How to mark partially duplicated lines
-
Hello everybody, as the title says I’m trying to mark lines that has partially duplicated chars, an example.
File looks likes this:STEAM_0:0:76199888 3886#0
STEAM_0:1:238584168 5878#0
STEAM_0:0:456152639 9007#0
STEAM_0:0:158473218 13279#0
STEAM_0:0:192469843 51090#0
STEAM_0:0:55552598 50704#0
STEAM_0:0:86486664 6216#0
STEAM_0:0:36994546 5070#0
STEAM_0:0:535776954 38211#0
STEAM_0:0:76199888 3886#0
STEAM_0:1:238584168 5878#0
STEAM_0:0:456152639 9007#0
STEAM_0:0:158473218 13279#0
STEAM_0:0:192469843 51090#0
STEAM_0:0:55552598 50704#0
STEAM_0:0:86486664 646#0I want to mark duplicated STEAMID’s then ignore the numbers after ( numbers#0), how I can achieve this?
-
Hi @Cadaver182,
If I correctly understood the issue, then it will be fairly easy to get the desired outcome if you previously sort the lines.
Then apply the following regex:
Mark: (?-s)(([^ ]+?) .*\R)\K\2(?=.*\R)to highligth duplicates
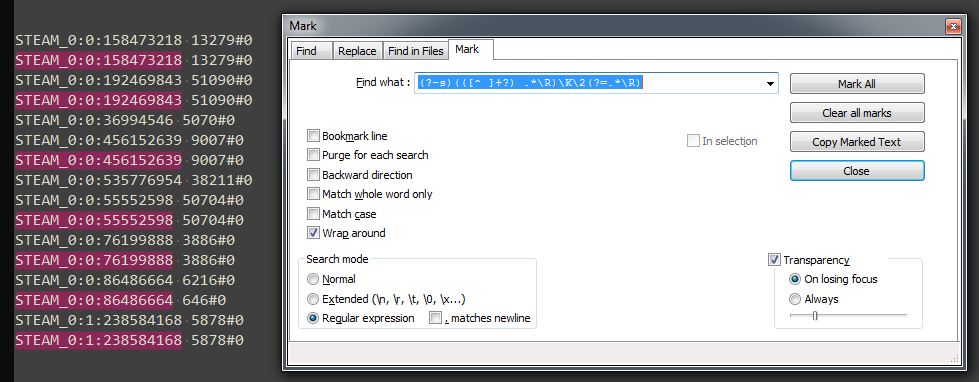
Take care and have fun!
-
It might have helped to actually show some duplicates that you were trying to mark in your sample data!
Nice solution.
Is it possible to extend it such that ALL duplicates would be marked?
Example:STEAM_0:0:55552598 50704#0 STEAM_0:0:55552598 50704#0 STEAM_0:0:55552598 50704#0The second AND third lines of the above should be marked.
-
@Alan-Kilborn said in How to mark partially duplicated lines:
Is it possible to extend it such that ALL duplicates would be marked?
Not at first sight, but let me try a bit more.
Cheers
-
If instead of highlighting duplicates, bookmarking them is good enough, then I have something for you:
Mark: (?-s)([^ ]+?)( .*\R)\K.(?=\1 .*\R)+On the downside, it will highligth the first char of a duplicate line, as follows:
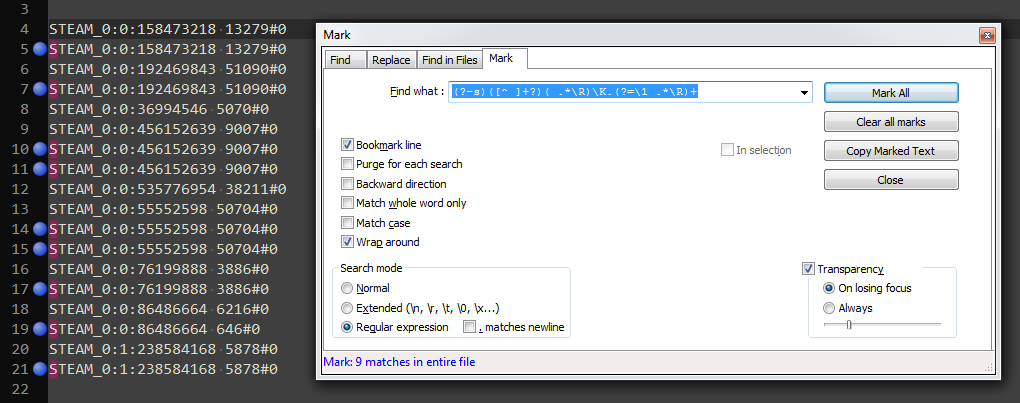
Cheers -
Hello, @cadaver182, @alan-kilborn and All,
I assumed several hypotheses :
-
An alphabetically sort (
Edit > Line Operations > Sort lines Lexicographically Ascendinghas been performed on data -
The areas to be highlighted and/or marked will be the entire lines, matching the searched criterion
-
The numbers, candidate to verify if possible duplication, on next lines, are the consecutive range of digits after the last colon
The last hypothesis means the searched area, for possible duplication, may be expressed by the regex
:(\d{2,})\x20, with the digits stored in group1, which will be used further on !
Then, the following regexes should mark / bookmark a specific subset of all the lines :
-
(A)
(?-s)^.+(:\d{2,}\x20).+\R(?=(?s).+\1)Mark all the duplicate lines, except for the last one -
(B)
(?-s)^.+(:\d{2,}\x20).+\R(?=(?s).+\1)(*SKIP)(*F)|^.+(?1).+\RMark unique lines and1duplicate ( the last sorted ) -
(C)
(?-s)^.+(:\d{2,}\x20).+\R(?:.+\1.+\R)*\K.+\1.+\RMark1duplicate line, only ( the last sorted ) -
(D)
(?-s)^.+(:\d{2,}\x20).+\R(?:.+\1.+\R)+Mark all the duplicate lines -
(E)
(?-s)^.+(:\d{2,}\x20).+\R(?:.+\1.+\R)+(*SKIP)(*F)|^.+(?1).+\RMark all the unique lines
Note that regexes (A) and (B), as well as the regexes (D) and (E), define exclusive results !
Just test these five regexes against this sample text, already sorted :
STEAM_0:0:158473218 1111111 STEAM_0:0:192469843 1111111 STEAM_0:0:192469843 2222222 STEAM_0:0:192469843 3333333 STEAM_0:0:192469843 4444444 STEAM_0:0:207654321 1111111 STEAM_0:1:238584168 1111111 STEAM_0:1:238584168 2222222 STEAM_0:1:523456789 1111111 STEAM_0:1:712345678 1111111 STEAM_0:1:712345678 2222222 STEAM_0:1:712345678 3333333 STEAM_0:2:823658921 1111111 STEAM_0:2:891234567 1111111 STEAM_0:3:123456789 1111111 STEAM_0:3:123456789 2222222 STEAM_0:3:123456789 3333333 STEAM_0:3:123456789 4444444 STEAM_0:3:123456789 5555555Best Regards,
guy038
I’ll try, very soon, to build up some generic regexes of the regexes (
B) to (E) which cover all the possible cases ;-)) -
-
@guy038 said in How to mark partially duplicated lines:
I’ll try, very soon, to build up some generic regexes of the regexes (B) to (E) which cover all the possible cases ;-))
I like that idea. :-)
I assumed several hypotheses :
An alphabetically sort ( Edit > Line Operations > Sort lines Lexicographically Ascending has been performed on data
We don’t know that this is valid for the OP’s problem. :-(
-
Hello guys, thanks for the reply, all solutions help me somehow, thanks a lot!
-
Hi, @cadaver182, @alan-kilborn and All,
As promised, here are the corresponding generic regexes to deal with duplicate and/or unique lines of a list :
-
(A)
(?-s)^.*(KR).*\R(?=(?s).*\1)Mark all the duplicates lines, except for the last one -
(B)
(?-s)^.*(KR).*\R(?=(?s).*\1)(*SKIP)(*F)|^.*(?1).*\RMark uniques lines and1duplicate ( the last sorted ) -
(C)
(?-s)^.*(KR).*\R(?:.*\1.*\R)*\K.*\1.*\RMark1duplicate line, only ( the last sorted ) -
(D)
(?-s)^.*(KR).*\R(?:.*\1.*\R)+Mark all the duplicate lines -
(E)
(?-s)^.*(KR).*\R(?:.*\1.*\R)+(*SKIP)(*F)|^.*(?1).*\RMark all the unique lines
Notes :
-
As said, previously, only regexes
BtoEare really useful ! -
The KR is the regex to get the user
key, i.e. the range of characters which must to be compared, in all lines, to determine duplicate and unique lines
Important :
-
The list, where to get unique or duplicate lines, must end with a
pure blankline ! -
Of course, adding or subtracting only
1char to/from thekeymay change the status of the lines. For instance, given this text :
ABCDE 12345 abcde ABCDE 12346 abcde ABCDE 12359 abcde ABCDE 12398 abcde-
- If we suppose the
keyto be the first three digits, there are only4duplicate lines
- If we suppose the
-
- If we suppose the
keyto be the first four digits, there are2duplicate lines and2unique lines
- If we suppose the
-
- If we suppose the
keyto be the number, there are only4unique lines
- If we suppose the
Last point : To say that there are
nduplicate lines is an abuse of language! In fact, it represents1line with a certain key ANDn-1other lines, located just after it, having that same key !
Let give an example, mainly inspired from the OP’s text. So, given this list, still not sorted :
STEAM_0:1:238584168 2222222 STEAM_0:3:123456789 3333333 STEAM_0:3:123456789 4444444 STEAM_0:1:238584168 1111111 STEAM_0:0:158473218 1111111 STEAM_0:0:192469843 1111111 STEAM_0:0:192469843 2222222 STEAM_0:1:712345678 3333333 STEAM_0:3:123456789 1111111 STEAM_0:0:192469843 3333333 STEAM_0:0:192469843 4444444 STEAM_0:0:207654321 1111111 STEAM_0:3:123456789 5555555 STEAM_0:3:123456789 2222222 STEAM_0:1:523456789 1111111 STEAM_0:1:712345678 2222222 STEAM_0:2:823658921 1111111 STEAM_0:2:891234567 1111111 STEAM_0:1:712345678 1111111Let’s imagine that we want the key to be the range of nine digits, after the last colon of each line So, first, we need to sort this text, considering these digits and all the remaining characters.
If your N++ version is the
v7.9or later, here is the way to proceed :-
Place the caret in front of the
2digit of the first line, after the last colon -
Hold down the
AltandShiftkeys and hit, repeatedly, on theDownarrow, several times -
Stop when the vertical line is in front of the
7digit of the last line, after the last colon -
Now, perform the usual sort (
Edit > Line Operations > Sort Lines Lexicographically Ascending)
You should get this text :
STEAM_0:3:123456789 1111111 STEAM_0:3:123456789 2222222 STEAM_0:3:123456789 3333333 STEAM_0:3:123456789 4444444 STEAM_0:3:123456789 5555555 STEAM_0:0:158473218 1111111 STEAM_0:0:192469843 1111111 STEAM_0:0:192469843 2222222 STEAM_0:0:192469843 3333333 STEAM_0:0:192469843 4444444 STEAM_0:0:207654321 1111111 STEAM_0:1:238584168 1111111 STEAM_0:1:238584168 2222222 STEAM_0:1:523456789 1111111 STEAM_0:1:712345678 1111111 STEAM_0:1:712345678 2222222 STEAM_0:1:712345678 3333333 STEAM_0:2:823658921 1111111 STEAM_0:2:891234567 1111111As expected, only text, after the last colon, is correctly sorted
Now, we need to build the Key regex ( the KR notation, in the generic regexes, above ). Several constructions are possible. Here are two of them, with the regex from
AtoE# With match of the KEY, between TWO LIMITS => KR = :\d{2,}\x20 ( At LEAST, TWO digits, between a COLON and a SPACE char ) Regex A (?-s)^.*(:\d{2,}\x20).*\R(?=(?s).*\1) Mark ALL the DUPLICATE lines, except for the LAST one Regex B (?-s)^.*(:\d{2,}\x20).*\R(?=(?s).*\1)(*SKIP)(*F)|^.*(?1).*\R Mark UNIQUE lines and 1 DUPLICATE ( the LAST sorted ) Regex C (?-s)^.*(:\d{2,}\x20).*\R(?:.*\1.*\R)*\K.*\1.*\R Mark 1 DUPLICATE line, only ( the LAST sorted ) Regex D (?-s)^.*(:\d{2,}\x20).*\R(?:.*\1.*\R)+ Mark ALL the DUPLICATE lines Regex E (?-s)^.*(:\d{2,}\x20).*\R(?:.*\1.*\R)+(*SKIP)(*F)|^.*(?1).*\R Mark ALL the UNIQUE lines # With match of the ABSOLUTE location of the KEY => KR = \d{9} ( NINE digits AFTER the 10 FIRST characters ) Regex A (?-s)^.{10}(\d{9}).*\R(?=(?s).*\1) Mark ALL the DUPLICATE lines, except for the LAST one Regex B (?-s)^.{10}(\d{9}).*\R(?=(?s).*\1)(*SKIP)(*F)|^.*(?1).*\R Mark UNIQUE lines and 1 DUPLICATE ( the LAST sorted ) Regex C (?-s)^.{10}(\d{9}).*\R(?:.*\1.*\R)*\K.*\1.*\R Mark 1 DUPLICATE line, only ( the LAST sorted ) Regex D (?-s)^.{10}(\d{9}).*\R(?:.*\1.*\R)+ Mark ALL the DUPLICATE lines Regex E (?-s)^.{10}(\d{9}).*\R(?:.*\1.*\R)+(*SKIP)(*F)|^.*(?1).*\R Mark ALL the UNIQUE lines
Sometimes, you will feel the need for a more elaborate
key, consisting of several non-contiguous areasThe trick is to replace each line by these fields, in a specific order, at the beginning of the line ( similar to a virtual key ) and add the contents of the line itself, after a tabulation character ( or other ) as a separator !
Let’s give an example of that technique. So, we start again from the non-sorted list :
STEAM_0:1:238584168 2222222 STEAM_0:3:123456789 3333333 STEAM_0:3:123456789 4444444 STEAM_0:1:238584168 1111111 STEAM_0:0:158473218 1111111 STEAM_0:0:192469843 1111111 STEAM_0:0:192469843 2222222 STEAM_0:1:712345678 3333333 STEAM_0:3:123456789 1111111 STEAM_0:0:192469843 3333333 STEAM_0:0:192469843 4444444 STEAM_0:0:207654321 1111111 STEAM_0:3:123456789 5555555 STEAM_0:3:123456789 2222222 STEAM_0:1:523456789 1111111 STEAM_0:1:712345678 2222222 STEAM_0:2:823658921 1111111 STEAM_0:2:891234567 1111111 STEAM_0:1:712345678 1111111And let’s decide that our key is the virtual key, composed with :
-
The fifth digit, of the number, after the colon (
1stkey ) -
The last two digits of the number, after the colon (
2ndkey ) -
The first three digits of the number, after the colon (
3rdkey )
After a quick examination, one of the suitable regexes S/R is :
SEARCH
(?-s)^.{10}(\d{3}).(\d).{2}(\d{2})REPLACE
\2\3\1\t$0After replacement, we get :
868238 STEAM_0:1:238584168 2222222 589123 STEAM_0:3:123456789 3333333 589123 STEAM_0:3:123456789 4444444 868238 STEAM_0:1:238584168 1111111 718158 STEAM_0:0:158473218 1111111 643192 STEAM_0:0:192469843 1111111 643192 STEAM_0:0:192469843 2222222 478712 STEAM_0:1:712345678 3333333 589123 STEAM_0:3:123456789 1111111 643192 STEAM_0:0:192469843 3333333 643192 STEAM_0:0:192469843 4444444 521207 STEAM_0:0:207654321 1111111 589123 STEAM_0:3:123456789 5555555 589123 STEAM_0:3:123456789 2222222 589523 STEAM_0:1:523456789 1111111 478712 STEAM_0:1:712345678 2222222 521823 STEAM_0:2:823658921 1111111 367891 STEAM_0:2:891234567 1111111 478712 STEAM_0:1:712345678 1111111Now, we simply select that text and perform the usual sort
Edit > Line Operations > Sort Lines Lexicographically Ascending, which gives this sorted list :367891 STEAM_0:2:891234567 1111111 478712 STEAM_0:1:712345678 1111111 478712 STEAM_0:1:712345678 2222222 478712 STEAM_0:1:712345678 3333333 521207 STEAM_0:0:207654321 1111111 521823 STEAM_0:2:823658921 1111111 589123 STEAM_0:3:123456789 1111111 589123 STEAM_0:3:123456789 2222222 589123 STEAM_0:3:123456789 3333333 589123 STEAM_0:3:123456789 4444444 589123 STEAM_0:3:123456789 5555555 589523 STEAM_0:1:523456789 1111111 643192 STEAM_0:0:192469843 1111111 643192 STEAM_0:0:192469843 2222222 643192 STEAM_0:0:192469843 3333333 643192 STEAM_0:0:192469843 4444444 718158 STEAM_0:0:158473218 1111111 868238 STEAM_0:1:238584168 1111111 868238 STEAM_0:1:238584168 2222222This time, the Key regex ( KR notation ) is easy to guess :
\d{6}and, as these digits are close to the start of line, we do not need the.*part, located after the^symbol. Thus, the regexesAtoEbecome :# With match of the ABSOLUTE location of the KEY => KR = \d{6} ( SIX digits AFTER the BEGINNING of each line ) Regex A (?-s)^(\d{6}).*\R(?=(?s).*\1) Mark ALL the DUPLICATE lines, except for the LAST one Regex B (?-s)^(\d{6}).*\R(?=(?s).*\1)(*SKIP)(*F)|^.*(?1).*\R Mark UNIQUE lines and 1 DUPLICATE ( the LAST sorted ) Regex C (?-s)^(\d{6}).*\R(?:.*\1.*\R)*\K.*\1.*\R Mark 1 DUPLICATE line, only ( the LAST sorted ) Regex D (?-s)^(\d{6}).*\R(?:.*\1.*\R)+ Mark ALL the DUPLICATE lines Regex E (?-s)^(\d{6}).*\R(?:.*\1.*\R)+(*SKIP)(*F)|^.*(?1).*\R Mark ALL the UNIQUE linesBeware : when testing these regexes against the sorted list, right above, you must keep your attention to the first six chars of each line ( the
key) to determine when lines are unique or duplicate ;-))Using the
Markfeature allows you to bookmark one or several subset(s) of lines, which are easy to copy/cut and paste elsewhere or to delete !Once you finished to delete some subsets of your file, it will probably remain some lines, with this temporary virtual key ! To get rid of it, it’s elementary, use the regex S/R :
SEARCH
^.+\tREPLACE
Leave EMPTYBest Regards,
guy038
P.S. : I just realize that, if you use the
Search > Bookmark > Inverse Bookmarkoption, some the generic regexes are not essential ! -
-
Hello,@Cadaver182
Please follow these steps, To How to mark partially duplicated lines.Step 1: Ctrl+H
Step 2: Find what: ^([^:]+:).+\R(?:.*?\1.+(?:\R|$))+I hope this information will be useful to you.
Thank you. -
Когда уже сделают плагин к N++ который обращается со строками во вьювах как со строками SQL таблички такой структуры.
row_id - номер строки
data - текст строки.
Тогда можно простым Group by вычленить все уникальные строки и сделать множество других полезных операций.
Я смотрел на SQLite движек, там такая возможность есть.
Но к сожалению времени нет. :( -
Hello, @cadaver182, @alan-kilborn and All,
In the particular case where the
keyis, simply, all the line contents, the Key Regex is just.+and the five regexes, from regexAto regexE, can be, finally, simplified as below :-
(A)
(?-s)^(.+)\R(?=\1\R)Mark all the duplicate lines, except for the last one -
(B)
(?-s)^(.+)\R(?=\1\R)(*SKIP)(*F)|^.+\RMark unique lines and1duplicate ( the last sorted ) -
(C)
(?-s)^(.+)\R(?:\1\R)*\K\1\RMark1duplicate line, only ( the last sorted ) -
(D)
(?-s)^(.+)\R(?:\1\R)+Mark all the duplicate lines -
(E)
(?-s)^(.+)\R(?:\1\R)+(*SKIP)(*F)|^.+\RMark all the unique lines
IMPORTANT :
-
These
5regexes must be performed against a previously sorted list ! -
That list must also end with a
pure blankline
Best regards,
guy038
-
-
Hi
according to your useful topic,
I want to know how can i mark lines that have duplicate digit in 8digit number. e.g:
98765439
87654328
54321974
.
.
. -
@Faraz-Ketabi said in How to mark partially duplicated lines:
according to your useful topic,
I want to know how can i mark lines that have duplicate digit in 8digit number.
98765439
87654328
54321974It’s a completely separate question; the original wanted to mark across multiple lines if the multiple lines has some common substring. You want to mark a single line if that single line contains more than one of the same digit. The regex won’t look anything alike for those two.
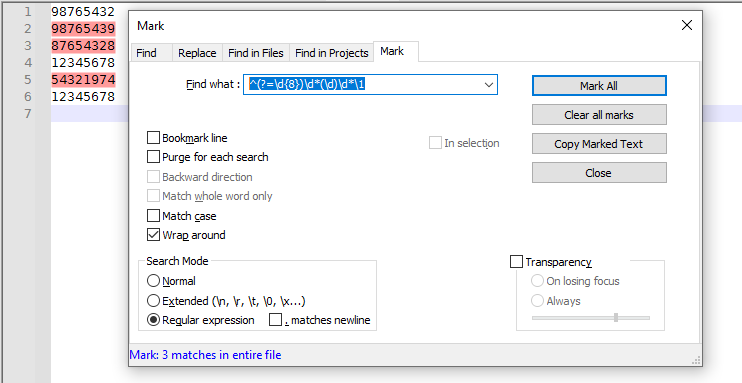
FIND =
^(?=\d{8})\d*(\d)\d*\1
SEARCH MODE = regular expression^means anchor at beginning of the line. Don’t use that if your numbers don’t use the^(?=\d{8})requires that the next 8 characters are digits, but doesn’t “match” any of them yet. This is the easy way to say that the next sequence must be inside of an 8-digit number\d*means zero-or-more digits(\d)means put the next digit in memory group#1\d*means another zero-or-more digits\1matches a second copy of the character(s) in group#1 – so this matches the repeated digit
-—
Useful References
-
@Faraz-Ketabi
Thanks a lot.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login