be 100% sure.
I’ll see what I can get out of it. -
No, I don’t see a reasonable way to do this, mainly because
a lexer will eventually overwrite what a python script did. -
Hmm maybe I’m wrong - the python script is always called after the lexer, so it’s just a matter of figuring out how the lexer does it in the first place.
-
@Ekopalypse said in Basic Language and Folding Questions:
a lexer will eventually overwrite what a python script did.
Oh, right. I hadn’t thought about that implication, since the lexer is constantly re-parsing as things change…
Sorry @David-Lin , as of now, it doesn’t look like adding new folding to a lexer is possible.
While I was typing, @Ekopalypse added,
Hmm maybe I’m wrong
Well, that gives a glimmer of hope, anyway.
@David-Lin , the other long-term possibility might be to put in a request with the Scintilla project, because the lexers are inherited from the Scintilla IP. But then they would have to decide to add the folding to the SQL lexer (assuming that the new folding was generic enough that other people would want folding there, too – and not just something specific to your unique circumstances) and release a new Scintilla… and after that, you could start lobbying the Notepad++ developers to update Scintilla – but they rarely do that (it can go years between Scintilla updates in Notepad++).
Of course, if @Ekopalypse ever gets the right Round Tuit™, it may become easier for people to decide to write their own lexers, so that we are not beholden to the limited set that Scintilla includes or the limited syntax for UDL.
-
There is already a file HowToCreateAScintillaLexer.txt on my computer :-)
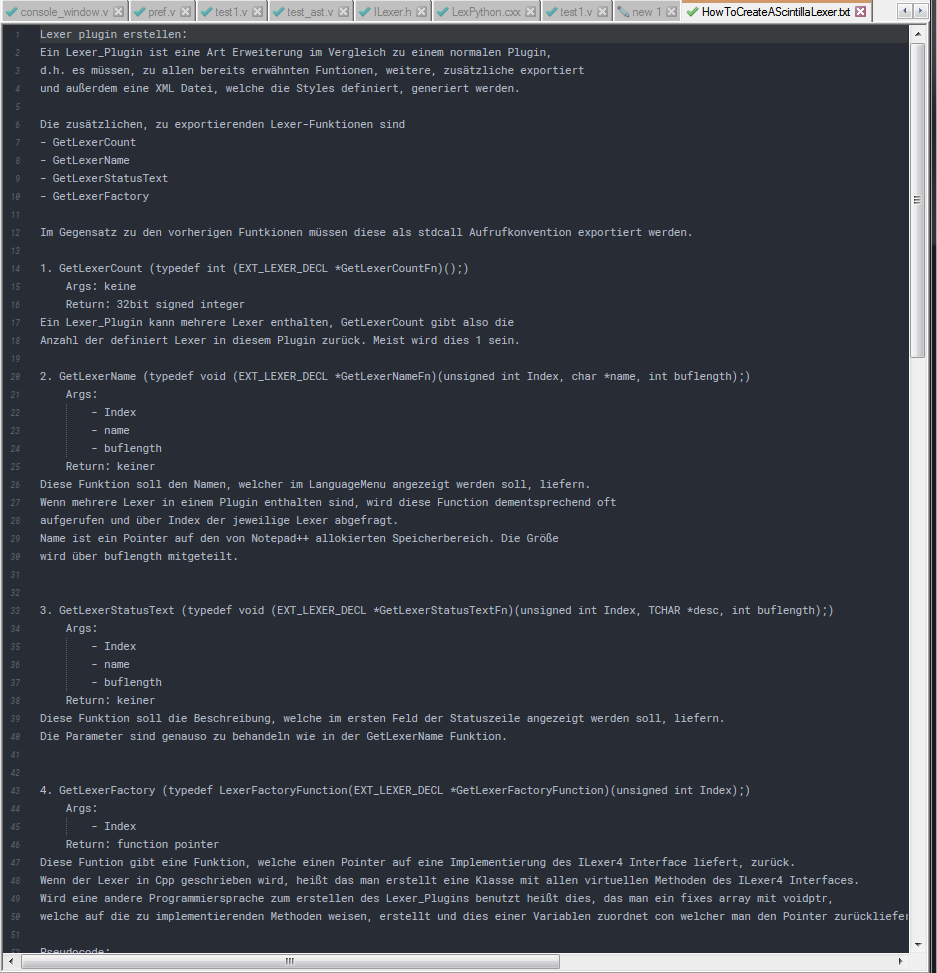
-
@PeterJones and @Ekopalypse thanks for the answers!
From a basic user’s perspective, it is very helpful to know that it is complicated and not easily done.If it’s proprietary as you say/believe - it is unfortunate that there is no way to get into the code the get a list of the folding words and characters. Especially since, from my perspective, nesting /folding of code across all languages isn’t a property unique to a language the way keywords and specific functions are.
While for some languages, there are very clear aspects of the coding that make many elements of nesting super obvious like in xml…
At least in my case, for SQL it is just a guessing game of what the developers decided will make the code fold.I’m sure this may have been discussed to death, but maybe indent-based code folding as an option could help. Do you know if there is any simple solution to do this?
-
@David-Lin said in Basic Language and Folding Questions:
maybe indent-based code folding as an option could help
I know the Python language lexer uses indent-based folding. But once again, that’s not transferrable to any other arbitrary lexer, and the UDL does not implement indent-based folding.
Especially since, from my perspective, nesting /folding of code across all languages isn’t a property unique to a language the way keywords and specific functions are.
From my perspective, it very much is language dependent. In Python, indenting is the only way of indicating blocks; in Perl, indentation only matters for the human reader, and blocks are defined by {}. In other languages, there are keywords like BEGIN/END or FOR/NEXT or IF/ELSE IF/ELSE/ENDIF which will define levels. Each lexer only codes in the level-determining code necessary for its language, because each lexer is completely separate. (And, once again, that’s not something that’s likely to change in Notepad++, because Notepad++ just passes along the lexers that were released with Scintilla.)
-
The source code is publicly available and the folding function
is this one. -
@Ekopalypse said in Basic Language and Folding Questions:
The source code is publicly available and the folding function
is this one.Great! Thank you!
-
@PeterJones said in Basic Language and Folding Questions:
@David-Lin said in Basic Language and Folding Questions:
maybe indent-based code folding as an option could help
I know the Python language lexer uses indent-based folding. But once again, that’s not transferrable to any other arbitrary lexer, and the UDL does not implement indent-based folding.
Especially since, from my perspective, nesting /folding of code across all languages isn’t a property unique to a language the way keywords and specific functions are.
From my perspective, it very much is language dependent. In Python, indenting is the only way of indicating blocks; in Perl, indentation only matters for the human reader, and blocks are defined by {}. In other languages, there are keywords like BEGIN/END or FOR/NEXT or IF/ELSE IF/ELSE/ENDIF which will define levels. Each lexer only codes in the level-determining code necessary for its language, because each lexer is completely separate. (And, once again, that’s not something that’s likely to change in Notepad++, because Notepad++ just passes along the lexers that were released with Scintilla.)
Got it. thanks for the explanation - now i understand why my use case in SQL is different than the intent of the built-in code folding. For me, there are not generally large blocks of code between “level-determining code necessary for its language”, because in my use for preparing data tables, there is little purpose to long nested statements or loops, just moving around and rearranging data for other programs to eventually access and do analysis looping etc… occasionally there is a very long nested query. Procedures that might involve longer segments of code within loops are quite painful in SQL.
For my use, I am separating large sections of code into my subjective segments that I would like to see nested, but these are not exactly “necessary” for the language.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login